Modelo de lenguaje grande (LLM)
Un modelo de lenguaje grande (LLM) es un tipo de inteligencia artificial entrenada con grandes cantidades de datos textuales para comprender, generar y manipula...
10 min de lectura
AI
Large Language Model
+4

FlowHunt prueba y clasifica los principales LLMs—including GPT-4, Claude 3, Llama 3 y Grok—para redacción de contenidos, evaluando legibilidad, tono, originalidad y uso de palabras clave para ayudarte a elegir el mejor modelo según tus necesidades.
Los Modelos de Lenguaje Grandes (LLMs) son herramientas de IA de vanguardia que están transformando la forma en que creamos y consumimos contenido. Antes de profundizar en las diferencias entre los LLMs individuales, es importante comprender qué les permite crear textos similares a los humanos con tanta facilidad.
Los LLMs se entrenan con enormes conjuntos de datos, lo que les ayuda a captar el contexto, la semántica y la sintaxis. Según la cantidad de datos, pueden predecir correctamente la siguiente palabra en una oración, hilando palabras en textos comprensibles. Una de las razones de su eficacia es la arquitectura transformer. Este mecanismo de auto-atención utiliza redes neuronales para procesar la sintaxis y la semántica del texto. Esto significa que los LLMs pueden manejar una amplia gama de tareas complejas con facilidad.
Los Modelos de Lenguaje Grandes (LLMs) han transformado la manera en que las empresas abordan la creación de contenidos. Gracias a su capacidad para producir textos personalizados y optimizados, los LLMs generan contenido como emails, páginas de aterrizaje y publicaciones para redes sociales a partir de instrucciones en lenguaje humano.
Esto es lo que los LLMs pueden aportar a los redactores de contenido:
Además, el futuro de los LLMs es prometedor. Los avances tecnológicos probablemente mejorarán su precisión y capacidades multimodales. Esta expansión de aplicaciones influirá significativamente en diversas industrias.
Comienza tu prueba gratuita hoy y ve resultados en días.
Aquí tienes un vistazo rápido a los LLMs populares que vamos a probar:
| Modelo | Fortalezas Únicas |
|---|---|
| GPT-4 | Versátil en varios estilos de escritura |
| Claude 3 | Destaca en tareas creativas y contextuales |
| Llama 3.2 | Conocido por su eficiencia resumiendo textos |
| Grok | Destaca por su tono relajado y humorístico |
Al elegir un LLM, es esencial considerar tus necesidades de creación de contenido. Cada modelo ofrece algo único, desde manejar tareas complejas hasta generar contenido creativo con IA. Antes de probarlos, resumamos brevemente cada uno para ver cómo pueden beneficiar tu proceso de creación.
Características clave:
Métricas de rendimiento:
Fortalezas:
Desafíos:
En general, GPT-4 es una herramienta poderosa para empresas que buscan mejorar la creación de contenidos y estrategias de análisis de datos.
Características clave:
Fortalezas:
Desafíos:
Características clave:
Fortalezas:
Desafíos:
Llama 3 destaca como un LLM open-source robusto y versátil, prometiendo avances en capacidades de IA pero presentando ciertos retos para los usuarios.
Características clave:
Fortalezas:
Desafíos:
En resumen, aunque xAI Grok ofrece funciones interesantes y goza de visibilidad mediática, enfrenta desafíos importantes en popularidad y rendimiento dentro del competitivo mundo de los modelos de lenguaje.
Vamos directo a las pruebas. Clasificaremos los modelos usando una salida básica de redacción de blog. Todas las pruebas se realizaron en FlowHunt, cambiando solo el modelo LLM.
Áreas clave de enfoque:
Prompt de prueba:
Escribe un blog titulado “10 formas fáciles de vivir de manera sostenible sin gastar mucho dinero”. El tono debe ser práctico y accesible, enfocado en consejos accionables y realistas para personas ocupadas. Destaca “sostenibilidad con bajo presupuesto” como palabra clave principal. Incluye ejemplos para situaciones cotidianas como compras, uso de energía y hábitos personales. Finaliza con un llamado motivador a que los lectores pongan en práctica al menos un consejo hoy.
Nota: El flujo está limitado a una salida de aproximadamente 500 palabras. Si notas que los resultados son apresurados o poco profundos, es intencional.
