Mejorador de descripciones de productos de Shopify
Este flujo de trabajo potenciado por IA mejora las descripciones de productos de Shopify según el nombre del producto o la URL proporcionada por el usuario. Apr...
4 min de lectura
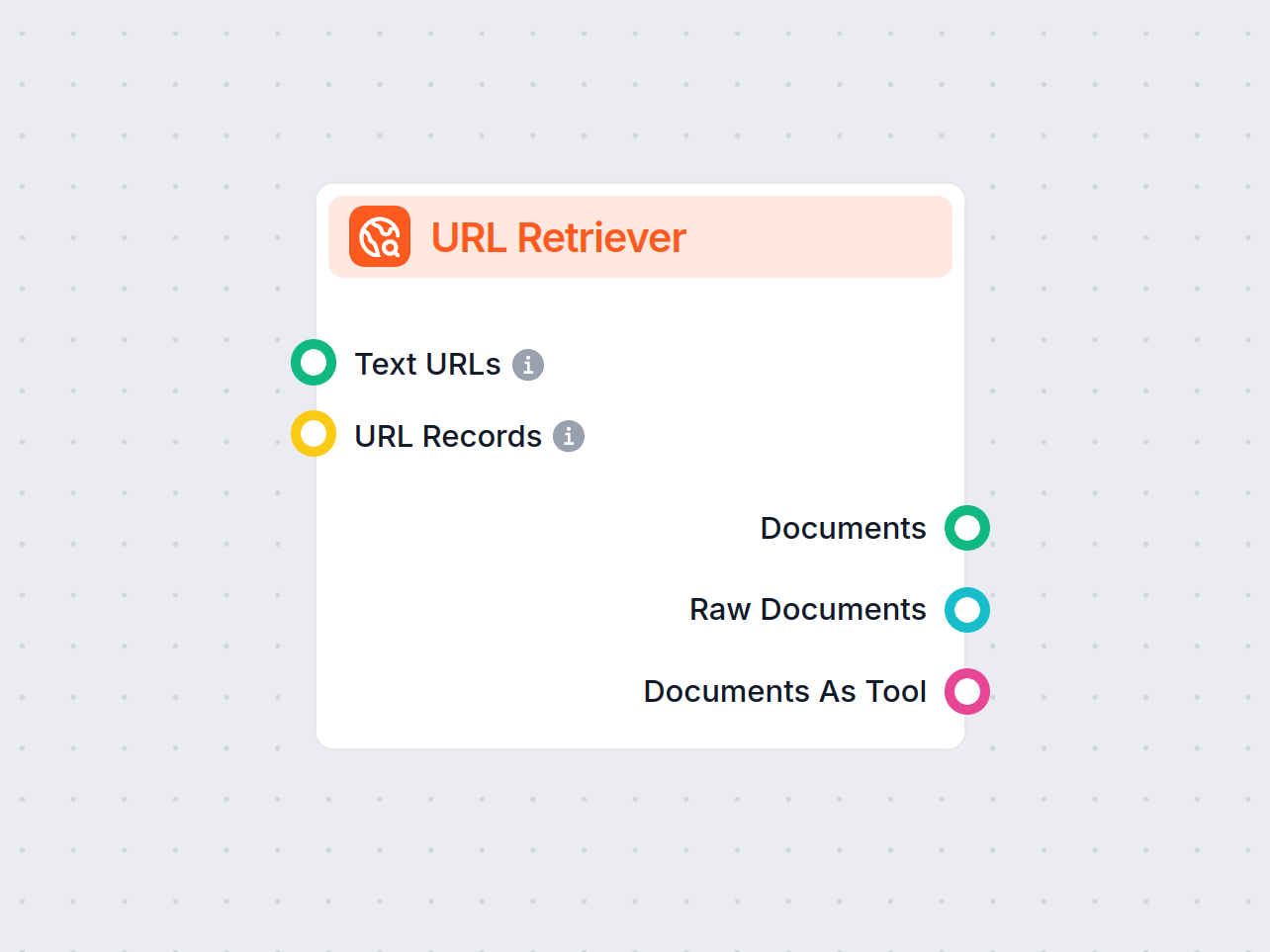
