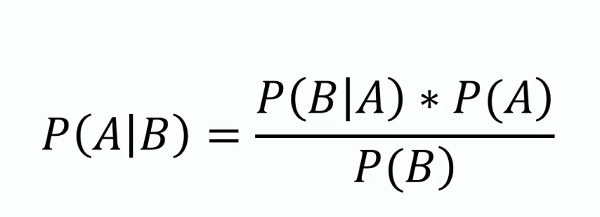
Klassifizierer
Ein KI-Klassifizierer ist ein Machine-Learning-Algorithmus, der Eingabedaten Klassenlabels zuweist und Informationen auf Basis von erlernten Mustern aus histori...
10 Min. Lesezeit
AI
Classifier
+3
Naive Bayes ist eine einfache und dennoch leistungsstarke Familie von Klassifikationsalgorithmen, die den Satz von Bayes nutzen und häufig für skalierbare Aufgaben wie Spam-Erkennung und Textklassifikation verwendet werden.
Naive Bayes ist eine Familie einfacher, effektiver Klassifikationsalgorithmen, die auf dem Satz von Bayes beruhen und die Annahme der bedingten Unabhängigkeit zwischen den Merkmalen machen. Aufgrund seiner Einfachheit und Skalierbarkeit wird er weit verbreitet für Spam-Erkennung, Textklassifikation und mehr eingesetzt.
Naive Bayes ist eine Familie von Klassifikationsalgorithmen, die auf dem Satz von Bayes basieren und das Prinzip der bedingten Wahrscheinlichkeit anwenden. Das Attribut „naiv“ bezieht sich auf die vereinfachende Annahme, dass alle Merkmale eines Datensatzes unter Berücksichtigung des Klassenlabels voneinander unabhängig sind. Diese Annahme wird in realen Daten zwar oft verletzt, doch Naive-Bayes-Klassifikatoren sind für ihre Einfachheit und Effektivität in verschiedenen Anwendungen wie der Textklassifikation und Spam-Erkennung bekannt.
Bayes’scher Satz
Dieser Satz bildet die Grundlage von Naive Bayes und bietet eine Methode, um die Wahrscheinlichkeit einer Hypothese anhand neuer Beweise zu aktualisieren. Mathematisch wird er wie folgt dargestellt:
wobei ( P(A|B) ) die a-posteriori-Wahrscheinlichkeit, ( P(B|A) ) die Likelihood, ( P(A) ) die a-priori-Wahrscheinlichkeit und ( P(B) ) die Evidenz ist.
Bedingte Unabhängigkeit
Die naive Annahme, dass jedes Merkmal unter Kenntnis des Klassenlabels unabhängig von allen anderen Merkmalen ist. Diese Annahme vereinfacht die Berechnung und ermöglicht eine gute Skalierbarkeit des Algorithmus bei großen Datensätzen.
A-posteriori-Wahrscheinlichkeit
Die Wahrscheinlichkeit des Klassenlabels unter Berücksichtigung der Merkmalswerte, berechnet mit dem Satz von Bayes. Sie ist das zentrale Element bei Vorhersagen mit Naive Bayes.
Typen von Naive-Bayes-Klassifikatoren
Naive-Bayes-Klassifikatoren berechnen für jede Klasse die a-posteriori-Wahrscheinlichkeit anhand eines Merkmalsvektors und wählen die Klasse mit der höchsten Wahrscheinlichkeit aus. Dabei werden folgende Schritte durchlaufen:
Naive-Bayes-Klassifikatoren sind besonders effektiv in folgenden Bereichen:
Betrachten wir eine Spam-Filter-Anwendung mit Naive Bayes. Die Trainingsdaten bestehen aus E-Mails, die als „Spam“ oder „Nicht-Spam“ gekennzeichnet sind. Jede E-Mail wird durch eine Reihe von Merkmalen wie das Vorkommen bestimmter Wörter repräsentiert. Während des Trainings berechnet der Algorithmus die Wahrscheinlichkeit jedes Wortes für jedes Klassenlabel. Für eine neue E-Mail berechnet der Algorithmus die a-posteriori-Wahrscheinlichkeit für „Spam“ und „Nicht-Spam“ und weist das Label mit der höheren Wahrscheinlichkeit zu.
Naive-Bayes-Klassifikatoren können in KI-Systeme und Chatbots integriert werden, um deren Fähigkeiten zur Verarbeitung natürlicher Sprache zu verbessern und die Mensch-Computer-Interaktion zu unterstützen. Zum Beispiel können sie verwendet werden, um die Absicht von Nutzeranfragen zu erkennen, Texte in vordefinierte Kategorien einzuordnen oder ungeeignete Inhalte zu filtern. Diese Funktionalität verbessert die Interaktionsqualität und Relevanz KI-basierter Lösungen. Darüber hinaus eignet sich der Algorithmus aufgrund seiner Effizienz für Echtzeitanwendungen – ein wichtiger Aspekt für KI-Automatisierung und Chatbot-Systeme.
