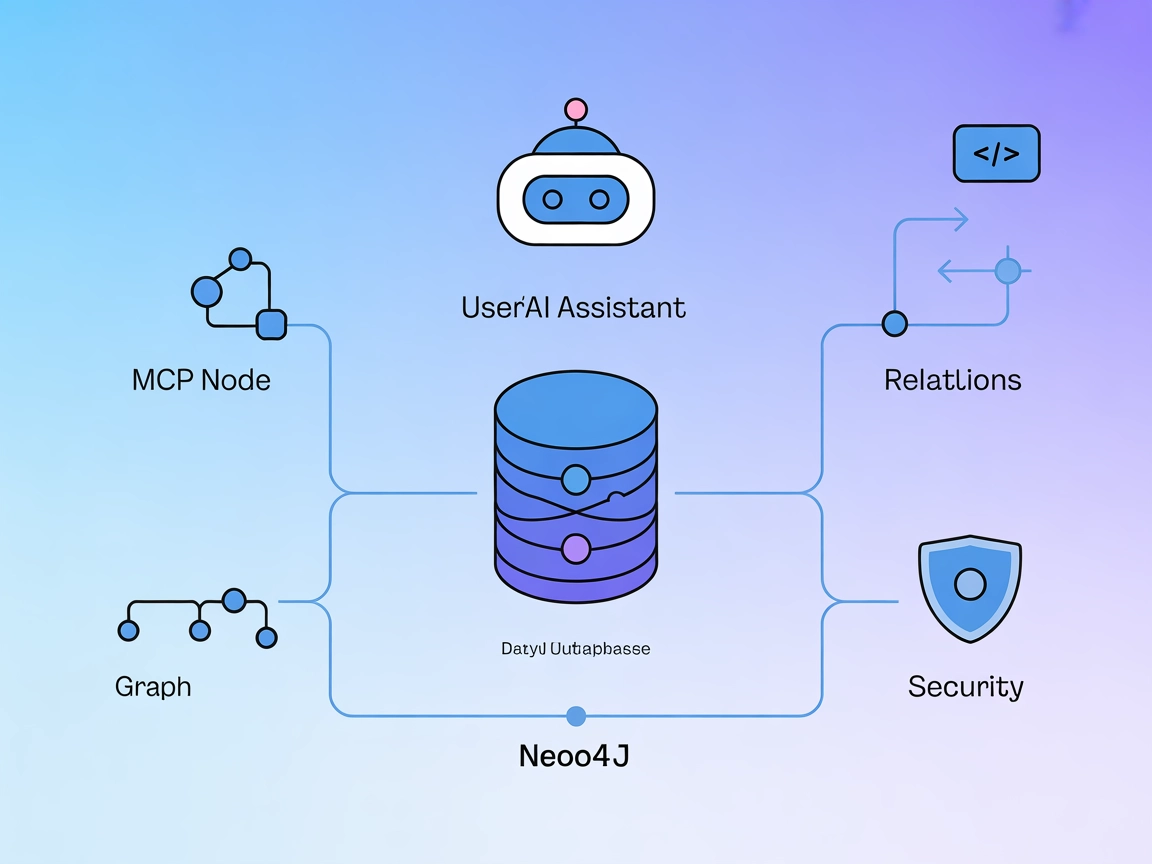
Neo4j MCP Server Integration
Der Neo4j MCP Server verbindet KI-Assistenten mit der Neo4j-Graphdatenbank und ermöglicht sichere, natürlichsprachliche Graphoperationen, Cypher-Abfragen sowie ...
4 Min. Lesezeit
AI
Graph Database
+5
Der Neo4j MCP Server verbindet KI-Assistenten mit der Neo4j-Graphdatenbank und ermöglicht sichere, natürlichsprachliche Graphoperationen, Cypher-Abfragen sowie ...
Der NASA MCP-Server bietet eine einheitliche Schnittstelle für KI-Modelle und Entwickler, um auf über 20 NASA-Datenquellen zuzugreifen. Er standardisiert das Ab...
Der Data Exploration MCP Server verbindet KI-Assistenten mit externen Datensätzen für interaktive Analysen. Er ermöglicht es Nutzern, CSV- und Kaggle-Datensätze...
Der MCP Code Executor MCP Server ermöglicht FlowHunt und anderen LLM-basierten Tools das sichere Ausführen von Python-Code in isolierten Umgebungen, das Verwalt...
