Erfahren Sie, was Google Gemini ist, wie es funktioniert und wie es sich mit ChatGPT vergleicht. Lernen Sie seine multimodalen Fähigkeiten, Preisgestaltung und reale Anwendungsfälle für 2025 kennen.
Was ist der Google Gemini KI-Chatbot?
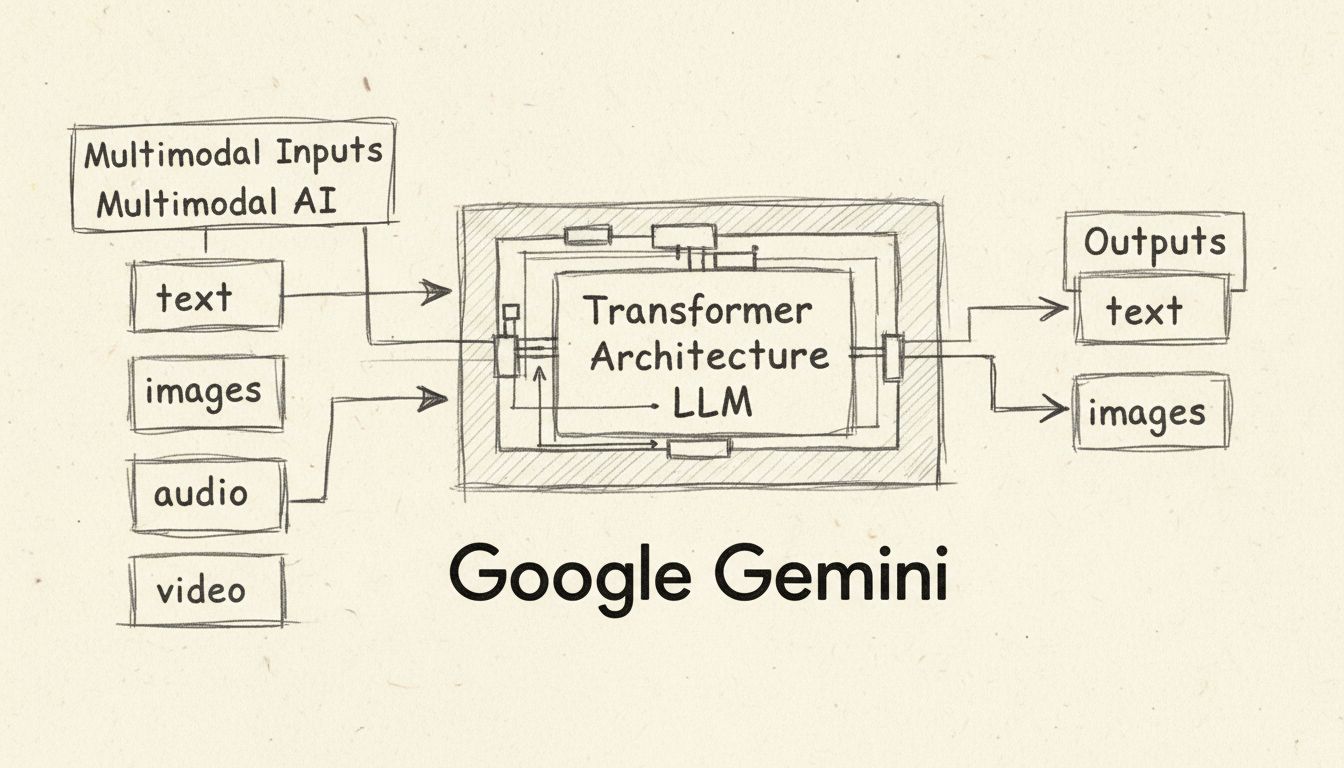
Google Gemini ist ein multimodaler KI-Chatbot und ein großes Sprachmodell, entwickelt von Google DeepMind, das Text, Bilder, Audio und Video verarbeiten und generieren kann. Gestartet im Dezember 2023 und im Februar 2024 von Bard in Gemini umbenannt, treibt Gemini Googles KI-Assistenten auf Pixel-Smartphones, in der Google-Suche und in Workspace-Anwendungen an.
