Wie Sie KI-Chatbots testen
Erfahren Sie umfassende Teststrategien für KI-Chatbots, einschließlich funktionaler, leistungsbezogener, sicherheitsrelevanter und benutzerorientierter Tests. E...
11 Min. Lesezeit
Erfahren Sie umfassende Methoden zur Messung der Genauigkeit von KI-Helpdesk-Chatbots im Jahr 2025. Entdecken Sie Präzision, Recall, F1-Scores, Nutzerzufriedenheitsmetriken und fortschrittliche Bewertungstechniken mit FlowHunt.
Messen Sie die Genauigkeit eines KI-Helpdesk-Chatbots mit mehreren Metriken, einschließlich Präzisions- und Recall-Berechnungen, Konfusionsmatrizen, Nutzerzufriedenheitswerten, Lösungsraten und fortschrittlichen LLM-basierten Bewertungsmethoden. FlowHunt bietet umfassende Tools für die automatisierte Genauigkeitsbewertung und Leistungsüberwachung.
Die Messung der Genauigkeit eines KI-Helpdesk-Chatbots ist entscheidend, um sicherzustellen, dass er zuverlässige und hilfreiche Antworten auf Kundenanfragen liefert. Im Gegensatz zu einfachen Klassifizierungsaufgaben umfasst die Genauigkeit eines Chatbots mehrere Dimensionen, die gemeinsam bewertet werden müssen, um ein vollständiges Bild der Leistung zu erhalten. Der Prozess beinhaltet die Analyse, wie gut der Chatbot Benutzeranfragen versteht, korrekte Informationen bereitstellt, Probleme effektiv löst und die Nutzerzufriedenheit während der gesamten Interaktion aufrechterhält. Eine umfassende Strategie zur Genauigkeitsmessung kombiniert quantitative Metriken mit qualitativem Feedback, um Stärken und Verbesserungsbereiche zu identifizieren.
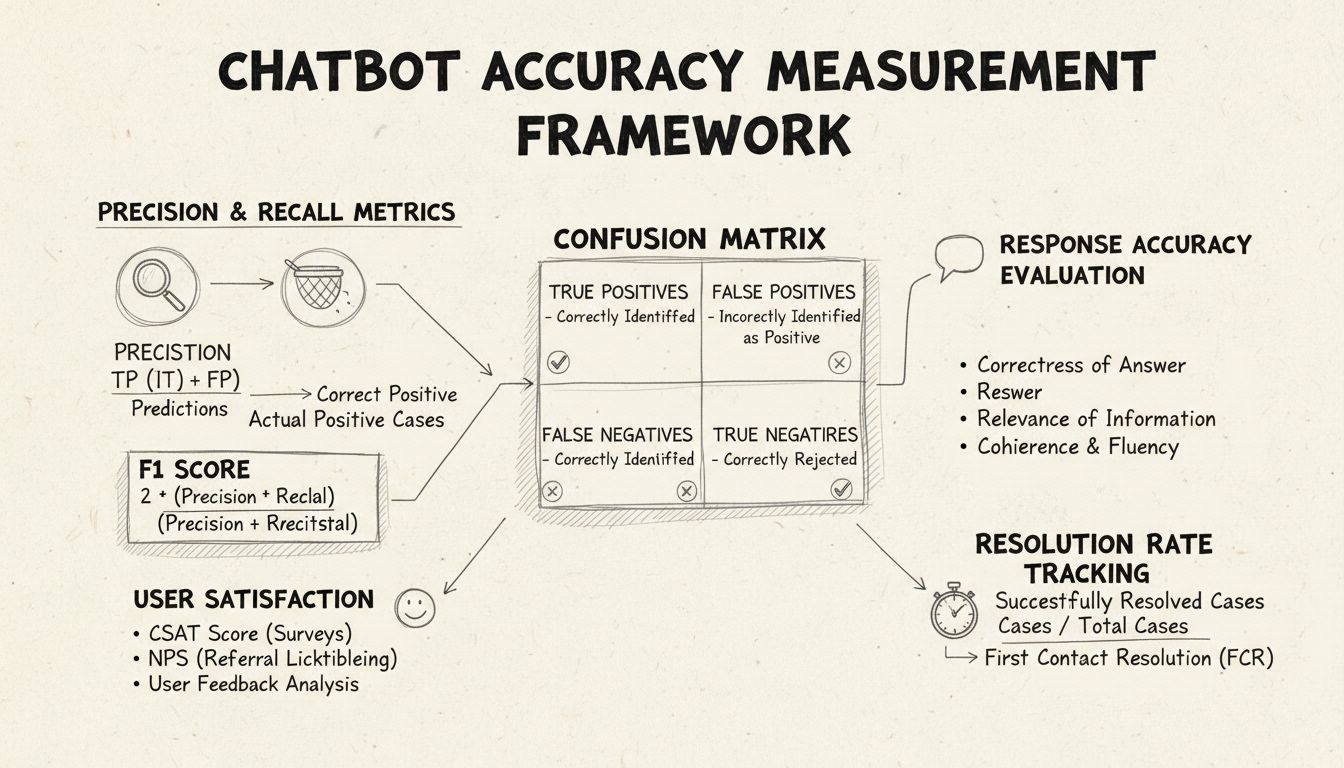
