AI-Tool zur Bildbeschriftungsgenerierung
Entdecken Sie FlowHunts KI-gestützten Bildbeschriftungs-Generator. Erstellen Sie sofort ansprechende, relevante Bildunterschriften mit individuell anpassbaren T...
2 Min. Lesezeit
AI
Image Captioning
+6
Entdecken Sie FlowHunts KI-gestützten Bildbeschriftungs-Generator. Erstellen Sie sofort ansprechende, relevante Bildunterschriften mit individuell anpassbaren T...
Aktivierungsfunktionen sind grundlegend für künstliche neuronale Netzwerke, da sie Nichtlinearität einführen und das Erlernen komplexer Muster ermöglichen. Dies...
Das assoziative Gedächtnis in der Künstlichen Intelligenz (KI) ermöglicht es Systemen, Informationen auf Grundlage von Mustern und Assoziationen abzurufen und a...
Backpropagation ist ein Algorithmus zum Trainieren künstlicher neuronaler Netze, indem Gewichte angepasst werden, um den Vorhersagefehler zu minimieren. Erfahre...
Batch-Normalisierung ist eine transformative Technik im Deep Learning, die den Trainingsprozess von neuronalen Netzwerken erheblich verbessert, indem sie intern...
Bidirektionales Long Short-Term Memory (BiLSTM) ist eine fortschrittliche Art von rekurrenter neuronaler Netzwerkarchitektur (RNN), die sequenzielle Daten in Vo...
Chainer ist ein Open-Source-Deep-Learning-Framework, das eine flexible, intuitive und leistungsstarke Plattform für neuronale Netzwerke bietet. Es zeichnet sich...
Ein Deep Belief Network (DBN) ist ein anspruchsvolles generatives Modell, das tiefe Architekturen und Restricted Boltzmann Machines (RBMs) nutzt, um hierarchisc...
Deep Learning ist ein Teilbereich des maschinellen Lernens in der Künstlichen Intelligenz (KI), der die Arbeitsweise des menschlichen Gehirns beim Verarbeiten v...
Dropout ist eine Regularisierungstechnik in der KI, insbesondere in neuronalen Netzwerken, die Überanpassung bekämpft, indem während des Trainings zufällig Neur...
Ein Generatives Gegnerisches Netzwerk (GAN) ist ein maschinelles Lern-Framework mit zwei neuronalen Netzwerken – einem Generator und einem Diskriminator –, die ...
Der Gradientenabstieg ist ein grundlegender Optimierungsalgorithmus, der in Machine Learning und Deep Learning weit verbreitet ist, um Kosten- oder Verlustfunkt...
Entdecken Sie die fortschrittlichen Fähigkeiten des Claude 3 KI-Agenten. Diese ausführliche Analyse zeigt, wie Claude 3 über die reine Textgenerierung hinausgeh...
Keras ist eine leistungsstarke und benutzerfreundliche Open-Source-API für hochentwickelte neuronale Netzwerke, geschrieben in Python und lauffähig auf TensorFl...
