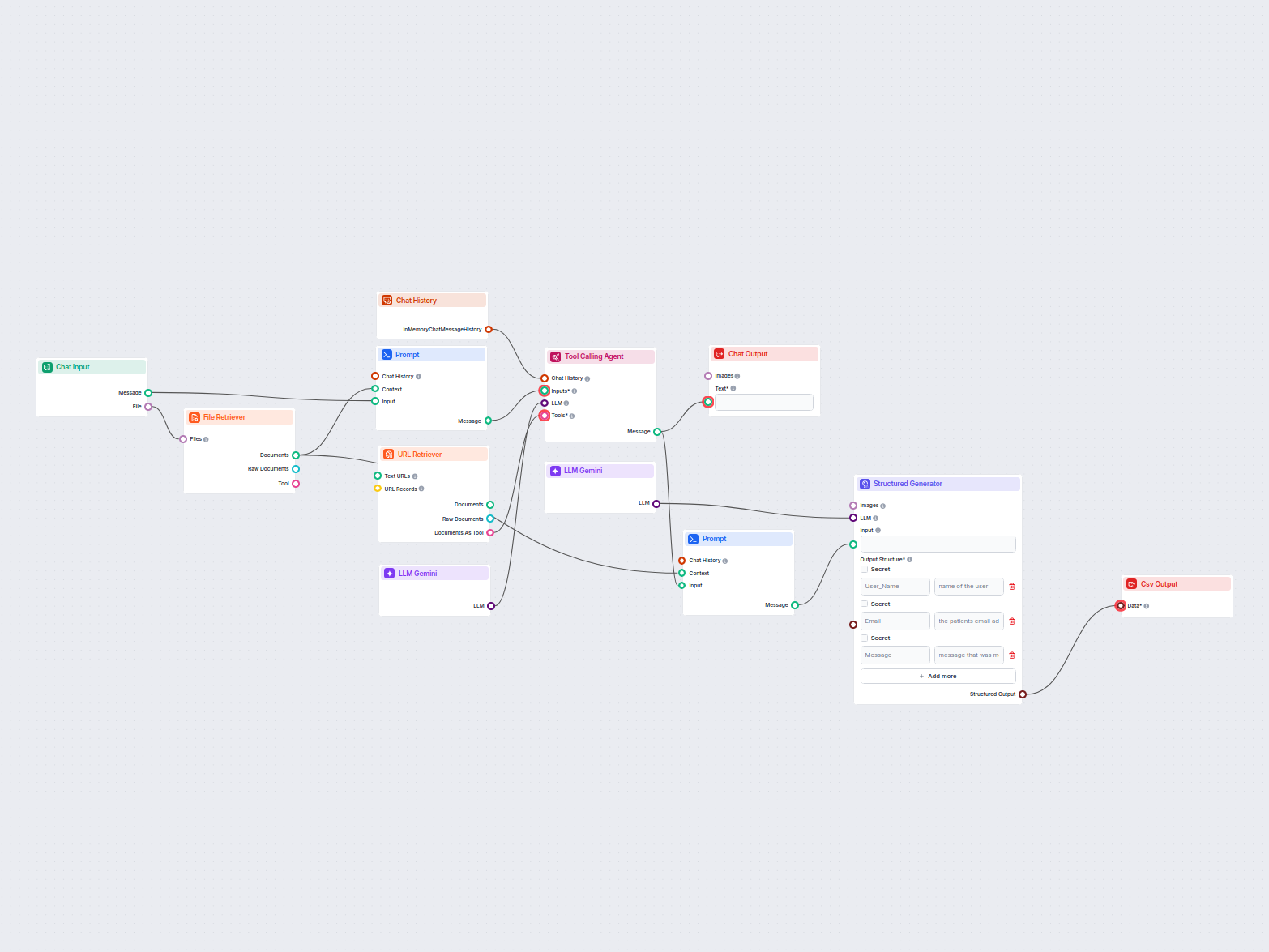
Extracción de Datos de Correos Electrónicos y Archivos a CSV
Este flujo de trabajo extrae y organiza información clave de correos electrónicos y archivos adjuntos, utiliza IA para procesar y estructurar los datos, y entre...
4 min de lectura
Para ayudarle a comenzar rápidamente, hemos preparado varios ejemplos de plantillas de flujo que demuestran cómo utilizar el componente Urlcontent de manera efectiva. Estas plantillas muestran diferentes casos de uso y mejores prácticas, facilitando la comprensión e implementación del componente en sus propios proyectos.
Este flujo de trabajo extrae y organiza información clave de correos electrónicos y archivos adjuntos, utiliza IA para procesar y estructurar los datos, y entre...
Ayudamos a empresas como la suya a desarrollar chatbots inteligentes, servidores MCP, herramientas de IA u otros tipos de automatización con IA para reemplazar a humanos en tareas repetitivas de su organización.