Präzision und Recall sind grundlegende Metriken, die aus der Konfusionsmatrix abgeleitet werden und verschiedene Aspekte der Chatbot-Leistung messen. Präzision gibt den Anteil der korrekten Antworten an allen vom Chatbot gegebenen Antworten an. Die Formel lautet: Präzision = Wahre Positive / (Wahre Positive + Falsche Positive). Diese Metrik beantwortet die Frage: „Wie oft ist die Antwort des Chatbots korrekt, wenn er eine Antwort gibt?“ Ein hoher Präzisionswert zeigt, dass der Chatbot selten falsche Informationen gibt – das ist für das Vertrauen der Nutzer im Helpdesk entscheidend.
Recall, auch Sensitivität genannt, misst den Anteil der korrekten Antworten an allen Antworten, die der Chatbot hätte geben sollen. Die Formel lautet: Recall = Wahre Positive / (Wahre Positive + Falsche Negative). Diese Metrik zeigt, ob der Chatbot alle legitimen Kundenanliegen erfolgreich erkennt und beantwortet. Im Helpdesk-Kontext sorgt ein hoher Recall dafür, dass Kunden Unterstützung für ihre Probleme erhalten, anstatt zu hören, dass der Chatbot nicht helfen kann, obwohl er es könnte. Zwischen Präzision und Recall besteht ein natürlicher Zielkonflikt: Die Optimierung des einen reduziert oft den anderen. Daher ist ein sorgfältiges Gleichgewicht entsprechend Ihrer Geschäftsziele erforderlich.
Der F1-Score bietet eine einzige Metrik, die sowohl Präzision als auch Recall ausgleicht. Er wird als harmonisches Mittel berechnet: F1 = 2 × (Präzision × Recall) / (Präzision + Recall). Diese Metrik ist besonders wertvoll, wenn Sie einen einheitlichen Leistungsindikator brauchen oder mit unausgeglichenen Datensätzen arbeiten, bei denen eine Klasse deutlich überwiegt. Wenn Ihr Chatbot beispielsweise 1.000 Routineanfragen, aber nur 50 komplexe Eskalationen bearbeitet, verhindert der F1-Score, dass die Metrik von der Mehrheitsklasse verzerrt wird. Der F1-Score reicht von 0 bis 1, wobei 1 perfekte Präzision und Recall bedeutet – so ist die Gesamtleistung für Stakeholder auf einen Blick verständlich.