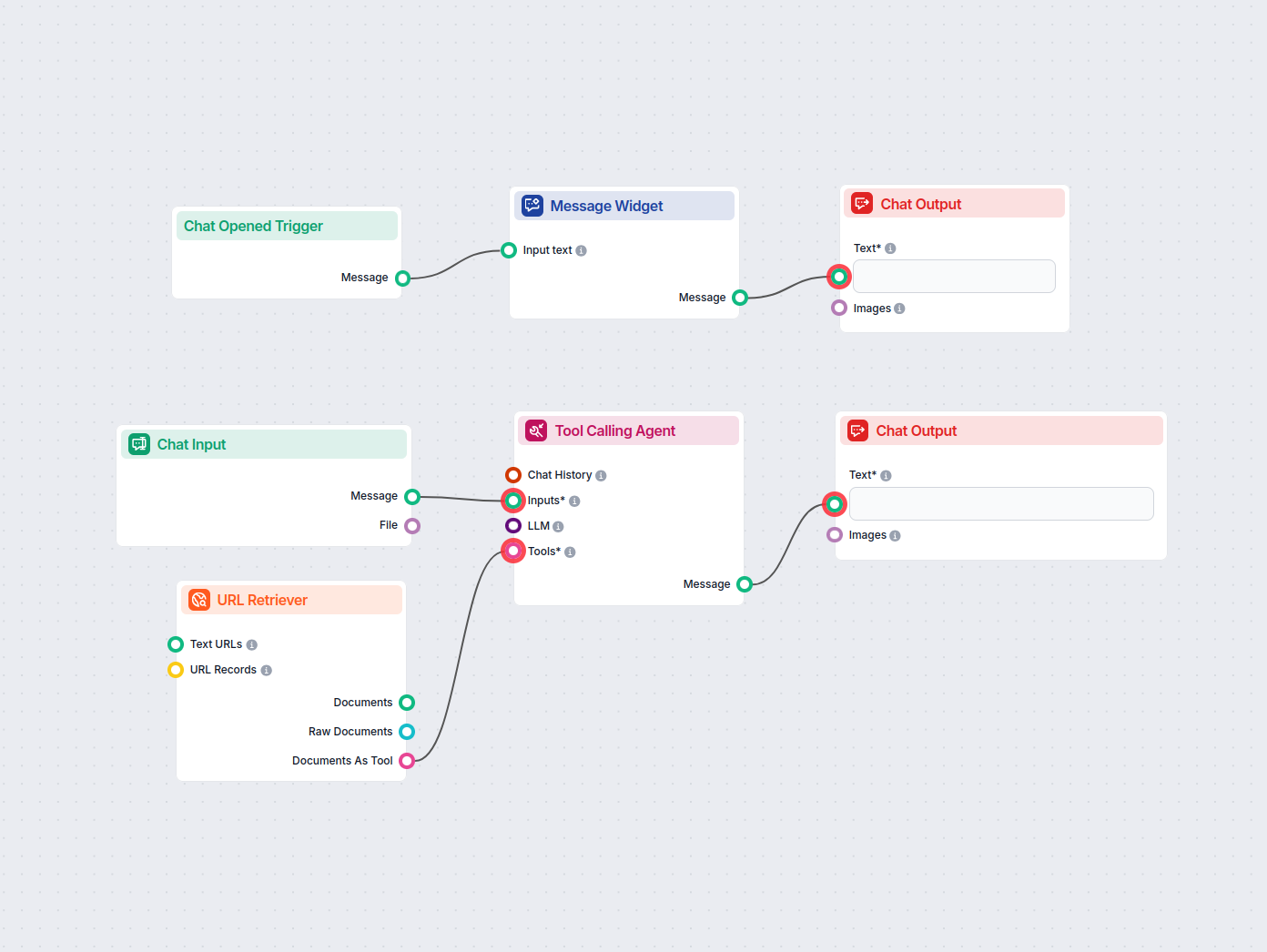
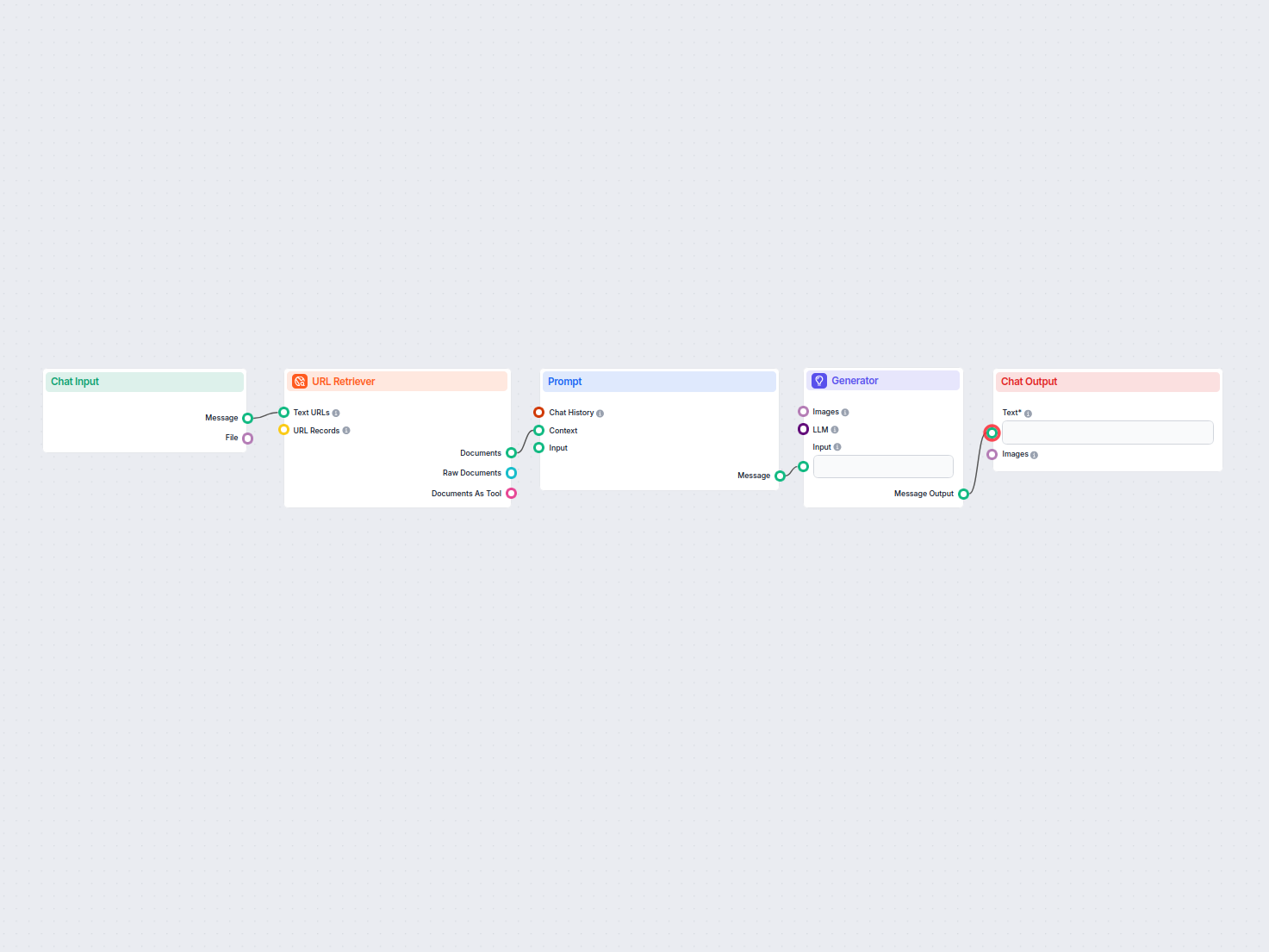
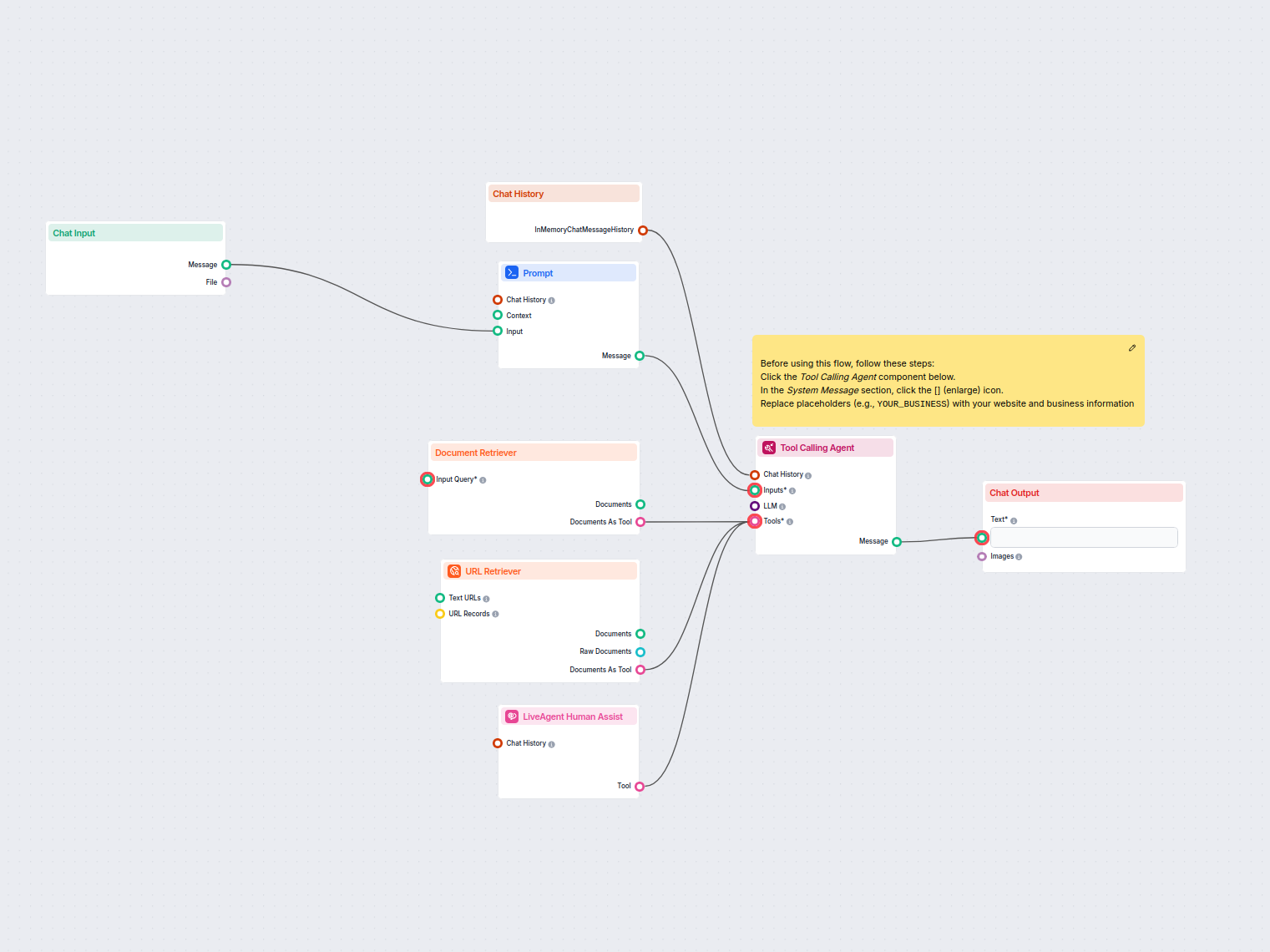
El Recuperador de URL te permite obtener y procesar contenido de enlaces web, soportando OCR, extracción de metadatos