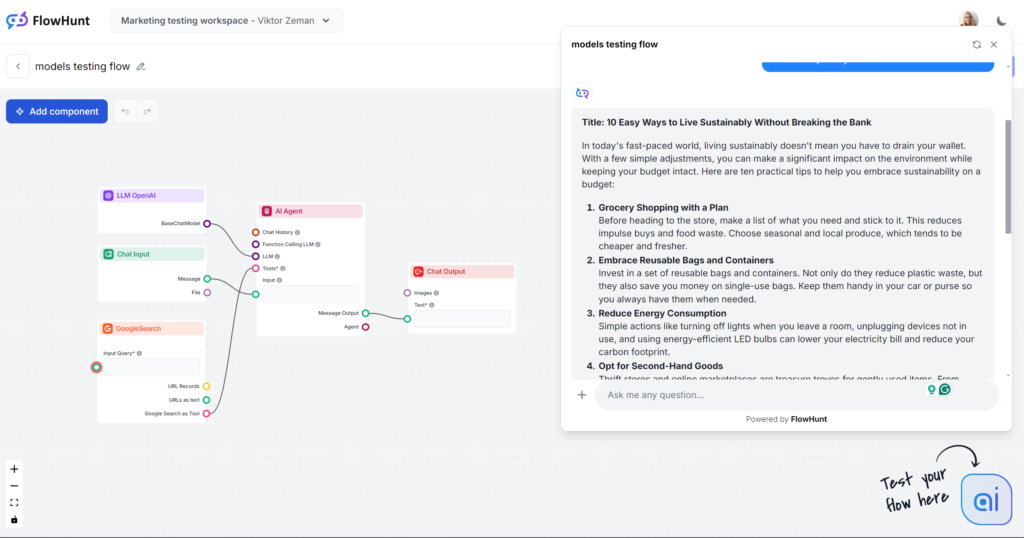
Si esto fuera una prueba a ciegas, la línea inicial “En el mundo acelerado de hoy…” te delataría de inmediato. Seguramente estás muy familiarizado con la escritura de este modelo, ya que no solo es la opción más popular, sino también el núcleo de la mayoría de herramientas de redacción con IA de terceros. GPT-4o siempre es una opción segura para contenido general, pero prepárate para cierta vaguedad y verborrea.
Tono y lenguaje
Pasando por alto la dolorosamente usada frase de apertura, GPT-4o hizo exactamente lo esperado. Nadie pensaría que este texto fue escrito por un humano, pero sigue siendo un artículo bien estructurado y sin duda sigue nuestro prompt. El tono realmente es práctico y accesible, centrándose en consejos accionables en lugar de vaguedades.
Uso de palabras clave
GPT-4o superó bien la prueba de palabras clave. No solo usó la palabra clave principal, sino también frases similares y otras palabras relevantes.
Legibilidad
En la escala de Flesch-Kincaid, esta salida corresponde a 10º-12º grado (bastante difícil) con una puntuación de 51.2. Un punto menos y estaría a nivel universitario. Con una salida tan corta, incluso la palabra “sostenibilidad” seguramente afecta la legibilidad. Aun así, hay mucho margen de mejora.
