
MLflow
MLflow ist eine Open-Source-Plattform, die entwickelt wurde, um den Lebenszyklus des maschinellen Lernens (ML) zu optimieren und zu verwalten. Sie bietet Werkze...
5 Min. Lesezeit
MLflow
Machine Learning
+3
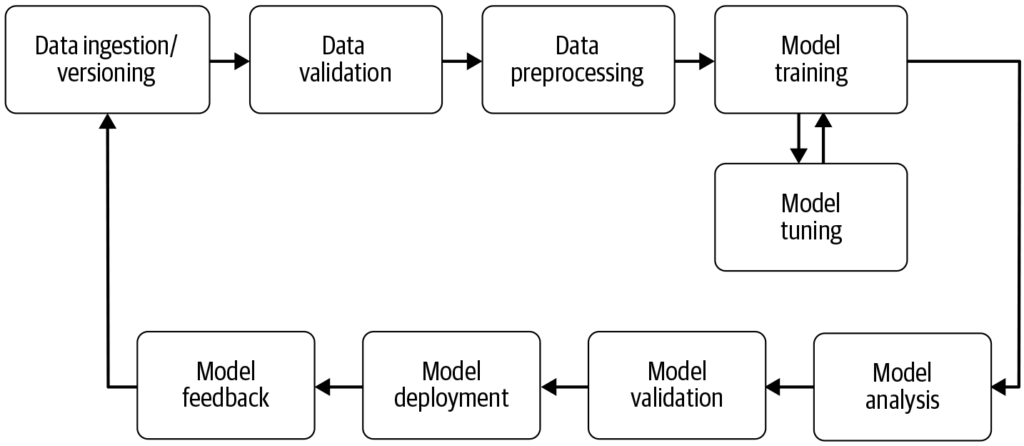
Eine Machine-Learning-Pipeline automatisiert die Schritte von der Datensammlung bis zur Modellbereitstellung und steigert so Effizienz, Reproduzierbarkeit und Skalierbarkeit in Machine-Learning-Projekten.
Eine Machine-Learning-Pipeline ist ein automatisierter Workflow, der die Entwicklung, das Training, die Evaluierung und den Einsatz von Modellen rationalisiert. Sie verbessert Effizienz, Reproduzierbarkeit und Skalierbarkeit und erleichtert Aufgaben von der Datensammlung bis zur Modellbereitstellung und -wartung.
Eine Machine-Learning-Pipeline ist ein automatisierter Workflow, der eine Reihe von Schritten umfasst, die bei der Entwicklung, dem Training, der Evaluierung und dem Einsatz von Machine-Learning-Modellen anfallen. Ziel ist es, die Prozesse zu vereinfachen und zu standardisieren, die notwendig sind, um Rohdaten mithilfe von Machine-Learning-Algorithmen in umsetzbare Erkenntnisse zu verwandeln. Dieser Pipeline-Ansatz ermöglicht eine effiziente Verarbeitung von Daten, das Modelltraining und die Bereitstellung und erleichtert so das Management sowie die Skalierung von Machine-Learning-Projekten.
Quelle: Building Machine Learning
Datenerfassung: Die erste Phase, in der Daten aus verschiedenen Quellen wie Datenbanken, APIs oder Dateien gesammelt werden. Datenerfassung ist eine methodische Praxis, die darauf abzielt, aussagekräftige Informationen zu erhalten, um einen konsistenten und vollständigen Datensatz für einen bestimmten Geschäftszweck zu erstellen. Diese Rohdaten sind essenziell für den Aufbau von Machine-Learning-Modellen, müssen jedoch häufig zunächst vorverarbeitet werden. Wie AltexSoft hervorhebt, beinhaltet die Datenerfassung die systematische Sammlung von Informationen zur Unterstützung von Analysen und Entscheidungsprozessen. Dieser Prozess ist entscheidend, da er die Grundlage für alle weiteren Schritte in der Pipeline bildet und oft kontinuierlich erfolgt, um sicherzustellen, dass Modelle mit relevanten und aktuellen Daten trainiert werden.
Datenvorverarbeitung: Rohdaten werden bereinigt und in ein geeignetes Format für das Modelltraining umgewandelt. Häufige Vorverarbeitungsschritte sind der Umgang mit fehlenden Werten, die Kodierung kategorialer Variablen, das Skalieren numerischer Merkmale und das Aufteilen der Daten in Trainings- und Testdatensätze. Diese Phase stellt sicher, dass die Daten im richtigen Format und frei von Inkonsistenzen sind, die die Modellleistung beeinträchtigen könnten.
