Transformer
Ein Transformer-Modell ist eine Art von neuronalen Netzwerken, die speziell dafür entwickelt wurden, sequenzielle Daten wie Text, Sprache oder Zeitreihendaten z...
3 Min. Lesezeit
Transformer
Neural Networks
+3
Transformer sind bahnbrechende neuronale Netzwerke, die Self-Attention für parallele Datenverarbeitung nutzen und Modelle wie BERT und GPT in NLP, Vision und darüber hinaus antreiben.
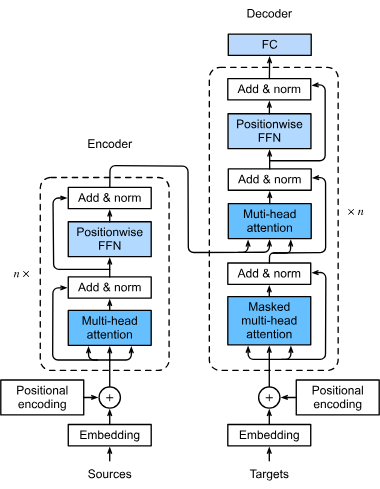
Der erste Schritt in der Verarbeitungspipeline eines Transformer-Modells besteht darin, Wörter oder Tokens einer Eingabesequenz in numerische Vektoren, sogenannte Embeddings, umzuwandeln. Diese Embeddings erfassen semantische Bedeutungen und sind entscheidend, damit das Modell die Beziehungen zwischen Tokens versteht. Diese Transformation ist essenziell, da sie dem Modell ermöglicht, Textdaten in mathematischer Form zu verarbeiten.
Transformer verarbeiten Daten nicht von Natur aus sequentiell; daher wird eine Positionskodierung verwendet, um Informationen über die Position jedes Tokens in der Sequenz einzubringen. Dies ist entscheidend, um die Reihenfolge der Sequenz zu erhalten, was vor allem bei Aufgaben wie maschineller Übersetzung wichtig ist, bei denen der Kontext von der Wortreihenfolge abhängen kann.
Der Multi-Head-Attention-Mechanismus ist eine ausgefeilte Komponente von Transformern, die es dem Modell ermöglicht, sich gleichzeitig auf verschiedene Teile der Eingabesequenz zu konzentrieren. Durch die Berechnung mehrerer Attention-Werte kann das Modell vielfältige Beziehungen und Abhängigkeiten in den Daten erfassen, wodurch seine Fähigkeit zur Erkennung und Erzeugung komplexer Datenmuster verbessert wird.
Transformer folgen typischerweise einer Encoder-Decoder-Architektur:
Nach dem Attention-Mechanismus werden die Daten durch Feedforward-Netzwerke geleitet, die nichtlineare Transformationen anwenden und dem Modell helfen, komplexe Muster zu erlernen. Diese Netzwerke verarbeiten die Daten weiter, um die vom Modell erzeugte Ausgabe zu verfeinern.
Diese Techniken werden eingesetzt, um den Trainingsprozess zu stabilisieren und zu beschleunigen. Layer-Normalisierung sorgt dafür, dass die Ausgaben in einem bestimmten Bereich bleiben und damit ein effizientes Training ermöglicht wird. Residual-Verbindungen erlauben es, dass Gradienten ohne Abschwächung durch das Netzwerk fließen, was das Training tiefer neuronaler Netzwerke verbessert.
Transformer arbeiten mit Datenfolgen, bei denen es sich um Wörter in einem Satz oder andere sequentielle Informationen handeln kann. Sie wenden Self-Attention an, um die Relevanz jedes Teils der Sequenz im Verhältnis zu den anderen zu bestimmen, sodass das Modell sich auf die wichtigsten Elemente konzentrieren kann, die das Ergebnis beeinflussen.
Beim Self-Attention-Mechanismus wird jedes Token in der Sequenz mit jedem anderen Token verglichen, um Attention-Werte zu berechnen. Diese Werte geben an, wie bedeutend jedes Token im Kontext der anderen ist, wodurch das Modell sich auf die relevantesten Teile der Sequenz konzentrieren kann. Dies ist entscheidend, um Kontext und Bedeutung bei Sprachaufgaben zu verstehen.
Diese bilden die Bausteine eines Transformer-Modells und bestehen aus Self-Attention- und Feedforward-Schichten. Mehrere dieser Blöcke werden gestapelt, um Deep-Learning-Modelle zu bilden, die in der Lage sind, komplexe Muster in Daten zu erfassen. Dieses modulare Design ermöglicht es Transformern, effizient mit der Komplexität der Aufgabe zu skalieren.
