Abfrageerweiterung
Die Abfrageerweiterung in FlowHunt verbessert das Verständnis des Chatbots, indem Synonyme gefunden, Rechtschreibfehler korrigiert und konsistente, präzise Antw...
3 Min. Lesezeit
AI
Chatbot
+3
Die Abfrageerweiterung in FlowHunt verbessert das Verständnis des Chatbots, indem Synonyme gefunden, Rechtschreibfehler korrigiert und konsistente, präzise Antw...
Entdecken Sie, wie Ask Engine Optimization (AEO) den Fokus von traditionellem SEO auf die direkte Beantwortung von Nutzerfragen verlagert, Inhalte für KI- und S...
Deep Learning ist ein Teilbereich des maschinellen Lernens in der Künstlichen Intelligenz (KI), der die Arbeitsweise des menschlichen Gehirns beim Verarbeiten v...
Die Erkennung benannter Entitäten (NER) ist ein zentrales Teilgebiet des Natural Language Processing (NLP) in der KI. Sie konzentriert sich darauf, Entitäten in...
Der Flesch-Lesbarkeitsindex ist eine Lesbarkeitsformel, die bewertet, wie leicht ein Text zu verstehen ist. Entwickelt von Rudolf Flesch in den 1940er Jahren, w...
Was ist ein Heteronym? Ein Heteronym ist ein einzigartiges sprachliches Phänomen, bei dem zwei oder mehr Wörter die gleiche Schreibweise haben, aber unterschied...
KI-basiertes Studenten-Feedback nutzt künstliche Intelligenz, um personalisierte, sofortige evaluative Einsichten und Vorschläge für Studierende bereitzustellen...
Ein Metaprompt in der künstlichen Intelligenz ist eine hochrangige Anweisung, die dazu dient, andere Prompts für große Sprachmodelle (LLMs) zu generieren oder z...
Erfahren Sie mehr über Mistral AI und die LLM-Modelle, die sie anbieten. Entdecken Sie, wie diese Modelle eingesetzt werden und was sie besonders macht.
Eine Ontologie in der Künstlichen Intelligenz ist eine formale Spezifikation einer geteilten Konzeptualisierung, die Klassen, Eigenschaften und Beziehungen defi...
Die Sprachverarbeitung (Natural Language Processing, NLP) ermöglicht es Computern, menschliche Sprache mithilfe von Computerlinguistik, maschinellem Lernen und ...
Ein Token im Kontext großer Sprachmodelle (LLMs) ist eine Zeichenfolge, die das Modell in numerische Repräsentationen umwandelt, um eine effiziente Verarbeitung...
Natural Language Understanding (NLU) ist ein Teilbereich der KI, der darauf abzielt, Maschinen in die Lage zu versetzen, menschliche Sprache kontextbezogen zu v...
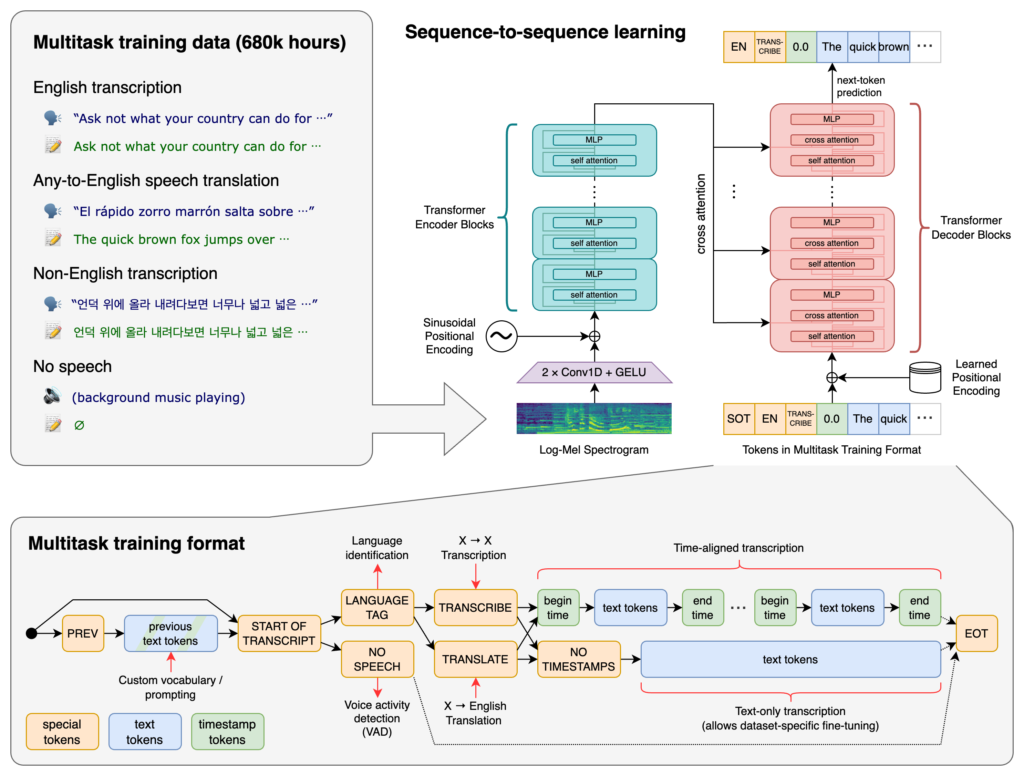
OpenAI Whisper ist ein fortschrittliches automatisches Spracherkennungssystem (ASR), das gesprochene Sprache in Text umwandelt, 99 Sprachen unterstützt, robust ...