Google Gemini verstehen: Die nächste Generation der KI-Chatbots
Google Gemini stellt einen bedeutenden Fortschritt in der Technologie der künstlichen Intelligenz dar und verändert grundlegend, wie Nutzer mit KI-gestützten Tools interagieren. Ursprünglich im März 2023 als Bard eingeführt, benannte Google seinen KI-Assistenten im Februar 2024 in Gemini um, was das zugrunde liegende große Sprachmodell (LLM) widerspiegelt, das die Plattform antreibt. Gemini ist kein einfacher Chatbot – es handelt sich um eine hochentwickelte Familie multimodaler KI-Modelle, entwickelt von Google DeepMind, die Inhalte über mehrere Datentypen hinweg gleichzeitig verstehen und generieren können. Diese bahnbrechende Fähigkeit unterscheidet Gemini von früheren KI-Generationen, die sich hauptsächlich auf textbasierte Interaktionen konzentrierten. Die Plattform wurde im gesamten Google-Ökosystem integriert, angefangen bei Pixel-Smartphones bis hin zur Google-Suche und Workspace-Anwendungen, und ist damit einer der zugänglichsten KI-Assistenten für Verbraucher und Unternehmen weltweit.
Was Gemini unterscheidet: Multimodale KI-Fähigkeiten
Das prägende Merkmal von Gemini ist seine multimodale Architektur, was bedeutet, dass es mehrere Arten von Daten gleichzeitig verarbeiten und generieren kann. Im Gegensatz zu ChatGPT, das primär textbasierte Eingaben und Ausgaben verarbeitet, unterstützt Gemini nativ Text, Bilder, Audio und Video als Ein- und Ausgaben. Diese multimodale Fähigkeit ermöglicht es Gemini, komplexe visuelle Informationen wie Diagramme, Schaubilder und Fotos zu verstehen, ohne auf externe optische Zeichenerkennung (OCR) angewiesen zu sein. Das Modell kann handschriftliche Notizen, Grafiken und technische Zeichnungen analysieren, um komplexe Probleme zu lösen, für die in herkömmlichen Workflows mehrere spezialisierte Tools erforderlich wären. Darüber hinaus unterstützt Gemini die Audiobearbeitung in mehr als 100 Sprachen und ermöglicht so Echtzeit-Spracherkennung und Übersetzungsfunktionen. Die Videofunktion erlaubt es Gemini, Videoframes zu analysieren und Fragen zum Videoinhalt zu beantworten, was es für Inhaltsanalysen und Zusammenfassungen besonders wertvoll macht.
Die auf Transformern basierende neuronale Netzwerkarchitektur von Gemini wurde speziell verbessert, um lange Kontextsequenzen über verschiedene Datentypen hinweg zu verarbeiten. Google DeepMind hat effiziente Aufmerksamkeitsmechanismen im Transformer-Decoder implementiert, sodass die Modelle erweiterte Kontexte verarbeiten können – einige Versionen unterstützen bis zu 2 Millionen Tokens, deutlich mehr als das 128.000-Token-Limit von ChatGPT. Dieses erweiterte Kontextfenster ermöglicht es Gemini, ganze Bücher, lange Berichte und tausende Codezeilen in einer einzigen Interaktion zu analysieren und dabei umfassendere und kontextbewusstere Antworten zu liefern.
Gemini-Modellvarianten: Die passende Version für Ihren Bedarf wählen
Google bietet mehrere Versionen von Gemini an, die jeweils für bestimmte Anwendungsfälle und Einsatzumgebungen optimiert sind. Das Verständnis dieser Varianten ist entscheidend, um das passende Modell für Ihre Anforderungen auszuwählen. Das Gemini 1.0 Nano ist die kleinste Version, die für mobile Anwendungen auf Geräten entwickelt wurde und beispielsweise auf Android-Smartphones wie dem Pixel 8 Pro ohne Internetverbindung laufen kann. Nano kann Aufgaben wie Bilder beschreiben, Chat-Antworten vorschlagen, Texte zusammenfassen und Sprache direkt auf dem Gerät transkribieren. Das Gemini 1.0 Ultra ist die leistungsstärkste Version der ersten Generation, entwickelt für hochkomplexe Aufgaben wie fortgeschrittenes Programmieren, mathematisches Schließen und anspruchsvolles multimodales Denken. Beide Versionen, Nano und Ultra, verfügen über ein Kontextfenster von 32.000 Tokens.