Transformer sind effizienter als RNNs und CNNs, da sie ganze Sequenzen auf einmal verarbeiten können. Diese Effizienz ermöglicht das Skalieren auf sehr große Modelle wie GPT-3 mit 175 Milliarden Parametern. Die Skalierbarkeit von Transformern macht sie besonders geeignet für den Umgang mit großen Datenmengen.
Traditionelle Modelle haben Schwierigkeiten, langfristige Abhängigkeiten aufgrund ihrer sequentiellen Natur zu erfassen. Transformer überwinden diese Einschränkung durch Self-Attention, die alle Teile der Sequenz gleichzeitig berücksichtigen kann. Dies macht sie besonders effektiv bei Aufgaben, bei denen das Verständnis von Kontext über lange Textpassagen wichtig ist.
Obwohl ursprünglich für NLP entwickelt, wurden Transformer für verschiedene Anwendungen angepasst, darunter Computer Vision, Protein-Faltung und sogar Zeitreihenprognosen. Diese Vielseitigkeit zeigt die breite Anwendbarkeit von Transformern in unterschiedlichen Bereichen.
Transformer haben die Leistung von NLP-Aufgaben wie Übersetzung, Zusammenfassung und Sentiment-Analyse erheblich verbessert. Modelle wie BERT und GPT nutzen die Transformer-Architektur, um menschenähnlichen Text zu verstehen und zu generieren und setzen damit neue Maßstäbe im NLP.
Bei der maschinellen Übersetzung überzeugen Transformer, indem sie den Kontext der Wörter innerhalb eines Satzes erfassen und im Vergleich zu früheren Methoden genauere Übersetzungen ermöglichen. Ihre Fähigkeit, ganze Sätze gleichzeitig zu verarbeiten, sorgt für kohärentere und kontextuell passendere Übersetzungen.
Transformer können die Sequenzen von Aminosäuren in Proteinen modellieren und helfen so bei der Vorhersage von Proteinstrukturen, was für die Wirkstoffforschung und das Verständnis biologischer Prozesse entscheidend ist. Diese Anwendung unterstreicht das Potenzial von Transformern in der wissenschaftlichen Forschung.
Durch die Anpassung der Transformer-Architektur ist es möglich, zukünftige Werte in Zeitreihendaten wie Stromnachfrageprognosen vorherzusagen, indem vergangene Sequenzen analysiert werden. Dies eröffnet neue Möglichkeiten für Transformer in Bereichen wie Finanzen und Ressourcenmanagement.
BERT-Modelle sind darauf ausgelegt, den Kontext eines Wortes zu erfassen, indem sie sowohl die vorhergehenden als auch die nachfolgenden Wörter betrachten, und sind daher besonders effektiv bei Aufgaben, die ein Verständnis der Wortbeziehungen im Satz erfordern. Dieser bidirektionale Ansatz ermöglicht es BERT, den Kontext umfassender zu erfassen als unidirektionale Modelle.
GPT-Modelle sind autoregressiv und generieren Text, indem sie das nächste Wort in einer Sequenz auf Grundlage der vorherigen Wörter vorhersagen. Sie werden häufig für Anwendungen wie Textvervollständigung und Dialoggenerierung eingesetzt und zeigen ihre Fähigkeit, menschenähnlichen Text zu erzeugen.
Ursprünglich für NLP entwickelt, wurden Transformer für Aufgaben der Computer Vision angepasst. Vision Transformer verarbeiten Bilddaten als Sequenzen und ermöglichen es, Transformer-Techniken auch auf visuelle Eingaben anzuwenden. Diese Anpassung hat Fortschritte in der Bilderkennung und -verarbeitung ermöglicht.
Das Training großer Transformermodelle erfordert erhebliche Rechenressourcen, oft unter Einsatz großer Datensätze und leistungsstarker Hardware wie GPUs. Dies stellt eine Herausforderung hinsichtlich Kosten und Zugänglichkeit für viele Organisationen dar.
Mit der zunehmenden Verbreitung von Transformern gewinnen Fragen wie Vorurteile in KI-Modellen und der ethische Umgang mit KI-generierten Inhalten an Bedeutung. Forschende arbeiten an Methoden, um diese Herausforderungen zu verringern und eine verantwortungsvolle KI-Entwicklung zu gewährleisten, was die Notwendigkeit ethischer Rahmenbedingungen in der KI-Forschung unterstreicht.
Die Vielseitigkeit von Transformern eröffnet immer neue Wege für Forschung und Anwendung, von der Verbesserung KI-gestützter Chatbots bis hin zur Optimierung der Datenanalyse in Bereichen wie Gesundheitswesen und Finanzen. Die Zukunft der Transformer hält spannende Möglichkeiten für Innovationen in verschiedensten Branchen bereit.