y salida flexible para potenciar flujos de trabajo de IA.
Descripción del componente
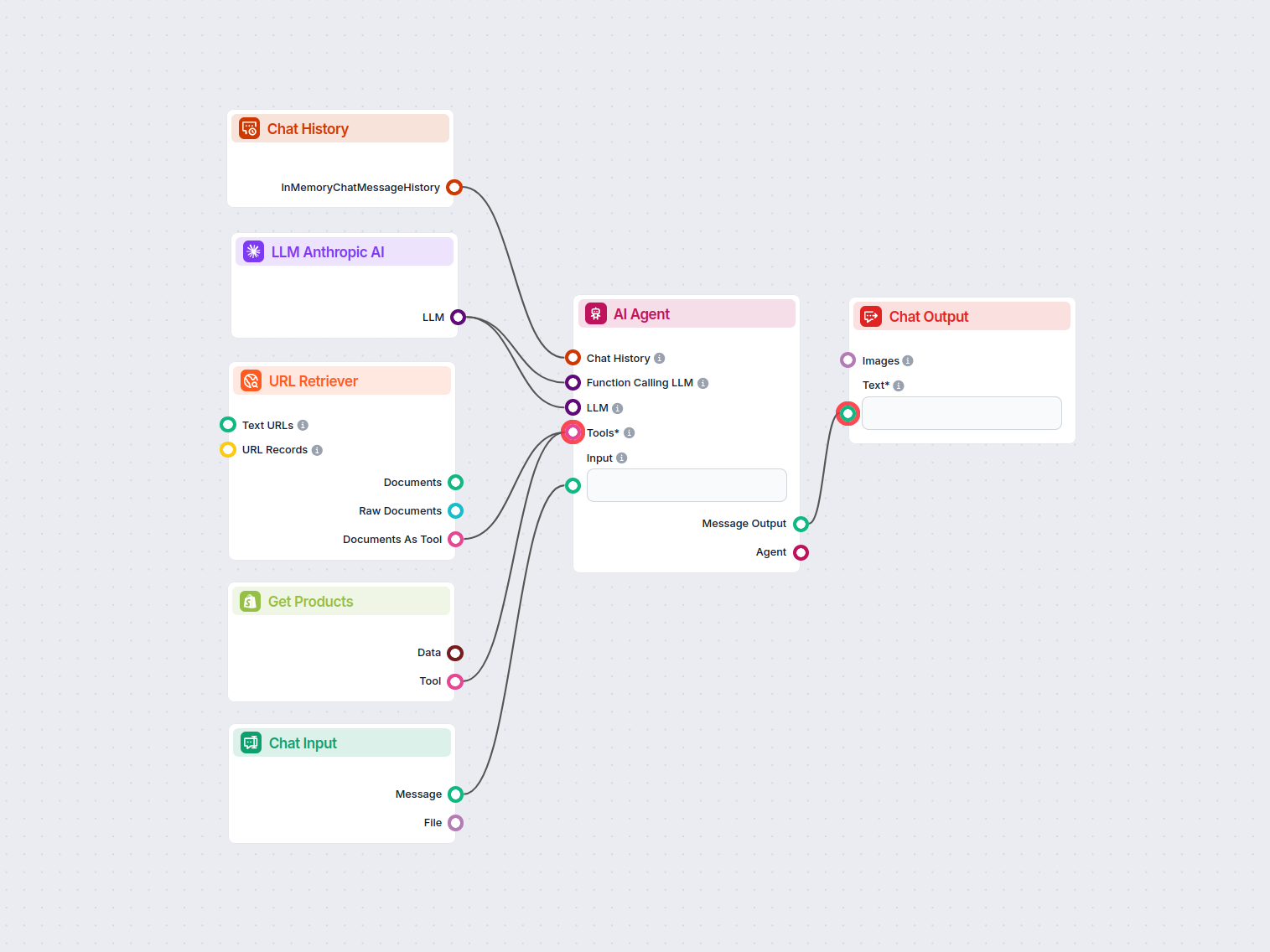
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Para ayudarle a comenzar rápidamente, hemos preparado varios ejemplos de plantillas de flujo que demuestran cómo utilizar el componente Recuperador de URL de manera efectiva. Estas plantillas muestran diferentes casos de uso y mejores prácticas, facilitando la comprensión e implementación del componente en sus propios proyectos.