Das neuere Gemini 1.5 Pro ist ein mittelgroßes multimodales Modell, das ein hervorragendes Gleichgewicht zwischen Leistungsfähigkeit und Effizienz bietet und beeindruckende 2 Millionen Tokens im Kontextfenster unterstützt. Diese Version verwendet eine Mixture of Experts (MoE) Architektur, bei der das Modell in kleinere, spezialisierte neuronale Netzwerke aufgeteilt ist, die je nach Eingabetyp selektiv aktiviert werden, was zu schnellerer Leistung und geringeren Rechenkosten führt. Gemini 1.5 Flash ist eine schlankere Version, die durch Wissensdestillation entstand – dabei wurden Erkenntnisse aus Gemini 1.5 Pro auf ein kompakteres und effizienteres Modell übertragen. Flash behält ein Kontextfenster von 1 Million Tokens bei, bietet jedoch eine geringere Latenz und eignet sich ideal für Anwendungen, bei denen Schnelligkeit und Effizienz gefragt sind. Das aktuelle Gemini 2.0 Flash, veröffentlicht im Dezember 2024, ist doppelt so schnell wie 1.5 Pro und bietet neue Funktionen wie multimodale Ein- und Ausgaben, ein erweitertes Kontextverständnis und native Audiostreaming-Anwendungen.
Modellversion
Kontextfenster
Am besten geeignet für
Hauptmerkmale
Gemini 1.0 Nano
32.000 Tokens
Mobile On-Device-Aufgaben
Leichtgewichtig, kein Internet erforderlich
Gemini 1.0 Ultra
32.000 Tokens
Komplexes Denken & Programmierung
Leistungsstärkstes Modell der ersten Generation
Gemini 1.5 Pro
2 Millionen Tokens
Unternehmensanwendungen
Mixture of Experts-Architektur
Gemini 1.5 Flash
1 Million Tokens
Geschwindigkeitskritische Anwendungen
Wissensdestilliert, geringe Latenz
Gemini 2.0 Flash
Erweitertes Kontextfenster
Neueste Anwendungen
2x schneller, multimodales Streaming
Wie Gemini funktioniert: Die technische Grundlage
Gemini arbeitet mit einer Transformer-Modellarchitektur, einem neuronalen Netzwerkdesign, das von Google selbst im Jahr 2017 entwickelt wurde. Das System funktioniert durch drei Hauptmechanismen: Encoder wandeln Eingabesequenzen in numerische Repräsentationen – so genannte Embeddings – um, die semantische Bedeutung und Token-Position abbilden; ein Self-Attention-Mechanismus erlaubt es dem Modell, sich unabhängig von der Position auf die wichtigsten Tokens zu konzentrieren; und Decoder nutzen diesen Aufmerksamkeitsmechanismus sowie die Encoder-Embeddings, um die wahrscheinlichste Ausgabesequenz zu generieren. Im Gegensatz zu traditionellen GPT-Modellen, die nur textbasierte Eingaben verarbeiten, unterstützt Gemini verschachtelte Sequenzen aus Audio, Bildern, Text und Video als Eingaben und kann verschachtelte Text- und Bildausgaben erzeugen.
Für das Training von Gemini wurden riesige mehrsprachige und multimodale Datensätze aus Text, Bildern, Audio und Video verwendet. Google DeepMind setzte fortschrittliche Datenfilterungstechniken ein, um die Trainingsqualität zu optimieren und sicherzustellen, dass das Modell von vielfältigen, hochwertigen Informationsquellen lernt. Während Trainings- und Inferenzphasen profitiert Gemini von Googles neuesten Tensor Processing Unit Chips, Trillium (sechste Generation der Google Cloud TPU), die im Vergleich zu Vorgängergenerationen eine bessere Leistung, geringere Latenz und niedrigere Kosten bieten. Diese Spezialprozessoren sind deutlich energieeffizienter als frühere Versionen, was Gemini nachhaltiger und kostengünstiger im großen Maßstab macht.
Geminis Integration im Google-Ökosystem
Google hat Gemini strategisch in seine gesamte Produktpalette integriert und KI-Unterstützung in alltäglichen Tools verfügbar gemacht. Auf Google Pixel-Smartphones dient Gemini als Standard-KI-Assistent und ersetzt Google Assistant. Nutzer können Gemini über jede App, einschließlich Chrome, aktivieren, um Fragen zu dem zu stellen, was auf dem Bildschirm zu sehen ist, Webseiten zusammenzufassen oder mehr Informationen zu Bildern zu erhalten. Das Pixel 8 Pro war das erste Gerät, das für den Einsatz von Gemini Nano entwickelt wurde und KI-Verarbeitung direkt auf dem Gerät ohne Cloud-Anbindung ermöglicht. In der Google-Suche treibt Gemini die AI Overviews an, die ausführliche, kontextreiche Antworten an der Spitze der Suchergebnisse bereitstellen. Diese Overviews zerlegen komplexe Themen in leicht verständliche Erklärungen, damit Nutzer komplizierte Sachverhalte schneller erfassen. Nutzer ab 13 Jahren in den USA können AI Overviews nutzen, die Verfügbarkeit wird auf Nutzer ab 18 in Ländern wie Großbritannien, Indien, Mexiko, Brasilien, Indonesien und Japan ausgeweitet.