Feature Engineering: Hierbei werden neue Merkmale erstellt oder relevante Features aus den Daten ausgewählt, um die Vorhersagekraft des Modells zu verbessern. Dieser Schritt erfordert oft domänenspezifisches Wissen und Kreativität. Feature Engineering ist ein kreativer Prozess, der Rohdaten in sinnvolle Merkmale umwandelt, die das zugrunde liegende Problem besser repräsentieren und die Leistung von Machine-Learning-Modellen steigern.
Modellauswahl: Die geeigneten Machine-Learning-Algorithmen werden basierend auf Problemtyp (z. B. Klassifikation, Regression), Datencharakteristika und Leistungsanforderungen ausgewählt. Auch die Optimierung von Hyperparametern kann in dieser Phase erfolgen. Die Wahl des richtigen Modells ist entscheidend, da sie die Genauigkeit und Effizienz der Vorhersagen maßgeblich beeinflusst.
Modelltraining: Das ausgewählte Modell bzw. die Modelle werden mit dem Trainingsdatensatz trainiert. Dabei lernt das Modell die zugrunde liegenden Muster und Zusammenhänge in den Daten. Es können auch vortrainierte Modelle verwendet werden, statt ein neues Modell von Grund auf zu trainieren. Das Training ist ein zentraler Schritt, bei dem das Modell auf Grundlage der Daten lernt, fundierte Vorhersagen zu treffen.
Modellevaluierung: Nach dem Training wird die Leistung des Modells mithilfe eines separaten Testdatensatzes oder durch Kreuzvalidierung bewertet. Die Evaluierungsmetriken hängen vom jeweiligen Problem ab und können Genauigkeit, Präzision, Recall, F1-Score, mittleren quadratischen Fehler und andere umfassen. Dieser Schritt ist entscheidend, um sicherzustellen, dass das Modell auch auf unbekannten Daten zuverlässig funktioniert.
Modellbereitstellung: Sobald ein zufriedenstellendes Modell entwickelt und evaluiert wurde, kann es in einer Produktionsumgebung eingesetzt werden, um Vorhersagen für neue, unbekannte Daten zu treffen. Die Bereitstellung kann das Erstellen von APIs und die Integration mit anderen Systemen umfassen. Deployment ist die abschließende Phase der Pipeline, in der das Modell für den realen Einsatz verfügbar gemacht wird.
Überwachung und Wartung: Nach der Bereitstellung ist es wichtig, die Leistung des Modells kontinuierlich zu überwachen und es bei Bedarf neu zu trainieren, um sich an verändernde Datenmuster anzupassen und die Genauigkeit sowie Zuverlässigkeit im realen Einsatz sicherzustellen. Dieser fortlaufende Prozess gewährleistet, dass das Modell dauerhaft relevant und exakt bleibt.
Natural Language Processing schlägt eine Brücke zur Mensch-Computer-Interaktion. Entdecken Sie heute die wichtigsten Aspekte, Funktionsweisen und Anwendungen!") (NLP): NLP-Aufgaben bestehen oft aus mehreren wiederkehrenden Schritten wie Datenaufnahme, Textbereinigung, Tokenisierung und Sentiment-Analyse. Pipelines helfen dabei, diese Schritte zu modularisieren, sodass Anpassungen und Updates einfach durchgeführt werden können, ohne andere Komponenten zu beeinträchtigen.
Predictive Maintenance (vorausschauende Wartung): In Branchen wie der Fertigung können Pipelines eingesetzt werden, um Geräteausfälle durch Analyse von Sensordaten vorherzusagen, wodurch proaktive Wartung und weniger Ausfallzeiten möglich werden.
Finanzen: Pipelines können die Verarbeitung von Finanzdaten automatisieren, um Betrug zu erkennen, Kreditrisiken zu bewerten oder Aktienkurse vorherzusagen und so Entscheidungsprozesse zu verbessern.
Gesundheitswesen: Im Gesundheitsbereich können Pipelines medizinische Bilder oder Patientendaten verarbeiten, um Diagnosen zu unterstützen oder Patientenverläufe vorherzusagen und so Behandlungsstrategien zu verbessern.
Machine-Learning-Pipelines sind integraler Bestandteil von KI und Automatisierung](https://www.flowhunt.io “Erstellen Sie KI-Tools und Chatbots mit der No-Code-Plattform von FlowHunt. Entdecken Sie Vorlagen, Komponenten und nahtlose Automatisierung. Buchen Sie noch heute eine Demo!”), da sie einen strukturierten Rahmen zur Automatisierung von Machine-Learning-Aufgaben bieten. Im Bereich der KI-Automatisierung sorgen Pipelines dafür, dass Modelle effizient trainiert und bereitgestellt werden. So können KI-Systeme wie [Chatbots] aus neuen Daten lernen und sich ohne manuelles Eingreifen anpassen. Diese Automatisierung ist entscheidend, um KI-Anwendungen zu skalieren und eine konsistente, zuverlässige Leistung in verschiedenen Bereichen sicherzustellen. Durch die Nutzung von Pipelines können Organisationen ihre KI-Fähigkeiten ausbauen und gewährleisten, dass Machine-Learning-Modelle auch in sich wandelnden Umgebungen effektiv und relevant bleiben.