Naive Bayes ist eine Familie einfacher und dennoch leistungsfähiger probabilistischer Algorithmen, die auf dem Satz von Bayes mit starken Unabhängigkeitsannahmen zwischen den Merkmalen beruhen. Aufgrund ihrer Einfachheit und Effektivität werden sie häufig für Klassifikationsaufgaben eingesetzt. Im Folgenden finden Sie einige wissenschaftliche Arbeiten, die verschiedene Anwendungsbereiche und Verbesserungen des Naive-Bayes-Klassifikators beleuchten:
Verbesserung der Spam-Filterung durch die Kombination von Naive Bayes mit einfachen k-nächsten Nachbarn
Autor: Daniel Etzold
Veröffentlicht: 30. November 2003
Diese Arbeit untersucht den Einsatz von Naive Bayes zur E-Mail-Klassifikation und hebt die einfache Implementierung und Effizienz hervor. Die Studie präsentiert empirische Ergebnisse, die zeigen, dass die Kombination von Naive Bayes mit k-nächsten Nachbarn die Genauigkeit des Spam-Filters verbessern kann. Die Kombination führt bei vielen Merkmalen zu leichten Verbesserungen und bei wenigen Merkmalen zu deutlichen Genauigkeitssteigerungen. Zum Paper
.
Lokal gewichteter Naive Bayes
Autoren: Eibe Frank, Mark Hall, Bernhard Pfahringer
Veröffentlicht: 19. Oktober 2012
Diese Arbeit adressiert die Hauptschwäche von Naive Bayes, nämlich die Annahme der Merkmalsunabhängigkeit. Sie stellt eine lokal gewichtete Variante vor, bei der zum Vorhersagezeitpunkt lokale Modelle gelernt werden, wodurch die Unabhängigkeitsannahme abgeschwächt wird. Die Experimente zeigen, dass dieser Ansatz selten zu Genauigkeitsverlusten führt und oft deutliche Verbesserungen bringt. Die Methode wird für ihre konzeptionelle und rechnerische Einfachheit gelobt. Zum Paper
.
Naive-Bayes-Falle-Erkennung für planetare Rover
Autor: Dicong Qiu
Veröffentlicht: 31. Januar 2018
In dieser Studie wird der Einsatz von Naive-Bayes-Klassifikatoren zur Erkennung von Blockierungen bei planetaren Rovern untersucht. Es werden die Kriterien für eine Blockierung definiert und der Einsatz von Naive Bayes zur Detektion solcher Situationen demonstriert. Die Arbeit beschreibt Experimente mit AutoKrawler-Rovern und liefert Einblicke in die Effektivität von Naive Bayes für autonome Rettungsprozesse. Zum Paper
.
Naive Bayes ist eine Familie von Klassifikationsalgorithmen, die auf dem Satz von Bayes basieren und annehmen, dass alle Merkmale unter Berücksichtigung des Klassenlabels voneinander unabhängig sind. Er wird häufig für Textklassifikation, Spam-Filterung und Sentiment-Analyse eingesetzt.
Die wichtigsten Typen sind Gaussian Naive Bayes (für kontinuierliche Merkmale), Multinomial Naive Bayes (für diskrete Merkmale wie Wortanzahlen) und Bernoulli Naive Bayes (für binäre/boole'sche Merkmale).
Naive Bayes ist einfach zu implementieren, recheneffizient, skalierbar für große Datensätze und eignet sich gut für hochdimensionale Daten.
Die Hauptbeschränkung ist die Annahme der Merkmalsunabhängigkeit, die in realen Daten oft nicht zutrifft. Außerdem kann der Algorithmus unbeobachteten Merkmalen die Wahrscheinlichkeit Null zuweisen, was durch Techniken wie Laplace-Glättung gemildert werden kann.
Naive Bayes wird in KI-Systemen und Chatbots für Intent-Erkennung, Textklassifikation, Spam-Filterung und Sentiment-Analyse eingesetzt. Dadurch werden die Fähigkeiten zur Verarbeitung natürlicher Sprache verbessert und Echtzeit-Entscheidungen ermöglicht.
Intelligente Chatbots und KI-Tools unter einem Dach. Verbinden Sie intuitive Bausteine, um Ihre Ideen in automatisierte Flows zu verwandeln.
Ein KI-Klassifizierer ist ein Machine-Learning-Algorithmus, der Eingabedaten Klassenlabels zuweist und Informationen auf Basis von erlernten Mustern aus histori...
Ein Bayessches Netzwerk (BN) ist ein probabilistisches grafisches Modell, das Variablen und deren bedingte Abhängigkeiten über einen gerichteten azyklischen Gra...
Eine Konfusionsmatrix ist ein Werkzeug im maschinellen Lernen zur Bewertung der Leistung von Klassifikationsmodellen. Sie stellt wahre/falsche Positive und Nega...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.