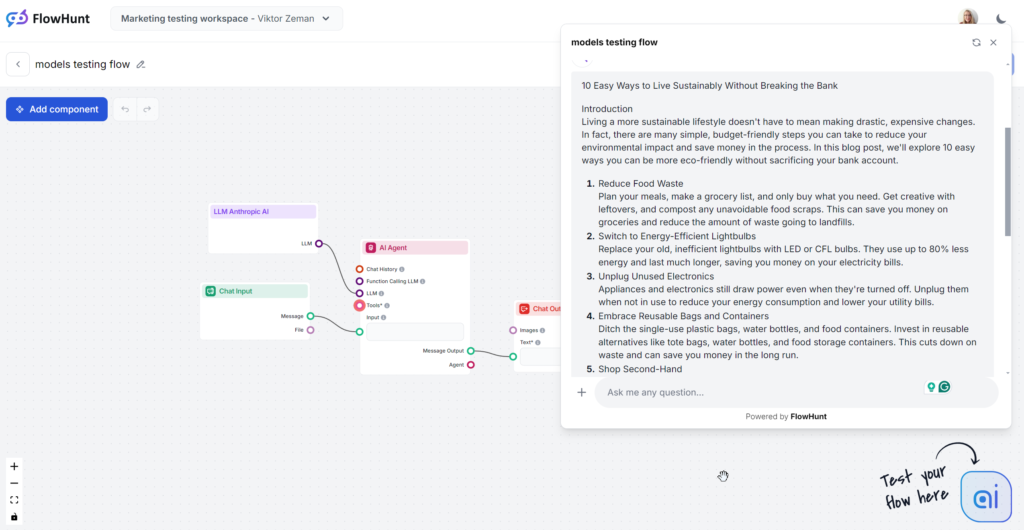
El resultado analizado de Claude es el modelo Sonnet de gama media, que se rumorea es la mejor opción para contenido. El texto se lee bien y es notablemente más humano que GPT-4o o Llama. Claude es la solución perfecta para contenido claro y simple, entregando información de forma eficiente sin ser tan verborreico como GPT ni tan llamativo como Grok.
Tono y lenguaje
Claude destaca por sus respuestas sencillas, cercanas y humanas. El tono es práctico y accesible, centrado de inmediato en consejos accionables en vez de vaguedades.
Uso de palabras clave
Claude fue el único modelo que ignoró la parte de palabras clave del prompt, usándola solo en 1 de 3 resultados. Cuando la incluyó, fue en la conclusión y el uso se sintió algo forzado.
Legibilidad
El Sonnet de Claude obtuvo alta puntuación en la escala Flesch-Kincaid, ubicándose en 8º-9º grado (inglés sencillo), solo unos puntos por detrás de Grok. Mientras Grok cambió todo el tono y vocabulario para lograr esto, Claude usó un vocabulario similar al de GPT-4o. ¿Por qué la legibilidad era tan buena? Frases más cortas, palabras cotidianas y ausencia de vaguedades.
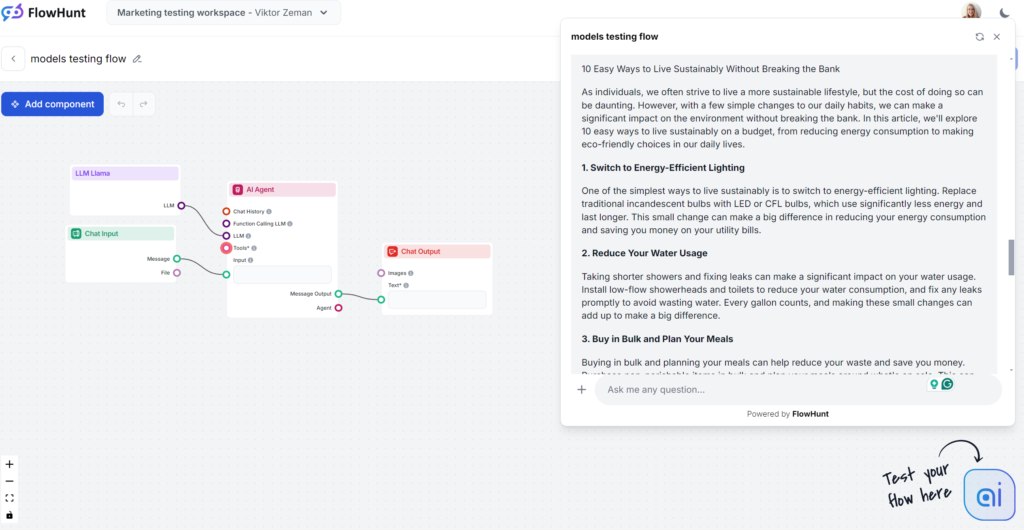
El punto más fuerte de Llama fue el uso de palabras clave. Por otro lado, el estilo de escritura no era inspirado y fue algo verborreico, aunque menos aburrido que GPT-4o. Llama es como el primo de GPT-4o: una opción segura con un estilo algo vago y extenso. Es una gran opción si normalmente te gusta el estilo de los modelos de OpenAI pero quieres evitar las frases clásicas de GPT.