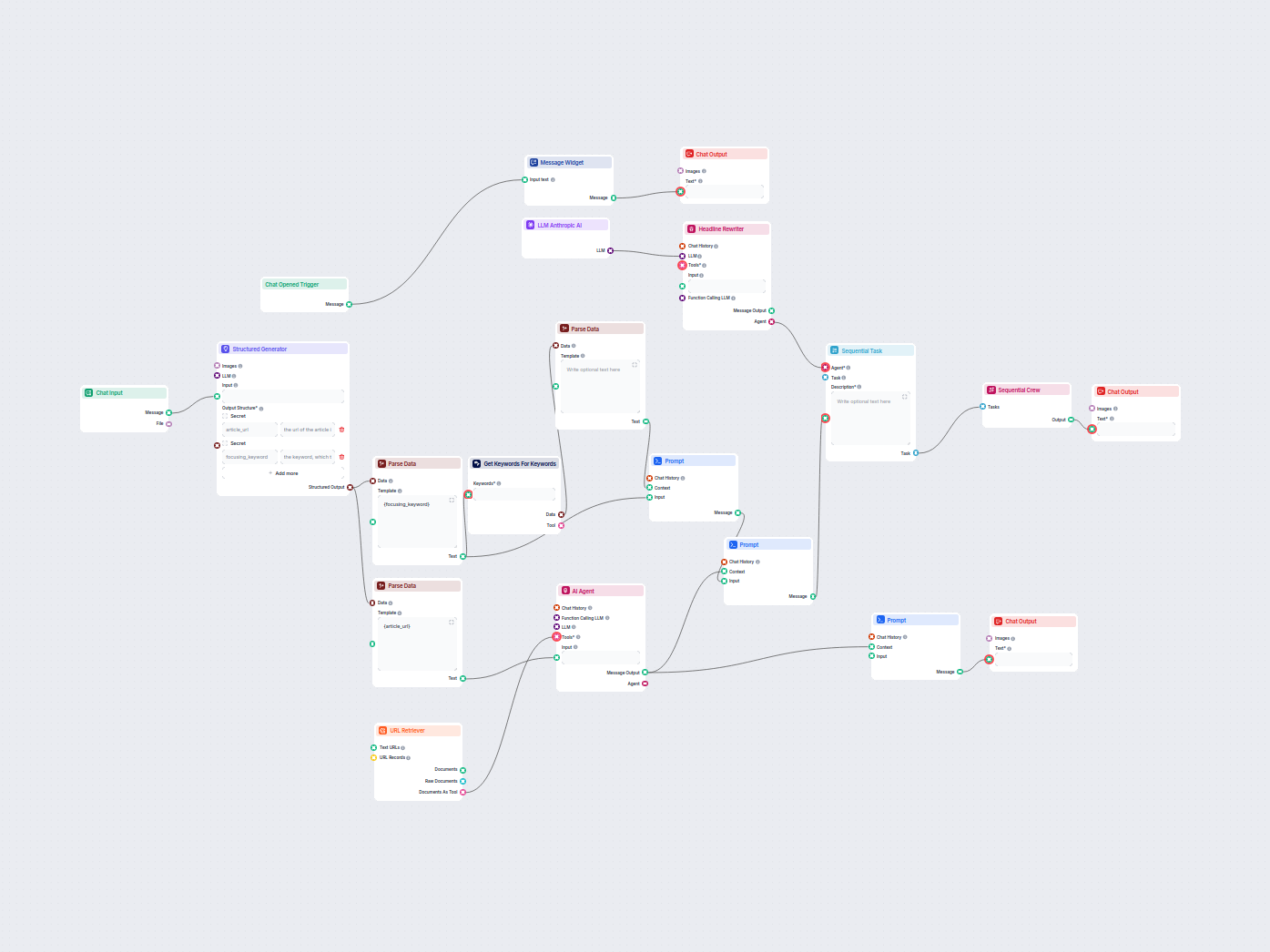
Este flujo de trabajo potenciado por IA mejora las descripciones de productos de Shopify según el nombre del producto o la URL proporcionada por el usuario. Apr...