Die Konfusionsmatrix ist ein grundlegendes Werkzeug, das die Chatbot-Leistung in vier Kategorien unterteilt: Wahre Positive (richtige Antworten auf gültige Anfragen), Wahre Negative (korrektes Ablehnen von fachfremden Fragen), Falsche Positive (falsche Antworten) und Falsche Negative (verpasste Hilfsmöglichkeiten). Diese Matrix zeigt spezifische Muster bei Chatbot-Fehlern und ermöglicht gezielte Verbesserungen. Zeigt die Matrix beispielsweise viele falsche Negative bei Rechnungsanfragen, können Sie erkennen, dass dem Trainingsdatensatz des Chatbots genügend Beispiele aus diesem Bereich fehlen und dieser Bereich verbessert werden muss.
| Metrik | Definition | Berechnung | Geschäftlicher Einfluss |
|---|---|---|---|
| Wahre Positive (TP) | Richtige Antworten auf gültige Anfragen | Direkt gezählt | Baut Kundenvertrauen auf |
| Wahre Negative (TN) | Korrektes Ablehnen fachfremder Fragen | Direkt gezählt | Verhindert Fehlinformationen |
| Falsche Positive (FP) | Falsche gegebene Antworten | Direkt gezählt | Schädigt Glaubwürdigkeit |
| Falsche Negative (FN) | Verpasste Hilfsmöglichkeiten | Direkt gezählt | Verringert Zufriedenheit |
| Präzision | Qualität der positiven Vorhersagen | TP / (TP + FP) | Zuverlässigkeitsmetrik |
| Recall | Abdeckung der tatsächlichen Positiven | TP / (TP + FN) | Vollständigkeitsmetrik |
| Genauigkeit | Gesamtkorrektheit | (TP + TN) / Gesamt | Allgemeine Leistung |
Die Antwortgenauigkeit misst, wie oft der Chatbot sachlich korrekte Informationen liefert, die direkt auf die Nutzeranfrage eingehen. Dies geht über reines Pattern Matching hinaus und bewertet, ob der Inhalt korrekt, aktuell und für den Kontext angemessen ist. Bei manuellen Prüfungen bewerten menschliche Prüfer eine Zufallsstichprobe von Gesprächen und vergleichen die Chatbot-Antworten mit einer vordefinierten Wissensdatenbank korrekter Antworten. Automatisierte Vergleichsmethoden können mit NLP-Techniken Antworten mit gespeicherten Referenzantworten abgleichen; diese müssen jedoch sorgfältig kalibriert werden, um keine falschen Negativen zu erzeugen, wenn der Chatbot korrekte Informationen in abweichender Formulierung gibt.
Die Antwortrelevanz bewertet, ob die Antwort des Chatbots tatsächlich auf die Nutzerfrage eingeht, auch wenn die Antwort nicht perfekt korrekt ist. Dieser Aspekt erfasst Fälle, in denen der Chatbot hilfreiche Informationen liefert, die das Gespräch auf eine Lösung zubewegen, auch wenn es nicht die exakte Antwort ist. NLP-Methoden wie Kosinus-Ähnlichkeit können die semantische Ähnlichkeit zwischen Nutzerfrage und Chatbot-Antwort messen und so einen automatisierten Relevanz-Score liefern. Nutzerfeedback-Mechanismen wie Daumen-hoch-/Daumen-runter-Bewertungen nach jeder Interaktion bieten eine direkte Relevanzbewertung von den wichtigsten Personen – Ihren Kunden. Diese Feedbacksignale sollten kontinuierlich gesammelt und analysiert werden, um Muster zu erkennen, bei welchen Fragetypen der Chatbot gut oder schlecht abschneidet.
Der Kundenzufriedenheitsscore (CSAT) misst die Nutzerzufriedenheit mit Chatbot-Interaktionen über direkte Umfragen, meist per Skala von 1 bis 5 oder einfachen Zufriedenheitsbewertungen. Nach jeder Interaktion werden Nutzer gebeten, ihre Zufriedenheit zu bewerten – so erhalten Sie direktes Feedback darüber, ob der Chatbot die Erwartungen erfüllt hat. CSAT-Werte über 80 % zeigen in der Regel eine starke Leistung, Werte unter 60 % deuten auf erhebliche Probleme hin. Der Vorteil von CSAT ist seine Einfachheit und Direktheit – Nutzer geben explizit an, ob sie zufrieden sind –, aber er kann von Faktoren beeinflusst werden, die über die Chatbot-Genauigkeit hinausgehen, etwa die Komplexität des Falls oder die Nutzererwartungen.