Tono y lenguaje
Los artículos generados por Llama se leen muy similares a los de GPT-4o. La verborrea y vaguedad son comparables, pero el tono es práctico y accesible.
Uso de palabras clave
Meta gana la prueba de palabras clave. Llama usó la palabra clave más de una vez, incluso en la introducción, e incluyó de forma natural frases similares y otros términos relevantes.
Legibilidad
En la escala de Flesch-Kincaid, el resultado corresponde a 10º-12º grado (bastante difícil), con una puntuación de 53.4, apenas mejor que GPT-4o (51.2). Con una salida tan corta, incluso la palabra “sostenibilidad” puede tener un efecto notable en la legibilidad. Aun así, hay margen para mejorar.
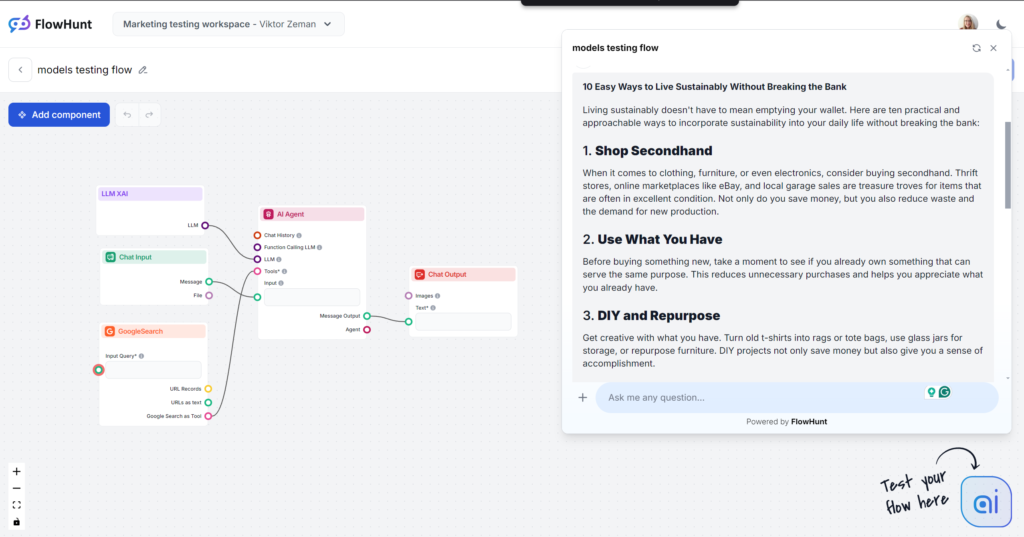
Grok fue una gran sorpresa, especialmente en tono y lenguaje. Con un tono muy natural y relajado, se sentía como recibir consejos rápidos de un amigo cercano. Si tu estilo es relajado y directo, Grok es definitivamente tu elección.
Tono y lenguaje
La salida se lee muy bien. El lenguaje es natural, las frases son breves y Grok usa bien los modismos. El modelo se mantiene fiel a su tono principal y lleva el texto a un nivel muy humano. Nota: El tono relajado de Grok no siempre es la mejor opción para contenido B2B o enfocado en SEO.
Uso de palabras clave
Grok usó la palabra clave solicitada, pero solo en la conclusión. Otros modelos colocaron mejor la palabra y añadieron más términos relevantes, mientras Grok se centró más en el flujo del lenguaje.
Legibilidad
Con un lenguaje sencillo, Grok superó la prueba de Flesch-Kincaid con gran éxito. Obtuvo 61.4, lo que corresponde a 7º-8º grado (inglés sencillo). Es óptimo para hacer accesibles los temas al público general. Este salto en legibilidad es casi tangible.
Obtén los últimos consejos, tendencias y ofertas gratis.
El poder de los LLMs depende de la calidad de los datos de entrenamiento, que a veces pueden estar sesgados o ser inexactos, provocando la difusión de desinformación. Es fundamental verificar y revisar el contenido generado por IA para garantizar equidad e inclusión. Al experimentar con varios modelos, recuerda que cada uno gestiona de forma distinta la privacidad de los datos y la limitación de resultados dañinos.
