
Insight Engine
Entdecken Sie, was ein Insight Engine ist – eine fortschrittliche, KI-gesteuerte Plattform, die die Datenrecherche und -analyse durch das Verständnis von Kontex...
10 Min. Lesezeit
AI
Insight Engine
+5

Die KI-Suche nutzt maschinelles Lernen und Vektorembeddings, um Suchintention und Kontext zu verstehen und liefert hochrelevante Ergebnisse jenseits exakter Schlüsselwortübereinstimmungen.
Die KI-Suche nutzt maschinelles Lernen, um Kontext und Intention von Suchanfragen zu verstehen und diese in numerische Vektoren umzuwandeln, um genauere Ergebnisse zu erzielen. Im Gegensatz zu herkömmlichen Schlüsselwortsuchen interpretiert die KI-Suche semantische Beziehungen und ist dadurch für verschiedene Datentypen und Sprachen effektiv.
Die KI-Suche, oft auch als semantische oder Vektorsuche bezeichnet, ist eine Suchmethode, die maschinelle Lernmodelle nutzt, um die Absicht und den kontextuellen Sinn hinter Suchanfragen zu verstehen. Im Gegensatz zu klassischen, schlüsselwortbasierten Suchverfahren wandelt die KI-Suche Daten und Anfragen in numerische Repräsentationen um, sogenannte Vektoren oder Embeddings. Dadurch kann die Suchmaschine semantische Beziehungen zwischen verschiedenen Datenstücken erfassen und liefert relevantere und genauere Ergebnisse – auch wenn die exakten Schlüsselwörter nicht vorkommen.
Die KI-Suche stellt eine bedeutende Weiterentwicklung im Bereich der Suchtechnologien dar. Traditionelle Suchmaschinen setzen stark auf Schlüsselwortübereinstimmungen, wobei das Vorkommen bestimmter Begriffe in Anfrage und Dokument die Relevanz bestimmt. Die KI-Suche hingegen nutzt maschinelle Lernmodelle, um den zugrundeliegenden Kontext und die Bedeutung von Anfragen und Daten zu erfassen.
Durch die Umwandlung von Text, Bildern, Audio und anderen unstrukturierten Daten in hochdimensionale Vektoren kann die KI-Suche die Ähnlichkeit zwischen verschiedenen Inhalten messen. So liefert die Suchmaschine auch dann kontextuell relevante Ergebnisse, wenn die exakten Schlüsselwörter in der Suchanfrage nicht enthalten sind.
Wichtige Komponenten:
Im Zentrum der KI-Suche steht das Konzept der Vektorembeddings. Vektorembeddings sind numerische Repräsentationen von Daten, die die semantische Bedeutung von Text, Bildern oder anderen Datentypen erfassen. Ähnliche Datenstücke werden im multidimensionalen Vektorraum nahe beieinander platziert.
Funktionsweise:
Beispiel:
Klassische, schlüsselwortbasierte Suchmaschinen arbeiten, indem sie Begriffe in der Suchanfrage mit Dokumenten abgleichen, die diese Begriffe enthalten. Sie nutzen Techniken wie invertierte Indizes und Termfrequenz zur Relevanzbewertung.
Einschränkungen der Schlüsselwortsuche:
Vorteile der KI-Suche:
| Aspekt | Schlüsselwortsuche | KI-Suche (Semantisch/Vektor) |
|---|---|---|
| Abgleich | Exakte Schlüsselworttreffer | Semantische Ähnlichkeit |
| Kontextbewusstsein | Gering | Hoch |
| Synonymerkennung | Manuelle Synonymlisten nötig | Automatisch durch Embeddings |
| Rechtschreibfehler | Scheitert oft ohne Fuzzy-Suche | Toleranter durch semantischen Kontext |
| Intentionsverständnis | Minimal | Ausgeprägt |
Die semantische Suche ist eine Kernanwendung der KI-Suche und zielt darauf ab, die Nutzerintention und den kontextuellen Sinn von Anfragen zu verstehen.