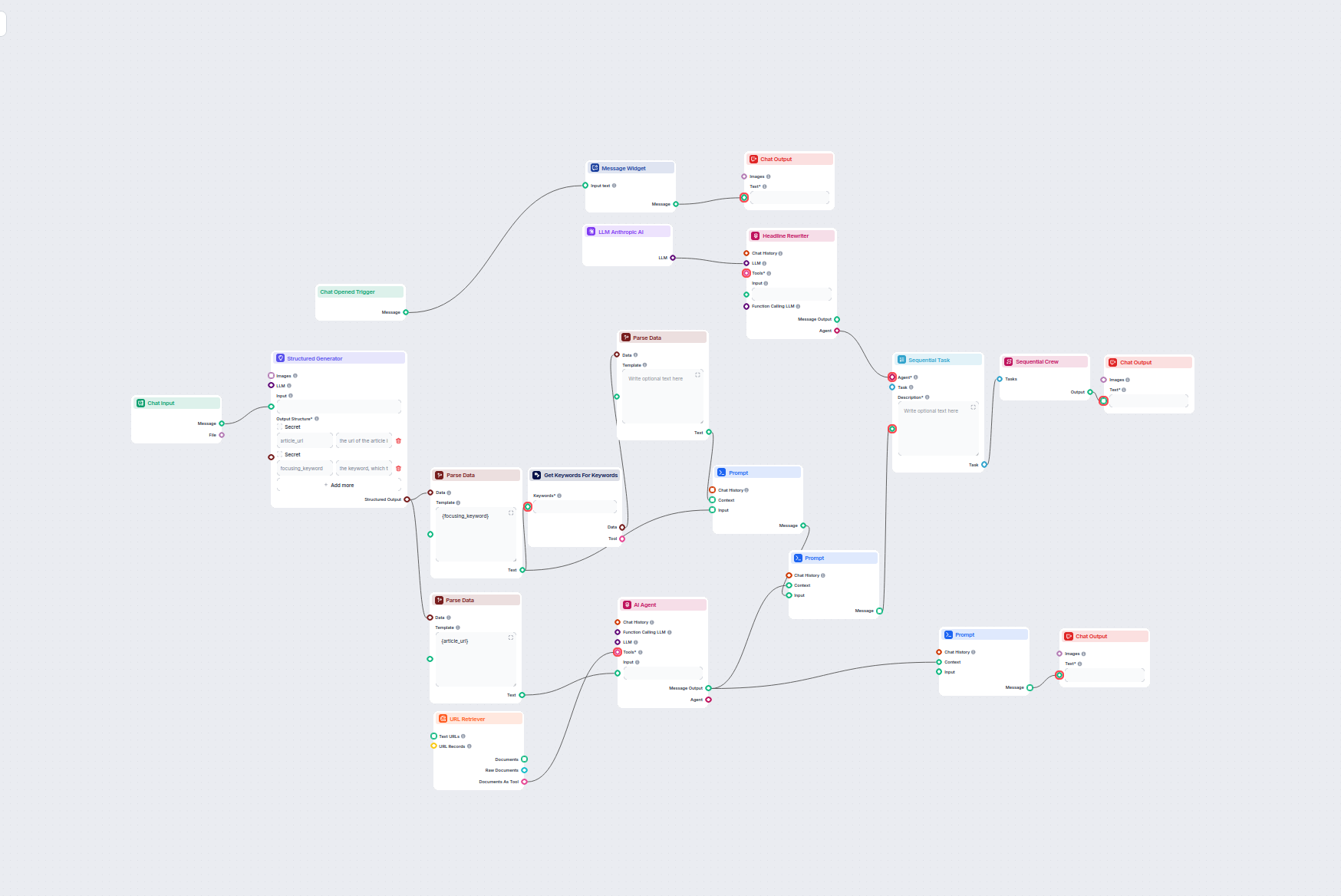
Optimiza automáticamente los titulares y el título de tu artículo para una palabra clave o clúster de palabras clave específico y así mejorar el rendimiento SEO...
Este flujo de trabajo impulsado por IA encuentra las mejores palabras clave SEO para tu artículo de blog y reescribe automáticamente los titulares para orientar...