In Google Workspace erscheint Gemini im Seitenbereich von Docs, um beim Schreiben und Bearbeiten von Inhalten zu helfen, in Gmail unterstützt es beim Verfassen von E-Mails und gibt Antwortvorschläge, und in weiteren Anwendungen wie Google Maps liefert es Zusammenfassungen von Orten und Regionen. Android-Entwickler können Gemini Nano über die AICore-Systemfunktion des Android-Betriebssystems nutzen, um intelligente Anwendungen mit On-Device-KI-Verarbeitung zu erstellen. Googles Vertex AI-Cloud-Service stellt Gemini Pro für Entwickler bereit, die eigene Anwendungen bauen, während das Google AI Studio ein webbasiertes Tool zur Prototypenentwicklung und Anwendungsentwicklung mit Gemini bietet.
Preise und Zugänglichkeit: Kostenlose und Premium-Optionen
Gemini bietet flexible Preisoptionen, die auf verschiedene Nutzerbedürfnisse und Budgets zugeschnitten sind. Die kostenlose Stufe gewährt Zugang zu Gemini mit dem 1.5 Flash-Modell und einem Kontextfenster von 32.000 Tokens – ideal für Alltagsnutzer und alle, die KI-Fähigkeiten erkunden möchten. Nutzer müssen mindestens 13 Jahre alt sein (18 in Europa) und ein persönliches Google-Konto besitzen, um die kostenlose Version zu nutzen. Gemini Advanced kostet 20 US-Dollar pro Monat und bietet Zugriff auf das leistungsstärkere 1.5 Pro-Modell mit einem 2-Millionen-Token-Kontextfenster sowie erweiterte Funktionen wie Deep Research, Bilderstellung mit Nano Banana Pro und Videogenerierung. Dieses Abo beinhaltet außerdem monatlich 100 KI-Credits für die Videogenerierung in Flow und Whisk.
Für Unternehmen bietet Google Gemini Business für 20 US-Dollar pro Nutzer und Monat (bei Jahresvertrag) bzw. 24 US-Dollar monatlich (bei monatlicher Zahlung) an, ausgelegt für kleine und mittlere Unternehmen. Gemini Enterprise kostet 30 US-Dollar pro Nutzer und Monat im Jahresvertrag, mit individuellen Preisen über das Google-Vertriebsteam für größere Implementierungen. Entwickler können Gemini über die kostenlose API-Stufe mit begrenzter Nutzung testen und Prototypen erstellen, bevor sie sich für kostenpflichtige Pläne entscheiden. Das Google AI Pro-Abo für 21,99 US-Dollar monatlich gewährt umfassenden Zugang zu Gemini 3 Pro, Deep Research und Videogenerierung mit Veo 3.1, während die Google AI Ultra-Stufe für 274,99 US-Dollar pro Monat maximalen Zugriff auf alle Funktionen einschließlich Deep Think und Gemini Agent bietet.
Gemini vs. ChatGPT: Ein umfassender Vergleich
Beim Vergleich von Gemini und ChatGPT treten mehrere entscheidende Unterschiede zutage, die ihre Eignung für verschiedene Anwendungen beeinflussen. Multimodale Fähigkeiten sind ein wesentliches Unterscheidungsmerkmal – Gemini wurde von Grund auf als multimodales Modell entwickelt und unterstützt Text, Bilder, Audio und Video, während sich ChatGPT ursprünglich auf Text konzentrierte und Bildunterstützung erst später mit GPT-4 hinzukam. Die Länge des Kontextfensters ist ein weiterer wichtiger Faktor: Gemini 1.5 Pro unterstützt 2 Millionen Tokens, während ChatGPT auf 128.000 Tokens begrenzt ist, wodurch Gemini wesentlich mehr Informationen in einer einzigen Interaktion verarbeiten kann. Die Verfügbarkeit für Entwickler unterscheidet sich deutlich: ChatGPT ist über die OpenAI-API verfügbar und wurde an Microsoft zur Integration in Bing lizenziert, während Gemini hauptsächlich über Googles eigene Plattformen und Dienste zugänglich ist.