Der Net Promoter Score misst die Wahrscheinlichkeit, mit der Nutzer den Chatbot weiterempfehlen, berechnet durch die Frage „Wie wahrscheinlich ist es, dass Sie diesen Chatbot einem Kollegen weiterempfehlen?“ auf einer Skala von 0 bis 10. Antworten von 9–10 sind Promotoren, 7–8 Passiv, 0–6 Detraktoren. NPS = (Promotoren – Detraktoren) / Gesamtanzahl der Befragten × 100. Diese Metrik korreliert stark mit der langfristigen Kundenbindung und gibt Aufschluss darüber, ob der Chatbot positive Erlebnisse schafft, die Nutzer teilen möchten. Ein NPS über 50 gilt als ausgezeichnet, ein negativer NPS deutet auf ernsthafte Leistungsprobleme hin.
Die Sentiment-Analyse untersucht den emotionalen Ton von Nutzermitteilungen vor und nach der Chatbot-Interaktion, um die Zufriedenheit zu messen. Fortgeschrittene NLP-Techniken klassifizieren Nachrichten als positiv, neutral oder negativ und zeigen so, ob Nutzer im Verlauf des Gesprächs zufriedener oder frustrierter werden. Eine positive Stimmungsverschiebung zeigt, dass der Chatbot Anliegen erfolgreich gelöst hat; negative Verschiebungen deuten darauf hin, dass der Chatbot Nutzer frustriert oder ihre Bedürfnisse nicht erfüllt hat. Diese Metrik erfasst emotionale Dimensionen, die von klassischen Genauigkeitsmetriken übersehen werden, und liefert wertvollen Kontext für die Qualität des Nutzererlebnisses.
Die Erstlösungsquote misst den Prozentsatz der Kundenanliegen, die der Chatbot ohne Weiterleitung an menschliche Agenten löst. Diese Metrik beeinflusst direkt die operative Effizienz und Kundenzufriedenheit; Kunden möchten ihre Anliegen lieber sofort gelöst bekommen, statt weitergeleitet zu werden. FCR-Werte über 70 % zeigen eine starke Chatbot-Leistung; Werte unter 50 % deuten darauf hin, dass der Chatbot nicht ausreichend Wissen oder Fähigkeiten für gängige Anfragen besitzt. Die Nachverfolgung der FCR nach Anliegenkategorie zeigt, welche Probleme der Chatbot gut löst und welche menschliches Eingreifen erfordern – das hilft bei der Verbesserung von Training und Wissensdatenbank.
Die Eskalationsrate misst, wie oft der Chatbot Gespräche an menschliche Agenten weiterleitet; die Fallback-Häufigkeit gibt an, wie oft der Chatbot auf allgemeine Antworten wie „Ich habe das nicht verstanden“ oder „Bitte formulieren Sie Ihre Frage um“ zurückgreift. Hohe Eskalationsraten (über 30 %) zeigen, dass dem Chatbot in vielen Szenarien Wissen oder Sicherheit fehlt; hohe Fallback-Raten deuten auf schwache Intenzerkennung oder unzureichende Trainingsdaten hin. Diese Metriken zeigen gezielt Lücken in den Fähigkeiten des Chatbots auf, die durch Erweiterung der Wissensbasis, erneutes Training oder bessere Spracherkennung behoben werden können.