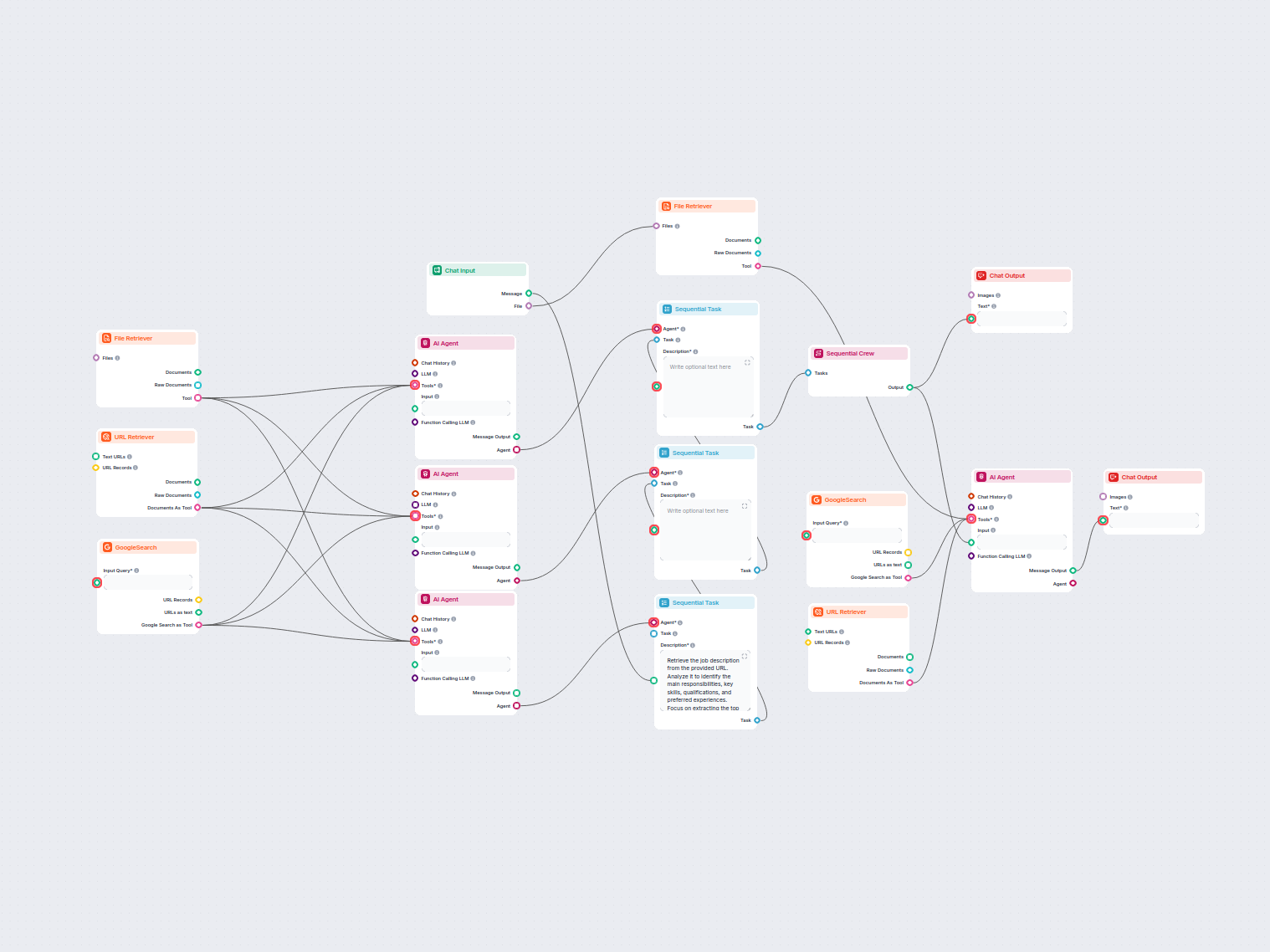
Este flujo de trabajo impulsado por IA agiliza el proceso de adaptar el CV de un usuario para que coincida con una oferta de trabajo específica. Al analizar tan...