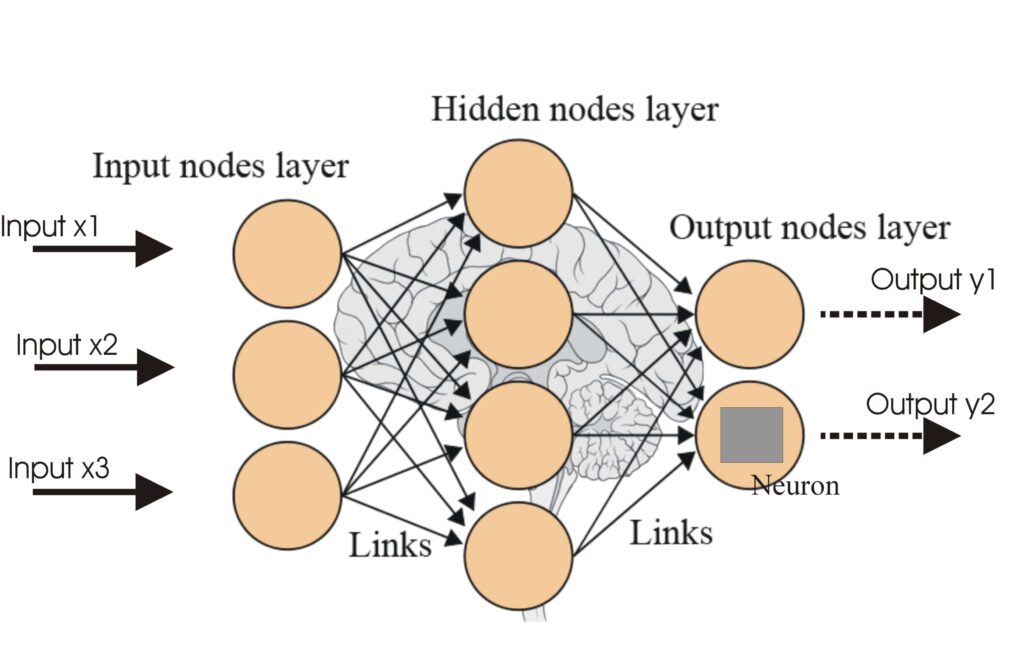
Künstliche Neuronale Netze (ANNs) sind eine Untergruppe von Machine-Learning-Algorithmen, die dem menschlichen Gehirn nachempfunden sind. Diese Rechenmodelle be...
Long Short-Term Memory (LSTM) ist eine spezialisierte Architektur von Rekurrenten Neuronalen Netzwerken (RNN), die darauf ausgelegt ist, langfristige Abhängigke...
Mustererkennung ist ein rechnergestützter Prozess zur Identifizierung von Mustern und Regelmäßigkeiten in Daten, der in Bereichen wie KI, Informatik, Psychologi...
Apache MXNet ist ein Open-Source-Deep-Learning-Framework, das für effizientes und flexibles Training sowie die Bereitstellung tiefer neuronaler Netze entwickelt...
Ein neuronales Netzwerk, oder künstliches neuronales Netzwerk (KNN), ist ein vom menschlichen Gehirn inspiriertes Rechenmodell, das in KI und maschinellem Lerne...
Erfahren Sie, wie NVIDIAs Blackwell-System eine neue Ära des beschleunigten Computings einläutet und Branchen durch fortschrittliche GPU-Technologie, KI und mas...
Regularisierung in der künstlichen Intelligenz (KI) bezeichnet eine Reihe von Techniken, die dazu dienen, Überanpassung (Overfitting) in Machine-Learning-Modell...
Rekurrente neuronale Netzwerke (RNNs) sind eine fortschrittliche Klasse künstlicher neuronaler Netzwerke, die zur Verarbeitung sequentieller Daten entwickelt wu...
Torch ist eine Open-Source-Machine-Learning-Bibliothek und ein wissenschaftliches Computing-Framework auf Basis von Lua, optimiert für Deep-Learning- und KI-Auf...
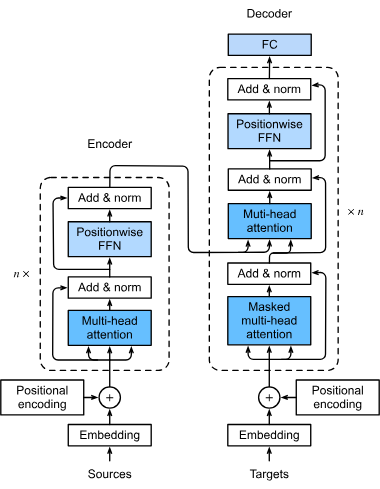
Ein Transformer-Modell ist eine Art von neuronalen Netzwerken, die speziell dafür entwickelt wurden, sequenzielle Daten wie Text, Sprache oder Zeitreihendaten z...
Transformer sind eine revolutionäre neuronale Netzwerkarchitektur, die die künstliche Intelligenz, insbesondere im Bereich der Verarbeitung natürlicher Sprache,...
Erkunden Sie die Grundlagen des KI-Reasonings, einschließlich seiner Typen, Bedeutung und realen Anwendungen. Erfahren Sie, wie KI menschliches Denken nachahmt,...