Ablauf:
Wichtige Techniken:
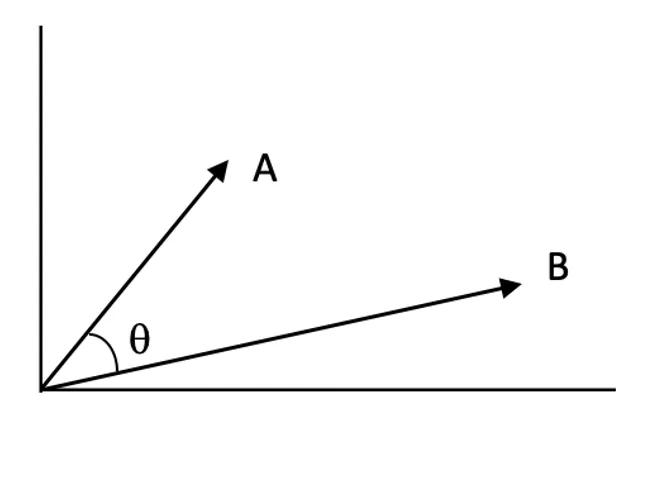
Ähnlichkeitspunkte:
Ähnlichkeitspunkte quantifizieren, wie eng zwei Vektoren im Vektorraum miteinander verwandt sind. Ein höherer Wert deutet auf eine größere Relevanz zwischen Anfrage und Dokument hin.
Approximative Nächste-Nachbarn (ANN)-Algorithmen:
Das Finden der exakten nächsten Nachbarn im hochdimensionalen Raum ist rechnerisch aufwendig. ANN-Algorithmen bieten effiziente Näherungen.
Die KI-Suche eröffnet durch ihre Fähigkeit, Daten über reines Schlüsselwortmatching hinaus zu verstehen und zu interpretieren, vielfältige Anwendungsbereiche.
Beschreibung: Die semantische Suche verbessert das Nutzererlebnis, indem sie die Intention hinter Anfragen interpretiert und kontextuell relevante Ergebnisse liefert.
Beispiele:
Beschreibung: Durch das Verständnis von Nutzerpräferenzen und -verhalten kann die KI-Suche personalisierte Inhalte oder Produktempfehlungen bieten.
Beispiele:
Beschreibung: Die KI-Suche ermöglicht Systemen, Benutzeranfragen zu verstehen und präzise Informationen aus Dokumenten bereitzustellen.
Beispiele:
Beschreibung: Die KI-Suche kann unstrukturierte Datentypen wie Bilder, Audio und Videos durch Konvertierung in Embeddings indexieren und durchsuchen.
Beispiele:
Die Integration der KI-Suche in KI-Automatisierung und Chatbots erweitert deren Fähigkeiten erheblich.
Vorteile:
Implementierungsschritte:
Anwendungsbeispiel:
Trotz zahlreicher Vorteile der KI-Suche gibt es Herausforderungen:
Strategien zur Risikominderung:
Semantische und Vektorsuche in der KI haben sich als leistungsstarke Alternativen zu traditionellen, schlüsselwortbasierten und Fuzzy-Suchen etabliert und steigern die Relevanz und Genauigkeit von Suchergebnissen, indem sie Kontext und Bedeutung hinter Anfragen verstehen.
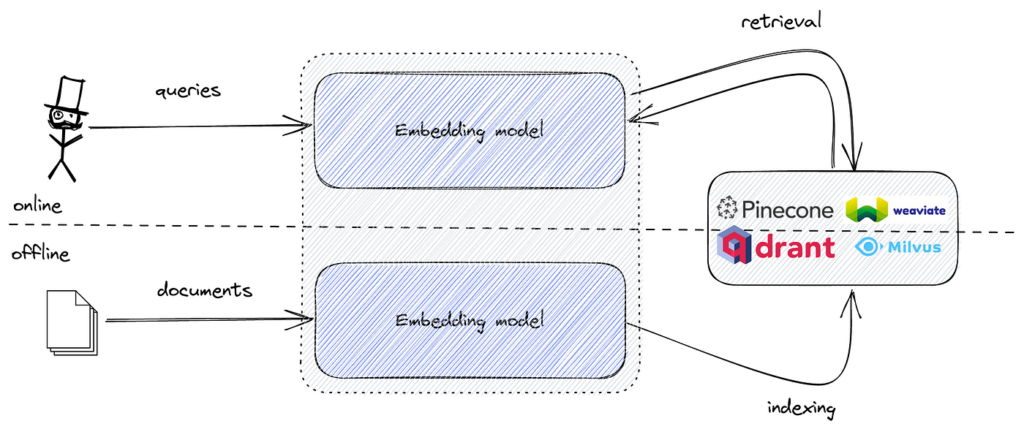
Bei der Implementierung der semantischen Suche werden Textdaten in Vektorembeddings umgewandelt, die die semantische Bedeutung des Textes erfassen. Diese Embeddings sind hochdimensionale numerische Repräsentationen. Um diese Embeddings effizient durchsuchen und die ähnlichsten zum Such-Embedding finden zu können, wird ein für Ähnlichkeitssuche im hochdimensionalen Raum optimiertes Tool benötigt.
