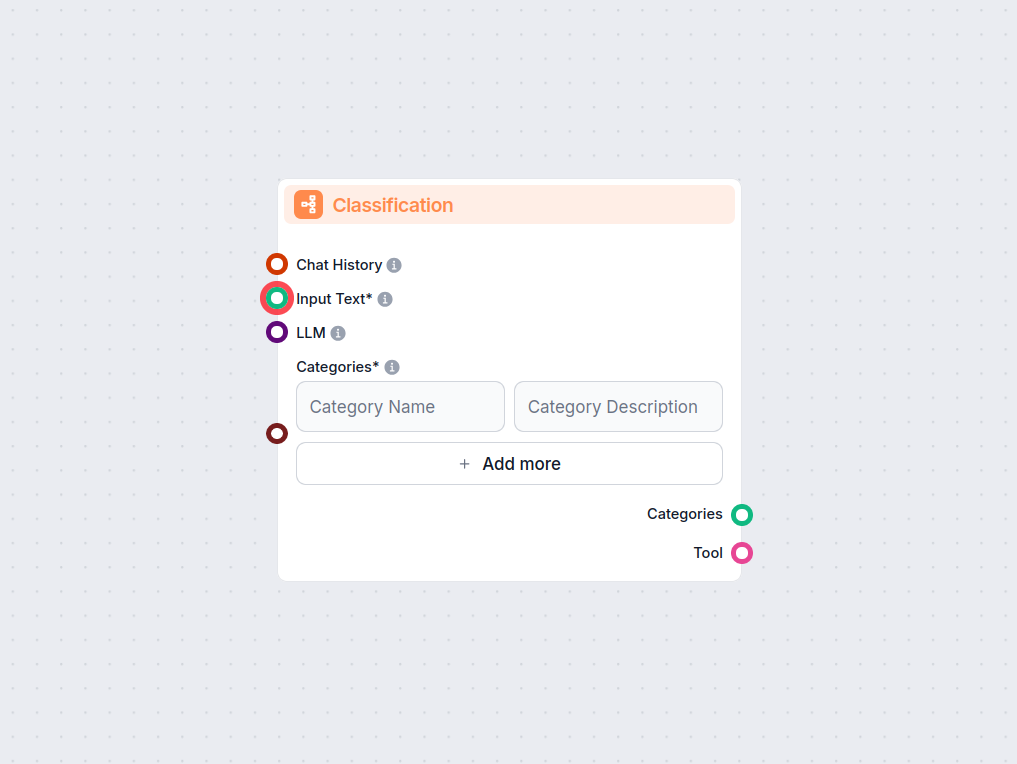
Textklassifikation
Ermöglichen Sie automatisierte Textkategorisierung in Ihren Workflows mit der Textklassifikation-Komponente für FlowHunt. Klassifizieren Sie Eingabetexte mühelo...
3 Min. Lesezeit
AI
Classification
+3
Ermöglichen Sie automatisierte Textkategorisierung in Ihren Workflows mit der Textklassifikation-Komponente für FlowHunt. Klassifizieren Sie Eingabetexte mühelo...
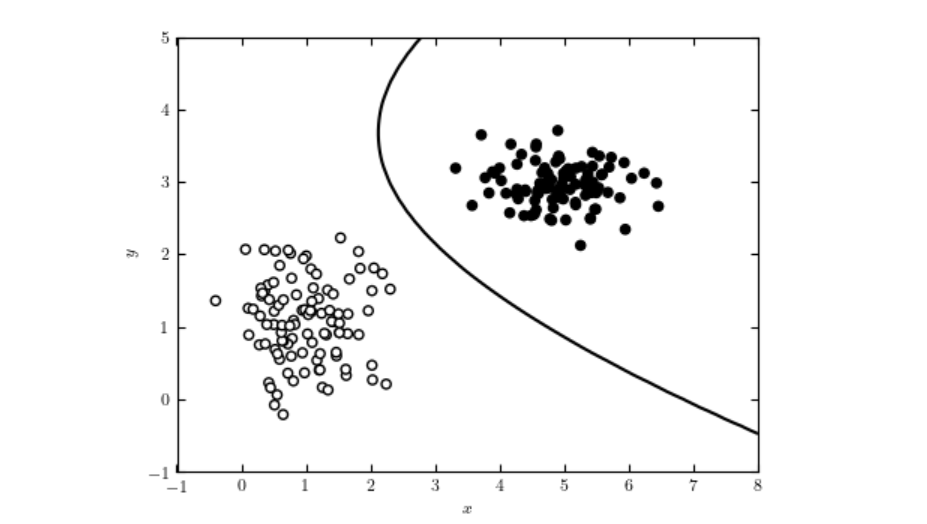
Erfahren Sie mehr über diskriminative KI-Modelle – maschinelle Lernmodelle, die sich auf Klassifikation und Regression konzentrieren, indem sie Entscheidungsgre...
Ein Entscheidungsbaum ist ein leistungsstarkes und intuitives Werkzeug für Entscheidungsfindung und prädiktive Analysen, das sowohl bei Klassifizierungs- als au...
Die Fläche unter der Kurve (AUC) ist eine grundlegende Kennzahl im maschinellen Lernen, die zur Bewertung der Leistungsfähigkeit von binären Klassifikationsmode...
Gradient Boosting ist eine leistungsstarke Ensemble-Methode des maschinellen Lernens für Regression und Klassifikation. Sie baut Modelle sequenziell auf, typisc...
Der k-nächste Nachbarn (KNN) Algorithmus ist ein nichtparametrischer, überwachter Lernalgorithmus, der für Klassifizierungs- und Regressionsaufgaben im maschine...
Ein KI-Klassifizierer ist ein Machine-Learning-Algorithmus, der Eingabedaten Klassenlabels zuweist und Informationen auf Basis von erlernten Mustern aus histori...
Eine Konfusionsmatrix ist ein Werkzeug im maschinellen Lernen zur Bewertung der Leistung von Klassifikationsmodellen. Sie stellt wahre/falsche Positive und Nega...
Kreuzentropie ist ein zentrales Konzept sowohl in der Informationstheorie als auch im maschinellen Lernen und dient als Maß zur Bestimmung der Divergenz zwische...
LightGBM, oder Light Gradient Boosting Machine, ist ein fortschrittliches Gradient-Boosting-Framework, das von Microsoft entwickelt wurde. Es ist für leistungss...
Log Loss, oder logarithmischer/Cross-Entropy-Loss, ist eine wichtige Kennzahl zur Bewertung der Leistung von Machine-Learning-Modellen – insbesondere für binäre...
Naive Bayes ist eine Familie von Klassifikationsalgorithmen, die auf dem Satz von Bayes basieren und bedingte Wahrscheinlichkeiten unter der vereinfachenden Ann...
Entdecken Sie Recall im Machine Learning: ein entscheidender Messwert zur Bewertung der Modellleistung, insbesondere bei Klassifikationsaufgaben, bei denen das ...
Die Top-k-Genauigkeit ist eine Evaluationsmetrik im maschinellen Lernen, die prüft, ob die wahre Klasse unter den k am höchsten vorhergesagten Klassen ist, und ...
Überwachtes Lernen ist ein grundlegender Ansatz im maschinellen Lernen und in der künstlichen Intelligenz, bei dem Algorithmen aus gekennzeichneten Datensätzen ...
Überwachtes Lernen ist ein grundlegendes Konzept der KI und des maschinellen Lernens, bei dem Algorithmen mit beschrifteten Daten trainiert werden, um genaue Vo...