Forschung zu Machine-Learning-Pipelines
„Deep Pipeline Embeddings for AutoML“ von Sebastian Pineda Arango und Josif Grabocka (2023) befasst sich mit den Herausforderungen bei der Optimierung von Machine-Learning-Pipelines im Bereich Automated Machine Learning (AutoML). Das Paper stellt eine neuartige neuronale Architektur vor, die tiefe Interaktionen zwischen Pipeline-Komponenten erfasst. Die Autoren schlagen vor, Pipelines mithilfe eines einzigartigen, komponentenbasierten Encoder-Mechanismus in latente Repräsentationen einzubetten. Diese Embeddings werden in einem Bayesian-Optimization-Framework genutzt, um optimale Pipelines zu finden. Die Studie betont den Einsatz von Meta-Learning zur Feinabstimmung der Parameter des Pipeline-Embedding-Netzwerks und zeigt modernste Ergebnisse bei der Pipeline-Optimierung über verschiedene Datensätze hinweg. Mehr dazu .
„AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model“ von Tien-Dung Nguyen et al. (2020) behandelt die zeitintensive Evaluierung von Machine-Learning-Pipelines im AutoML-Prozess. Die Studie kritisiert traditionelle Methoden wie Bayes’sche und genetische Optimierungen für ihre Ineffizienz. Als Gegenmaßnahme stellen die Autoren AVATAR vor, ein Surrogatmodell, das die Gültigkeit von Pipelines effizient bewertet, ohne sie auszuführen. Dieser Ansatz beschleunigt die Zusammensetzung und Optimierung komplexer Pipelines erheblich, da ungültige Varianten frühzeitig herausgefiltert werden. Mehr dazu .
„Data Pricing in Machine Learning Pipelines“ von Zicun Cong et al. (2021) untersucht die entscheidende Rolle von Daten in Machine-Learning-Pipelines und die Notwendigkeit der Datenbepreisung zur Förderung der Zusammenarbeit mehrerer Akteure. Das Paper gibt einen Überblick über aktuelle Entwicklungen im Bereich Datenbepreisung im Kontext von Machine Learning und beleuchtet deren Bedeutung in verschiedenen Pipeline-Phasen. Es liefert Einblicke in Preisstrategien für Datensammlung, kollaboratives Modelltraining und die Bereitstellung von Machine-Learning-Diensten und hebt die Entstehung eines dynamischen Ökosystems hervor. Mehr dazu .
Eine Machine-Learning-Pipeline ist eine automatisierte Abfolge von Schritten – von der Datenerfassung und -vorverarbeitung über das Modelltraining und die Evaluierung bis hin zur Bereitstellung –, die den Prozess des Aufbaus und der Wartung von Machine-Learning-Modellen rationalisiert und standardisiert.
Zentrale Komponenten sind Datenerfassung, Datenvorverarbeitung, Feature Engineering, Modellauswahl, Modelltraining, Modellevaluierung, Modellbereitstellung sowie kontinuierliche Überwachung und Wartung.
Machine-Learning-Pipelines bieten Modularisierung, Effizienz, Reproduzierbarkeit, Skalierbarkeit, verbesserte Zusammenarbeit und erleichtern die Bereitstellung von Modellen in Produktionsumgebungen.
Anwendungsfälle sind unter anderem Natural Language Processing (NLP), vorausschauende Wartung in der Fertigung, finanzielle Risikobewertung und Betrugserkennung sowie medizinische Diagnostik.
Zu den Herausforderungen zählen die Sicherstellung der Datenqualität, das Management der Pipeline-Komplexität, die Integration in bestehende Systeme sowie die Kontrolle von Kosten im Zusammenhang mit Rechenressourcen und Infrastruktur.
Vereinbaren Sie eine Demo, um zu entdecken, wie FlowHunt Sie dabei unterstützen kann, Ihre Machine-Learning-Workflows einfach zu automatisieren und zu skalieren.
MLflow ist eine Open-Source-Plattform, die entwickelt wurde, um den Lebenszyklus des maschinellen Lernens (ML) zu optimieren und zu verwalten. Sie bietet Werkze...
BigML ist eine Machine-Learning-Plattform, die darauf ausgelegt ist, die Erstellung und Bereitstellung von Vorhersagemodellen zu vereinfachen. Gegründet im Jahr...
Maschinelles Lernen (ML) ist ein Teilgebiet der künstlichen Intelligenz (KI), das es Maschinen ermöglicht, aus Daten zu lernen, Muster zu erkennen, Vorhersagen ...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.