FAISS bietet die nötigen Algorithmen und Datenstrukturen, um diese Aufgabe effizient zu erfüllen. Durch die Kombination von semantischen Embeddings mit FAISS lässt sich eine leistungsstarke semantische Suchmaschine realisieren, die große Datenmengen mit niedriger Latenz verarbeiten kann.
Die Implementierung der semantischen Suche mit FAISS in Python umfasst mehrere Schritte:
Im Folgenden werden die einzelnen Schritte detailliert beschrieben.
Bereiten Sie Ihren Datensatz vor (z.B. Artikel, Support-Tickets, Produktbeschreibungen).
Beispiel:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Bereinigen und formatieren Sie die Textdaten nach Bedarf.
Wandeln Sie die Textdaten mit vortrainierten Transformer-Modellen aus Bibliotheken wie Hugging Face (transformers oder sentence-transformers) in Vektorembeddings um.
Beispiel:
from sentence_transformers import SentenceTransformer
import numpy as np
# Lade ein vortrainiertes Modell
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generiere Embeddings für alle Dokumente
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 gespeichert, wie es FAISS benötigt.Erstellen Sie einen FAISS-Index, um die Embeddings zu speichern und eine effiziente Ähnlichkeitssuche zu ermöglichen.
Beispiel:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 führt eine exakte Suche mit L2 (euklidische Distanz) durch.Wandeln Sie die Nutzeranfrage in ein Embedding um und suchen Sie nach den nächsten Nachbarn.
Beispiel:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Geben Sie mit den Indizes die relevantesten Dokumente aus.
Beispiel:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Erwartete Ausgabe:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS bietet verschiedene Indextypen:
Verwendung eines Invertierten Datei-Index (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalisierung und Suche mit Skalarprodukt:
Die Verwendung von Kosinusähnlichkeit kann für Textdaten effektiver sein
KI-Suche ist eine moderne Suchmethode, die maschinelles Lernen und Vektorembeddings nutzt, um die Intention und den kontextuellen Sinn von Anfragen zu verstehen und liefert genauere und relevantere Ergebnisse als herkömmliche, auf Schlüsselwörtern basierende Suchen.
Im Gegensatz zur schlüsselwortbasierten Suche, die auf exakten Übereinstimmungen basiert, interpretiert die KI-Suche die semantischen Beziehungen und die Absicht hinter Anfragen und ist somit effektiv bei natürlicher Sprache und mehrdeutigen Eingaben.
Vektorembeddings sind numerische Repräsentationen von Text, Bildern oder anderen Datentypen, die deren semantische Bedeutung erfassen. So kann die Suchmaschine Ähnlichkeit und Kontext zwischen verschiedenen Datenstücken messen.
KI-Suche ermöglicht semantische Suche im E-Commerce, personalisierte Empfehlungen im Streaming, Frage-Antwort-Systeme im Kundensupport, das Durchsuchen unstrukturierter Daten sowie die Dokumentensuche in Forschung und Unternehmen.
Beliebte Tools sind FAISS für effiziente Vektorähnlichkeitssuche sowie Vektordatenbanken wie Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch und Pgvector zur skalierbaren Speicherung und Abfrage von Embeddings.
Durch die Integration der KI-Suche können Chatbots und Automatisierungssysteme Benutzeranfragen tiefergehend verstehen, kontextuell relevante Antworten liefern und dynamische, personalisierte Reaktionen bieten.
Zu den Herausforderungen zählen hoher Rechenaufwand, Komplexität bei der Modellinterpretierbarkeit, Bedarf an hochwertigen Daten sowie die Gewährleistung von Datenschutz und Sicherheit bei sensiblen Informationen.
FAISS ist eine Open-Source-Bibliothek für effiziente Ähnlichkeitssuche auf hochdimensionalen Vektorembeddings und wird häufig zum Aufbau semantischer Suchmaschinen für große Datensätze verwendet.
Entdecken Sie, wie KI-gestützte semantische Suche Ihre Informationsgewinnung, Chatbots und Automatisierungs-Workflows transformieren kann.
Entdecken Sie, was ein Insight Engine ist – eine fortschrittliche, KI-gesteuerte Plattform, die die Datenrecherche und -analyse durch das Verständnis von Kontex...
Perplexity AI ist eine fortschrittliche, KI-gestützte Suchmaschine und ein Konversationswerkzeug, das NLP und maschinelles Lernen nutzt, um präzise, kontextbezo...
Erstellen Sie mühelos hochwertige, datenbasierte Reden mit unserem KI-Agent Redenschreiber. Dieses Tool kombiniert die Möglichkeiten der Google-Suche mit der Ex...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.