In Bezug auf Leistungsbenchmarks übertrifft Gemini Ultra ChatGPT in mehreren Bereichen, darunter GSM8K für mathematisches Schließen, HumanEval für Codegenerierung und MMLU für Sprachverständnis, wobei Gemini Ultra sogar menschliche Experten schlägt. Allerdings schneidet ChatGPT im HellaSwag-Benchmark für Alltagslogik und Sprachinferenz besser ab. Die Integrationsdichte spricht für Gemini, wenn Nutzer bereits im Google-Ökosystem aktiv sind, da es tief in Suche, Workspace und Pixel-Geräte integriert ist, während ChatGPT separat über OpenAI oder über Microsofts Bing genutzt werden muss. Beide Plattformen haben ähnliche Herausforderungen in Bezug auf Halluzinationen und Verzerrungen, wobei beide Unternehmen Maßnahmen zur Risikominimierung implementiert haben.
Anwendungsfälle aus der Praxis
Dank seiner vielseitigen Fähigkeiten eröffnet Gemini zahlreiche praktische Einsatzmöglichkeiten in unterschiedlichen Branchen. In der Softwareentwicklung kann Gemini Code in gängigen Programmiersprachen wie Python, Java, C++ und Go verstehen, erklären und generieren. Googles AlphaCode 2 nutzt eine angepasste Version von Gemini Pro, um Wettbewerbsprogrammieraufgaben aus theoretischer Informatik und komplexer Mathematik zu lösen. Bei der Inhaltsgenerierung und -analyse kann Gemini lange Dokumente zusammenfassen, kreative Inhalte erstellen und visuelles Material ohne externe Tools analysieren. Die Malwareanalyse ermöglicht Sicherheitsexperten, mit Gemini 1.5 Pro zu bestimmen, ob Dateien oder Codeschnipsel schädlich sind, und detaillierte Berichte zu erstellen, während Gemini Flash schnelle, großflächige Malware-Analysen ermöglicht.
Bei der Sprachübersetzung nutzt Gemini seine Mehrsprachigkeit, um zwischen über 100 Sprachen mit nahezu menschlicher Genauigkeit zu übersetzen. Im Bildungsbereich hilft Gemini Schülern, indem es komplexe Themen vereinfacht, Lernmaterialien erstellt und personalisierte Unterstützung durch die Funktion Learning Coach Gem bietet. Business Intelligence-Anwendungen profitieren von Geminis Fähigkeit, Diagramme, Schaubilder und komplexe Visualisierungen zu analysieren, um Geschäftsdaten auszuwerten. Die Gems-Funktion erlaubt Nutzern, maßgeschneiderte KI-Experten zu beliebigen Themen zu erstellen, mit vorgefertigten Optionen wie Lerncoach, Brainstorming-Partner oder Schreibassistent. Project Astra, Googles universelle KI-Agenten-Initiative, baut auf Gemini-Modellen auf, um Agenten zu schaffen, die multimodale Informationen in Echtzeit verarbeiten, erinnern und verstehen können – ein Vorgeschmack auf autonome KI-Assistenten.
Einschränkungen und Bedenken bei Gemini
Trotz seiner fortschrittlichen Fähigkeiten weist Gemini einige wichtige Einschränkungen auf, die Nutzer beachten sollten. KI-Halluzinationen sind weiterhin ein Thema: Gemini erzeugt gelegentlich sachlich falsche Informationen und präsentiert diese als korrekt. Besonders bei AI Overviews in der Suche kam es vor, dass das System seltsame oder ungenaue Empfehlungen lieferte. Verzerrungen in den Trainingsdaten können zu einseitigen Ergebnissen führen, insbesondere wenn bestimmte Bevölkerungsgruppen im Training unterrepräsentiert sind oder die Daten selbst Vorurteile enthalten. Im Februar 2024 pausierte Google die Bildgenerierungsfunktion von Gemini, nachdem das System historische Figuren fehlerhaft darstellte und rassistische Verzerrungen zeigte, indem es etwa schwarze und asiatische Nazi-Soldaten generierte – ein Fehler, den Google inzwischen korrigiert hat.