Abschließend lässt sich sagen, dass Transformer einen bedeutenden Fortschritt in der KI-Technologie darstellen und beispiellose Fähigkeiten bei der Verarbeitung sequentieller Daten bieten. Ihre innovative Architektur und Effizienz setzen neue Maßstäbe im Feld und treiben KI-Anwendungen zu neuen Höhen. Ob Sprachverständnis, wissenschaftliche Forschung oder visuelle Datenverarbeitung – Transformer definieren weiterhin, was im Bereich der künstlichen Intelligenz möglich ist.
Transformer haben das Gebiet der künstlichen Intelligenz, insbesondere im Bereich der Verarbeitung natürlicher Sprache und des Verständnisses, revolutioniert. Die Publikation „AI Thinking: A framework for rethinking artificial intelligence in practice“ von Denis Newman-Griffis (veröffentlicht 2024) stellt ein neuartiges konzeptionelles Rahmenwerk namens AI Thinking vor. Dieses Modell bildet zentrale Entscheidungen und Überlegungen beim KI-Einsatz aus verschiedenen disziplinären Perspektiven ab und behandelt Kompetenzen wie die Motivation für den KI-Einsatz, die Entwicklung von KI-Methoden und die Einbettung von KI in soziotechnische Kontexte. Ziel ist es, Disziplinengrenzen zu überbrücken und die Zukunft der KI in der Praxis neu zu gestalten. Mehr lesen .
Ein weiterer wichtiger Beitrag ist „Artificial intelligence and the transformation of higher education institutions“ von Evangelos Katsamakas et al. (veröffentlicht 2024), das mit einem Komplexitätssystem-Ansatz die kausalen Rückkopplungsmechanismen der KI-Transformation an Hochschulen untersucht. Die Studie diskutiert die treibenden Kräfte der KI-Transformation und deren Auswirkung auf die Wertschöpfung und betont die Notwendigkeit für Hochschulen, sich an technologische KI-Fortschritte anzupassen sowie akademische Integrität und Beschäftigung zu steuern. Mehr lesen .
Im Bereich der Softwareentwicklung untersucht die Publikation „Can Artificial Intelligence Transform DevOps?“ von Mamdouh Alenezi und Kollegen (veröffentlicht 2022) die Schnittstelle zwischen KI und DevOps. Die Studie hebt hervor, wie KI die Funktionalität von DevOps-Prozessen verbessern und die effiziente Softwarebereitstellung erleichtern kann. Sie unterstreicht die praktischen Implikationen für Softwareentwickler und Unternehmen, KI zu nutzen, um DevOps-Praktiken zu transformieren. Mehr lesen
Transformer sind eine 2017 eingeführte neuronale Netzwerkarchitektur, die Self-Attention-Mechanismen zur parallelen Verarbeitung sequentieller Daten nutzt. Sie haben die künstliche Intelligenz, insbesondere im Bereich der Verarbeitung natürlicher Sprache und der Computer Vision, revolutioniert.
Im Gegensatz zu RNNs und CNNs verarbeiten Transformer alle Elemente einer Sequenz gleichzeitig mithilfe von Self-Attention. Dadurch ermöglichen sie eine höhere Effizienz, Skalierbarkeit und die Fähigkeit, langfristige Abhängigkeiten zu erfassen.
Transformer werden häufig in NLP-Aufgaben wie Übersetzung, Zusammenfassung und Sentiment-Analyse eingesetzt sowie in Computer Vision, der Vorhersage von Proteinstrukturen und der Zeitreihenprognose.
Bekannte Transformermodelle sind BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) und Vision Transformers für die Bildverarbeitung.
Für das Training und den Einsatz von Transformern werden erhebliche Rechenressourcen benötigt. Zudem stellen sich ethische Fragen wie mögliche Verzerrungen in KI-Modellen und der verantwortungsvolle Umgang mit generierten KI-Inhalten.
Intelligente Chatbots und KI-Tools unter einem Dach. Verbinden Sie intuitive Bausteine, um Ihre Ideen in automatisierte Flows zu verwandeln.
Ein Transformer-Modell ist eine Art von neuronalen Netzwerken, die speziell dafür entwickelt wurden, sequenzielle Daten wie Text, Sprache oder Zeitreihendaten z...
Ein Generativer Vortrainierter Transformer (GPT) ist ein KI-Modell, das Deep-Learning-Techniken nutzt, um Texte zu erzeugen, die menschlichem Schreiben sehr ähn...
Long Short-Term Memory (LSTM) ist eine spezialisierte Architektur von Rekurrenten Neuronalen Netzwerken (RNN), die darauf ausgelegt ist, langfristige Abhängigke...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.