Der Reexpress MCP Server bringt statistische Verifikation in LLM-Workflows. Mit dem Similarity-Distance-Magnitude (SDM) Estimator liefert er robuste Vertrauenss...
Der Databricks Genie MCP Server ermöglicht es großen Sprachmodellen, über die Genie API mit Databricks-Umgebungen zu interagieren. Er unterstützt konversationel...
JupyterMCP ermöglicht die nahtlose Integration von Jupyter Notebook (6.x) mit KI-Assistenten über das Model Context Protocol. Automatisieren Sie Codeausführung,...
Anaconda ist eine umfassende, quelloffene Distribution von Python und R, die entwickelt wurde, um das Paketmanagement und die Bereitstellung für wissenschaftlic...
Das angepasste R-Quadrat ist ein statistisches Maß, das zur Bewertung der Güte der Anpassung eines Regressionsmodells verwendet wird. Es berücksichtigt die Anza...
Erkunden Sie Bias in KI: Verstehen Sie dessen Ursachen, Auswirkungen auf das maschinelle Lernen, praxisnahe Beispiele und Strategien zur Minderung, um faire und...
BigML ist eine Machine-Learning-Plattform, die darauf ausgelegt ist, die Erstellung und Bereitstellung von Vorhersagemodellen zu vereinfachen. Gegründet im Jahr...
Data Mining ist ein anspruchsvoller Prozess, bei dem große Mengen an Rohdaten analysiert werden, um Muster, Zusammenhänge und Erkenntnisse zu entdecken, die Unt...
Datenbereinigung ist der entscheidende Prozess zur Erkennung und Behebung von Fehlern oder Inkonsistenzen in Daten, um deren Qualität zu verbessern und Genauigk...
Die Dimensionsreduktion ist eine entscheidende Technik in der Datenverarbeitung und im maschinellen Lernen, bei der die Anzahl der Eingabevariablen in einem Dat...
Ein Entscheidungsbaum ist ein leistungsstarkes und intuitives Werkzeug für Entscheidungsfindung und prädiktive Analysen, das sowohl bei Klassifizierungs- als au...
Entdecken Sie, wie Feature Engineering und Extraktion die Leistung von KI-Modellen verbessern, indem Rohdaten in wertvolle Erkenntnisse umgewandelt werden. Lern...
Die Fläche unter der Kurve (AUC) ist eine grundlegende Kennzahl im maschinellen Lernen, die zur Bewertung der Leistungsfähigkeit von binären Klassifikationsmode...
Google Colaboratory (Google Colab) ist eine cloudbasierte Jupyter-Notebook-Plattform von Google, die es Nutzern ermöglicht, Python-Code im Browser auszuführen, ...
Gradient Boosting ist eine leistungsstarke Ensemble-Methode des maschinellen Lernens für Regression und Klassifikation. Sie baut Modelle sequenziell auf, typisc...
Jupyter Notebook ist eine Open-Source-Webanwendung, die es Nutzern ermöglicht, Dokumente mit ausführbarem Code, Gleichungen, Visualisierungen und erklärendem Te...
K-Means-Clustering ist ein beliebter unüberwachter Machine-Learning-Algorithmus zur Aufteilung von Datensätzen in eine vordefinierte Anzahl von unterschiedliche...
Der k-nächste Nachbarn (KNN) Algorithmus ist ein nichtparametrischer, überwachter Lernalgorithmus, der für Klassifizierungs- und Regressionsaufgaben im maschine...
Kaggle ist eine Online-Community und Plattform für Data Scientists und Machine-Learning-Ingenieure, um zusammenzuarbeiten, zu lernen, an Wettbewerben teilzunehm...
Die kausale Inferenz ist ein methodischer Ansatz, um Ursache-Wirkungs-Beziehungen zwischen Variablen zu bestimmen. Sie ist in den Wissenschaften entscheidend, u...
Ein KI-Datenanalyst verbindet traditionelle Datenanalysefähigkeiten mit Künstlicher Intelligenz (KI) und Maschinellem Lernen (ML), um Erkenntnisse zu gewinnen, ...
Ein KI-Klassifizierer ist ein Machine-Learning-Algorithmus, der Eingabedaten Klassenlabels zuweist und Informationen auf Basis von erlernten Mustern aus histori...
Die lineare Regression ist eine grundlegende Analysetechnik in der Statistik und im maschinellen Lernen, die die Beziehung zwischen abhängigen und unabhängigen ...