Die Antwortzeit misst, wie schnell der Chatbot auf Nutzeranfragen reagiert – typischerweise in Millisekunden bis Sekunden. Nutzer erwarten nahezu sofortige Antworten; Verzögerungen von über 3–5 Sekunden beeinträchtigen die Zufriedenheit deutlich. Die Bearbeitungszeit misst die gesamte Dauer vom Kontaktbeginn bis zur Lösung oder Eskalation – das gibt Einblick in die Effizienz des Chatbots. Kürzere Bearbeitungszeiten zeigen, dass der Chatbot Anliegen schnell versteht und löst; längere Zeiten deuten auf mehrfache Rückfragen oder Schwierigkeiten bei komplexen Anfragen hin. Diese Metriken sollten je nach Anliegenkategorie separat verfolgt werden, da komplexe technische Probleme natürlich längere Bearbeitungszeiten benötigen als einfache FAQ-Fragen.
LLM As a Judge ist ein fortschrittlicher Bewertungsansatz, bei dem ein großes Sprachmodell die Qualität der Ausgaben eines anderen KI-Systems beurteilt. Diese Methodik eignet sich besonders, um Chatbot-Antworten gleichzeitig in mehreren Qualitätsdimensionen zu bewerten, wie Genauigkeit, Relevanz, Kohärenz, Sprachfluss, Sicherheit, Vollständigkeit und Tonfall. Studien zeigen, dass LLM-Judges bis zu 85 % Übereinstimmung mit menschlichen Bewertungen erzielen und damit eine skalierbare Alternative zur manuellen Überprüfung sind. Das Verfahren umfasst das Festlegen spezifischer Bewertungskriterien, das Erstellen detaillierter Bewertungs-Prompts mit Beispielen, das Bereitstellen der ursprünglichen Nutzeranfrage und der Chatbot-Antwort für den Judge sowie das Empfangen strukturierter Scores oder detaillierter Rückmeldungen.
Das LLM As a Judge-Verfahren nutzt typischerweise zwei Bewertungsansätze: die Einzelbewertung (Scoring einer Antwort mit oder ohne Referenzantwort) und den Paarvergleich (Vergleich zweier Ausgaben, um die bessere zu ermitteln). Diese Flexibilität erlaubt die Bewertung sowohl absoluter Leistung als auch relativer Verbesserungen beim Testen verschiedener Chatbot-Versionen oder Konfigurationen. Die FlowHunt-Plattform unterstützt LLM As a Judge-Implementierungen durch eine Drag-and-Drop-Oberfläche, Integration führender LLMs wie ChatGPT und Claude sowie ein CLI-Toolkit für fortschrittliche Berichte und automatisierte Bewertungen.
Über die reine Genauigkeitsberechnung hinaus offenbart eine detaillierte Analyse der Konfusionsmatrix spezifische Fehler-Muster des Chatbots. Durch die Untersuchung, welche Fragetypen zu falschen Positiven oder Negativen führen, lassen sich systematische Schwachstellen identifizieren. Zeigt die Matrix beispielsweise, dass Rechnungsfragen häufig fälschlich als technische Support-Anfragen klassifiziert werden, deutet dies auf ein Ungleichgewicht in den Trainingsdaten oder ein Intent-Erkennungsproblem im Rechnungsbereich hin. Separate Konfusionsmatrizen für verschiedene Anliegenkategorien erlauben gezielte Verbesserungen statt allgemeiner Modellnachschulung.
A/B-Tests vergleichen verschiedene Versionen des Chatbots, um festzustellen, welche auf Schlüsselmetriken besser abschneidet. Dies kann unterschiedliche Antwortvorlagen, Wissensdatenbank-Konfigurationen oder Sprachmodelle betreffen. Durch zufällige Zuweisung eines Teils des Traffics zu jeder Version und dem Vergleich von Kennzahlen wie FCR, CSAT und Antwortgenauigkeit treffen Sie datenbasierte Entscheidungen über Verbesserungen. A/B-Tests sollten über einen ausreichend langen Zeitraum laufen, um natürliche Schwankungen im Nutzerverhalten zu erfassen und statistische Signifikanz sicherzustellen.