Einschränkungen im Kontextverständnis führen dazu, dass Gemini manchmal die Feinheiten und Zusammenhänge komplexer Anfragen nicht vollständig erfasst und daher Ergebnisse liefert, die nicht ganz zur Nutzeranfrage passen. Grenzen bei Originalität und Kreativität bestehen insbesondere in der kostenlosen Version, die Schwierigkeiten mit komplizierten, mehrstufigen Aufgaben hat, die differenziertes Denken erfordern. Probleme mit geistigem Eigentum traten auf, da Google in Frankreich für das Training von Gemini mit Nachrichteninhalten ohne Wissen oder Zustimmung der Herausgeber zu einer Geldstrafe verurteilt wurde. Aktualität der Trainingsdaten ist eine weitere Einschränkung, da Gemini nur bis zu einem bestimmten Zeitpunkt trainiert wurde und die neuesten Entwicklungen oder Ereignisse eventuell nicht kennt. Kritische Informationen sollten daher aus zuverlässigen Quellen überprüft werden, anstatt sich ausschließlich auf die Gemini-Ausgaben zu verlassen, insbesondere bei sensiblen Anwendungen.
Die Zukunft von Gemini und KI-Automatisierung
Google entwickelt die Fähigkeiten von Gemini kontinuierlich mit regelmäßigen Updates und neuen Funktionen weiter. Die Veröffentlichung von Gemini 2.0 Flash im Dezember 2024 brachte deutliche Leistungssteigerungen, mit einer doppelt so hohen Geschwindigkeit wie 1.5 Pro bei gleichbleibender Qualität. Gemini Live ermöglicht natürliche, freihändige Gespräche mit dem KI-Assistenten, bietet zehn Sprachoptionen und die Möglichkeit, Unterhaltungen nahtlos zu pausieren und fortzusetzen. Die Funktion Deep Research erlaubt es Nutzern, Hunderte von Webseiten zu durchsuchen, Ergebnisse zu analysieren und umfassende Berichte zu erstellen – als persönlicher Rechercheassistent. Canvas ist ein kollaborativer Arbeitsbereich für Schreib- und Programmierprojekte, während mit Gems spezialisierte KI-Experten für bestimmte Aufgaben oder Bereiche erstellt werden können.
Für die Zukunft plant Google, Gemini weltweit verfügbar zu machen und bis Ende 2025 über eine Milliarde Nutzer zu erreichen. Außerdem arbeitet das Unternehmen an weiteren spezialisierten Versionen von Gemini für spezifische Branchen und Anwendungsfälle, darunter erweiterte Funktionen für Gesundheitswesen, Finanzen und wissenschaftliche Forschung. Die Integration mit aufkommenden Technologien wie Augmented Reality und fortschrittlicher Robotik soll neue Möglichkeiten für KI-gestützte Workflows schaffen. Für Unternehmen, die KI-Automatisierung im großen Maßstab einsetzen möchten, bieten Plattformen wie FlowHunt Enterprise-Lösungen, um Gemini und andere KI-Modelle in automatisierte Workflows zu integrieren – so können Organisationen den Mehrwert von KI-Technologie maximieren und gleichzeitig Kontrolle und Sicherheit über ihre Prozesse behalten.
Automatisieren Sie Ihre KI-Workflows mit FlowHunt
FlowHunt ist die führende KI-Automatisierungsplattform, mit der Sie intelligente Workflows erstellen, bereitstellen und verwalten können. Im Gegensatz zu anderen KI-Tools bietet FlowHunt Unternehmensfunktionen zur Automatisierung, um Gemini und andere KI-Modelle nahtlos in Ihre Geschäftsprozesse zu integrieren.
Google KI-Modus: Die KI-gestützte Suche, die Perplexity herausfordert
Entdecken Sie Googles neuen KI-Modus für die Suche, angetrieben von Gemini 2.5 – wie er sich mit Perplexity vergleicht und warum er die Websuche mit KI-gestützt...
Entdecken Sie die wichtigsten Ankündigungen von Google I/O 2025, darunter Gemini 2.5 Flash, Project Astra, Android XR, KI-Agenten in Android Studio, Gemini Nano...
Bard AI Chatbot: Von welchem Unternehmen wurde er entwickelt?
Erfahren Sie, welches Unternehmen den Bard AI-Chatbot entwickelt hat. Lernen Sie Googles Gemini LLM kennen, seine Funktionen, Fähigkeiten und wie er sich im Jah...
9 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.