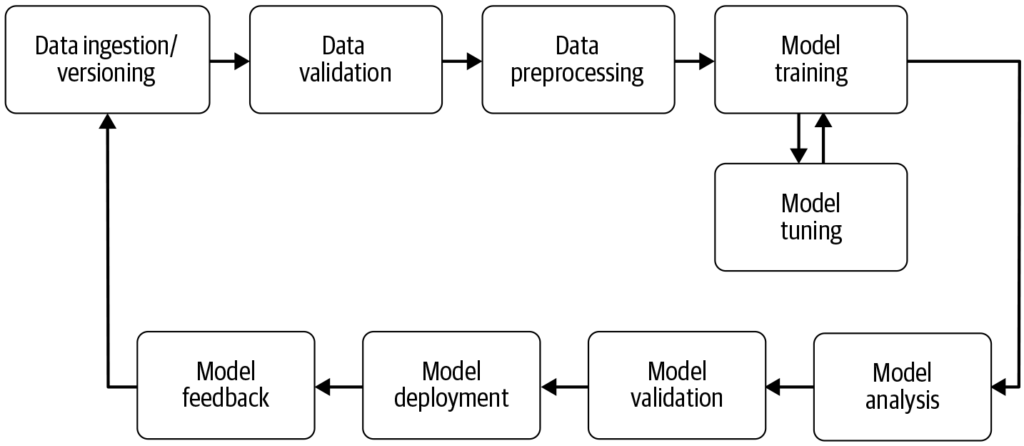
Eine Machine-Learning-Pipeline ist ein automatisierter Workflow, der die Entwicklung, das Training, die Evaluierung und den Einsatz von Machine-Learning-Modelle...
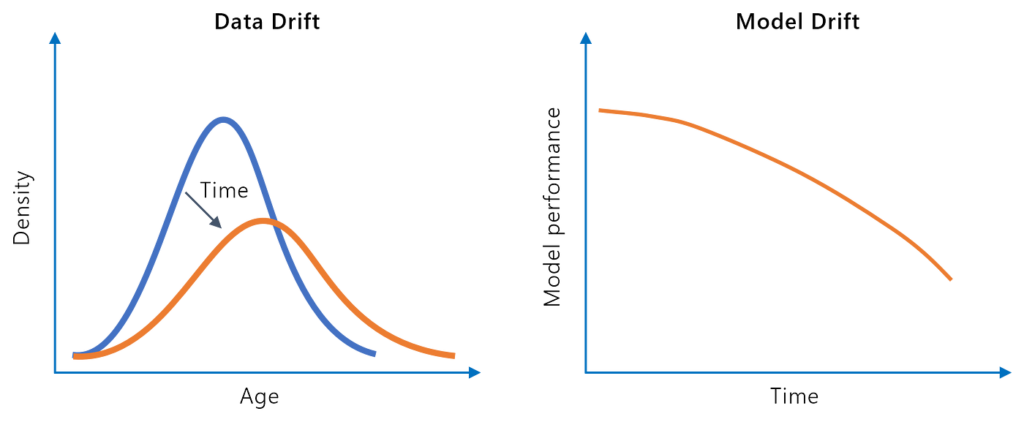
Model Drift, auch Modellverfall genannt, bezeichnet den Rückgang der Vorhersagegenauigkeit eines Machine-Learning-Modells im Laufe der Zeit aufgrund von Verände...
Die Modell-Verkettung ist eine Methode des maschinellen Lernens, bei der mehrere Modelle sequenziell miteinander verbunden werden, sodass die Ausgabe eines Mode...
NumPy ist eine Open-Source-Python-Bibliothek, die für numerische Berechnungen unerlässlich ist und effiziente Array-Operationen und mathematische Funktionen ber...
Pandas ist eine Open-Source-Bibliothek für Datenmanipulation und -analyse in Python, bekannt für ihre Vielseitigkeit, robuste Datenstrukturen und Benutzerfreund...
Prädiktive Modellierung ist ein anspruchsvoller Prozess in der Datenwissenschaft und Statistik, der zukünftige Ergebnisse durch die Analyse historischer Datenmu...
Scikit-learn ist eine leistungsstarke Open-Source-Bibliothek für maschinelles Lernen in Python, die einfache und effiziente Werkzeuge für die prädiktive Datenan...
Semi-Supervised Learning (SSL) ist eine Machine-Learning-Technik, die sowohl gelabelte als auch ungelabelte Daten nutzt, um Modelle zu trainieren. Sie ist ideal...