FlowHunt bietet eine integrierte Plattform zum Erstellen, Bereitstellen und Bewerten von KI-Helpdesk-Chatbots mit fortschrittlichen Genauigkeitsmessungs-Funktionen. Der visuelle Builder ermöglicht auch nicht-technischen Nutzern die Erstellung komplexer Chatbot-Flows, während die KI-Komponenten mit führenden Sprachmodellen wie ChatGPT und Claude integriert sind. Das Bewertungstoolkit von FlowHunt unterstützt die Umsetzung der LLM As a Judge-Methodik, sodass Sie eigene Bewertungskriterien definieren und die Chatbot-Leistung über Ihren gesamten Gesprächsdatenbestand automatisch bewerten können.
Um mit FlowHunt eine umfassende Genauigkeitsmessung umzusetzen, definieren Sie zunächst die Bewertungskriterien entsprechend Ihren Geschäftszielen – ob Sie Genauigkeit, Geschwindigkeit, Nutzerzufriedenheit oder Lösungsraten priorisieren. Konfigurieren Sie das bewertende LLM der Plattform mit detaillierten Prompts, in denen Sie festlegen, wie Antworten bewertet werden sollen, einschließlich konkreter Beispiele für gute und schlechte Antworten. Laden Sie Ihren Gesprächsdatenbestand hoch oder verbinden Sie Live-Traffic und führen Sie dann Bewertungen durch, um detaillierte Berichte über alle Metriken zu erhalten. Das FlowHunt-Dashboard bietet Echtzeit-Einblick in die Chatbot-Leistung, sodass Sie Probleme schnell erkennen und Verbesserungen validieren können.
Erstellen Sie vor der Umsetzung von Verbesserungen eine Baseline-Messung, um einen Referenzpunkt für die Wirkung von Änderungen zu erhalten. Sammeln Sie Messdaten kontinuierlich statt periodisch, um Leistungsverschlechterungen durch Daten-Drift oder Modellalterung frühzeitig zu erkennen. Implementieren Sie Feedbackschleifen, in denen Nutzerbewertungen und Korrekturen automatisch wieder in den Trainingsprozess einfließen und so die Chatbot-Genauigkeit laufend verbessern. Segmentieren Sie Metriken nach Anliegenkategorie, Nutzertyp und Zeitraum, um gezielt Verbesserungsbereiche zu identifizieren, anstatt sich nur auf Gesamtstatistiken zu verlassen.
Stellen Sie sicher, dass Ihr Bewertungsdatensatz reale Nutzeranfragen und erwartete Antworten enthält und keine künstlichen Testfälle, die das tatsächliche Nutzungsverhalten nicht abbilden. Validieren Sie automatisierte Metriken regelmäßig durch menschliche Bewertungen einer Stichprobe von Gesprächen, um sicherzustellen, dass Ihr Messsystem tatsächlich die Qualität widerspiegelt. Dokumentieren Sie Ihre Bewertungsmethodik und Metrikdefinitionen klar, um eine konsistente Bewertung über die Zeit und eine transparente Kommunikation der Ergebnisse an Stakeholder zu ermöglichen. Legen Sie schließlich für jede Metrik Leistungsziele fest, die sich an den Geschäftszielen orientieren – so schaffen Sie Verantwortlichkeit für kontinuierliche Verbesserung und klare Optimierungsziele.
Die fortschrittliche KI-Automatisierungsplattform von FlowHunt hilft Ihnen dabei, leistungsstarke Helpdesk-Chatbots mit integrierten Genauigkeitsmessungs-Tools und LLM-basierter Bewertung zu erstellen, bereitzustellen und zu bewerten.
Erfahren Sie umfassende Teststrategien für KI-Chatbots, einschließlich funktionaler, leistungsbezogener, sicherheitsrelevanter und benutzerorientierter Tests. E...
Erfahren Sie bewährte Methoden zur Überprüfung der Authentizität von KI-Chatbots im Jahr 2025. Entdecken Sie technische Verifizierungsverfahren, Sicherheitschec...
Entdecken Sie die besten KI-Chatbot-Plattformen mit nativen A/B-Testfunktionen. Vergleichen Sie Dialogflow, Botpress, ManyChat, Intercom und mehr. Lernen Sie, w...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.