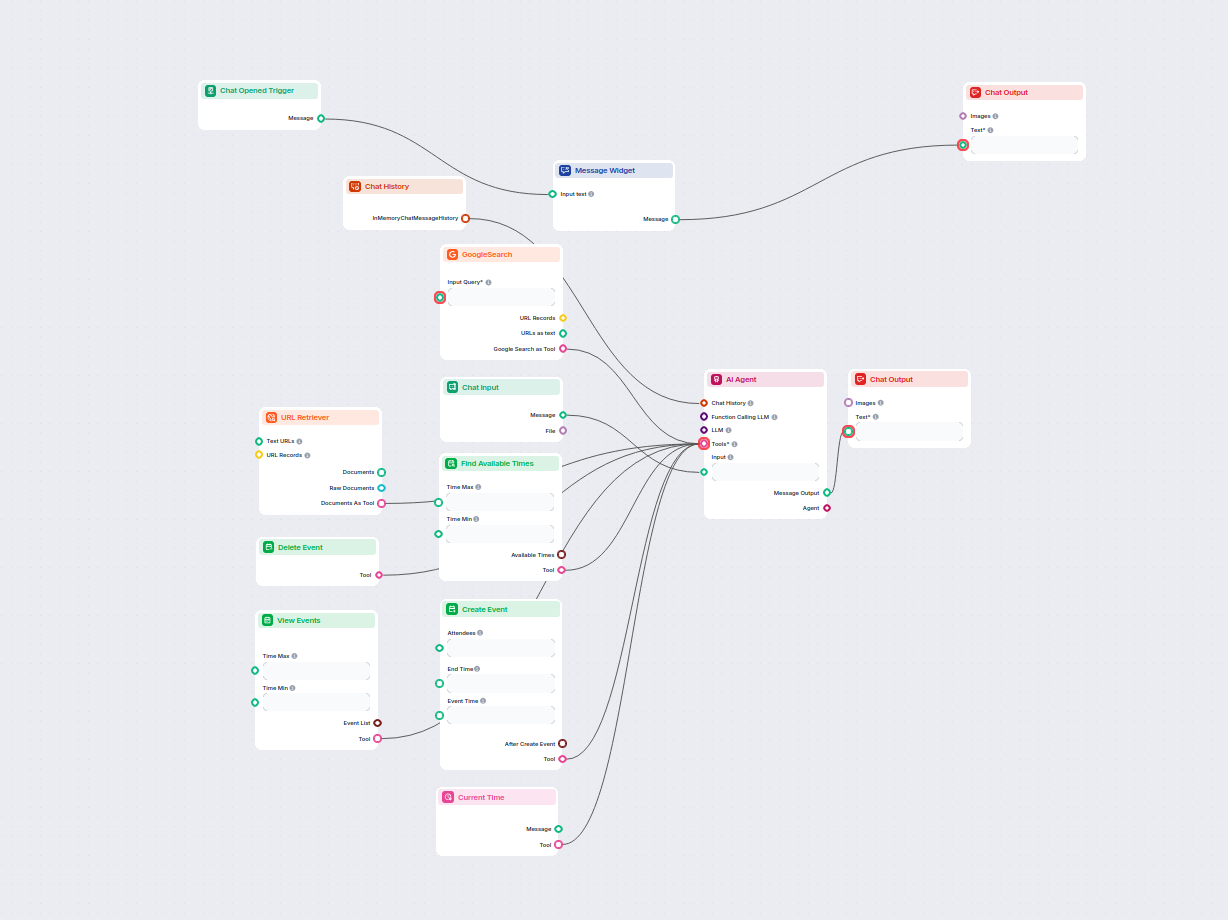
Este flujo de trabajo impulsado por IA automatiza la programación de reuniones a través de Google Calendar. Los usuarios interactúan con un chatbot que encuentr...
Genera rápidamente resúmenes concisos de cualquier página web simplemente proporcionando una URL. Este flujo de trabajo impulsado por IA recupera el contenido d...
Crea automáticamente una meta descripción atractiva y optimizada para SEO para cualquier página web, PDF, video de YouTube o enlace de documento, analizando su ...
Automatiza la atención al cliente en LiveAgent con un chatbot de IA que responde preguntas utilizando tu base de conocimientos interna, recupera documentos rele...
Mostrando 61 a 68 de 68 resultados
El Recuperador de URL obtiene y procesa contenido de enlaces web especificados, haciendo que el texto y los metadatos de documentos en línea estén disponibles para tu flujo de trabajo o agente de IA.
Sí, al habilitar la opción de OCR, el componente puede extraer texto de documentos basados en imágenes o PDFs escaneados.
Proporciona documentos procesados como mensajes de texto, objetos de documentos en bruto o como una herramienta para flujos de trabajo de agentes, según tu configuración.
Puedes establecer cuánto tiempo se almacena en caché el contenido recuperado, reduciendo descargas repetidas y acelerando tus flujos.
Sí, puedes especificar qué encabezados, párrafos o campos de metadatos incluir en la salida, permitiendo una extracción enfocada.
Absolutamente. El Recuperador de URL es esencial para cualquier automatización o chatbot que necesite leer, procesar o resumir contenido web en tiempo real.
Impulsa tus flujos de trabajo integrando contenido web en tiempo real. Extrae, procesa y utiliza datos de URLs fácilmente.
Integra tus flujos de trabajo con Google Docs usando el componente Recuperador de Google Docs: obtén el contenido de los documentos de forma automática para usa...
El componente Recuperador de Archivos en FlowHunt te permite incorporar archivos en tu flujo de trabajo y convertirlos en documentos para su procesamiento poste...
Captura instantáneamente instantáneas de sitios web con el componente Herramienta de Captura de Pantallas. Automatiza fácilmente la toma de capturas de cualquie...