Para guiar el uso ético, las organizaciones deben establecer marcos que aborden la privacidad de datos, mitigación de sesgos y moderación de contenidos. Esto incluye diálogo regular entre desarrolladores de IA, redactores y expertos legales. Considera esta lista de preocupaciones éticas:
La elección de LLMs debe estar éticamente alineada con las directrices de contenido de la organización. Tanto los modelos open-source como los propietarios deben evaluarse para evitar usos indebidos.
El sesgo, la inexactitud y las alucinaciones siguen siendo grandes problemas en el contenido generado por IA. Debido a las directrices integradas, esto suele resultar en salidas vagas y de bajo valor. Las empresas a menudo requieren formación adicional y medidas de seguridad para abordar estos problemas. Para los pequeños negocios, el tiempo y los recursos para una formación personalizada suelen estar fuera de alcance. Una alternativa es añadir estas capacidades utilizando modelos generales a través de herramientas de terceros como FlowHunt.
FlowHunt te permite dar conocimientos específicos, acceso a internet y nuevas capacidades a los modelos base clásicos. Así puedes elegir el modelo adecuado para cada tarea sin las limitaciones del modelo base ni múltiples suscripciones.
Otro gran desafío es la complejidad de estos modelos. Con miles de millones de parámetros, pueden ser difíciles de gestionar, entender y depurar. FlowHunt te ofrece mucho más control que los prompts de chat básicos. Puedes añadir capacidades individuales como bloques y ajustarlos para crear tu propia biblioteca de herramientas de IA listas para usar.
El futuro de los modelos de lenguaje (LLMs) en la redacción de contenidos es prometedor y emocionante. A medida que estos modelos avanzan, prometen mayor precisión y menos sesgos en la generación de textos. Esto significa que los escritores podrán producir contenidos fiables y similares a los humanos con ayuda de la IA.
Los LLMs no solo manejarán texto, sino que también dominarán la creación de contenido multimodal. Esto incluye gestionar tanto texto como imágenes, impulsando la creatividad en industrias diversas. Con conjuntos de datos más grandes y mejor filtrados, los LLMs elaborarán contenidos más fiables y refinarán los estilos de redacción.
Pero, por ahora, los LLMs no pueden hacerlo por sí solos, y estas capacidades están repartidas entre distintas empresas y modelos, cada uno luchando por tu atención y dinero. FlowHunt los reúne todos y permite
GPT-4 es el más popular y versátil para contenido general, pero Llama de Meta ofrece un estilo de escritura más fresco. Claude 3 es ideal para contenido limpio y simple, mientras que Grok destaca por un tono relajado y humano. La mejor elección depende de tus objetivos y preferencias de estilo para el contenido.
Considera la legibilidad, el tono, la originalidad, el uso de palabras clave y cómo cada modelo se adapta a tus necesidades de contenido. También evalúa fortalezas como creatividad, versatilidad de géneros o potencial de integración, y ten en cuenta desafíos como sesgos, verborrea o requerimientos de recursos.
FlowHunt te permite probar y comparar múltiples LLMs líderes en un solo entorno, brindando control sobre los resultados y permitiéndote encontrar el mejor modelo para tu flujo de trabajo sin múltiples suscripciones.
Sí. Los LLM pueden perpetuar sesgos, generar desinformación y plantear preocupaciones de privacidad de datos. Es vital verificar los resultados de la IA, evaluar los modelos por su alineación ética y establecer marcos para un uso responsable.
Los LLMs del futuro ofrecerán mayor precisión, menos sesgos y generación de contenido multimodal (texto, imágenes, etc.), permitiendo a los escritores crear contenido más confiable y creativo. Plataformas unificadas como FlowHunt facilitarán el acceso a estas capacidades avanzadas.
Experimenta los principales LLMs lado a lado y mejora tu flujo de trabajo de redacción de contenidos con la plataforma unificada de FlowHunt.
Un modelo de lenguaje grande (LLM) es un tipo de inteligencia artificial entrenada con grandes cantidades de datos textuales para comprender, generar y manipula...
La Generación de Texto con Modelos de Lenguaje de Gran Tamaño (LLMs) se refiere al uso avanzado de modelos de aprendizaje automático para producir texto similar...
Descubre los costos asociados con el entrenamiento y la implementación de Modelos de Lenguaje Grandes (LLMs) como GPT-3 y GPT-4, incluyendo gastos computacional...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.