¿Qué es el chatbot Perplexity AI?
Descubre qué es Perplexity AI, cómo funciona y cómo se compara con ChatGPT. Conoce la búsqueda en tiempo real, las citas de fuentes y las funciones avanzadas de...
13 min de lectura

La Búsqueda por IA es una metodología de búsqueda semántica o basada en vectores que utiliza modelos de aprendizaje automático para comprender la intención y el significado contextual detrás de las consultas de búsqueda, ofreciendo resultados más relevantes y precisos que la búsqueda tradicional basada en palabras clave.
La Búsqueda por IA utiliza aprendizaje automático para comprender el contexto y la intención de las consultas de búsqueda, transformándolas en vectores numéricos para obtener resultados más precisos. A diferencia de las búsquedas tradicionales por palabras clave, la Búsqueda por IA interpreta relaciones semánticas, siendo efectiva para diversos tipos de datos e idiomas.
La Búsqueda por IA, a menudo llamada búsqueda semántica o vectorial, es una metodología de búsqueda que aprovecha modelos de aprendizaje automático para entender la intención y el significado contextual detrás de las consultas de búsqueda. A diferencia de la búsqueda tradicional basada en palabras clave, la búsqueda por IA transforma datos y consultas en representaciones numéricas conocidas como vectores o embeddings. Esto permite que el motor de búsqueda comprenda las relaciones semánticas entre diferentes piezas de datos, brindando resultados más relevantes y precisos incluso cuando no están presentes las palabras clave exactas.
La Búsqueda por IA representa una evolución significativa en las tecnologías de búsqueda. Los motores de búsqueda tradicionales dependen en gran medida de la coincidencia de palabras clave, donde la presencia de términos específicos tanto en la consulta como en los documentos determina la relevancia. Sin embargo, la Búsqueda por IA utiliza modelos de aprendizaje automático para captar el contexto subyacente y el significado de las consultas y los datos.
Al convertir texto, imágenes, audio y otros datos no estructurados en vectores de alta dimensión, la Búsqueda por IA puede medir la similitud entre diferentes contenidos. Este enfoque permite que el motor de búsqueda entregue resultados contextualmente relevantes, incluso si no contienen las palabras clave exactas usadas en la consulta.
Componentes clave:
En el corazón de la Búsqueda por IA se encuentra el concepto de embeddings vectoriales. Los embeddings vectoriales son representaciones numéricas de datos que capturan el significado semántico de textos, imágenes u otros tipos de datos. Estos embeddings colocan piezas de datos similares cerca unas de otras en un espacio vectorial multidimensional.
Cómo funciona:
Ejemplo:
Comienza tu prueba gratuita hoy y ve resultados en días.
Los motores de búsqueda tradicionales basados en palabras clave funcionan haciendo coincidir los términos de la consulta de búsqueda con los documentos que contienen esos términos. Se basan en técnicas como índices invertidos y frecuencia de términos para clasificar los resultados.
Limitaciones de la búsqueda basada en palabras clave:
Ventajas de la Búsqueda por IA:
| Aspecto | Búsqueda por Palabras Clave | Búsqueda por IA (Semántica/Vectorial) |
|---|---|---|
| Coincidencia | Coincidencias exactas de palabras clave | Similitud semántica |
| Conciencia del contexto | Limitada | Alta |
| Manejo de sinónimos | Requiere listas manuales de sinónimos | Automático mediante embeddings |
| Errores tipográficos | Puede fallar sin búsqueda difusa | Más tolerante por el contexto semántico |
| Comprensión de la intención | Mínima | Significativa |
La Búsqueda Semántica es una aplicación central de la Búsqueda por IA enfocada en comprender la intención del usuario y el significado contextual de las consultas.
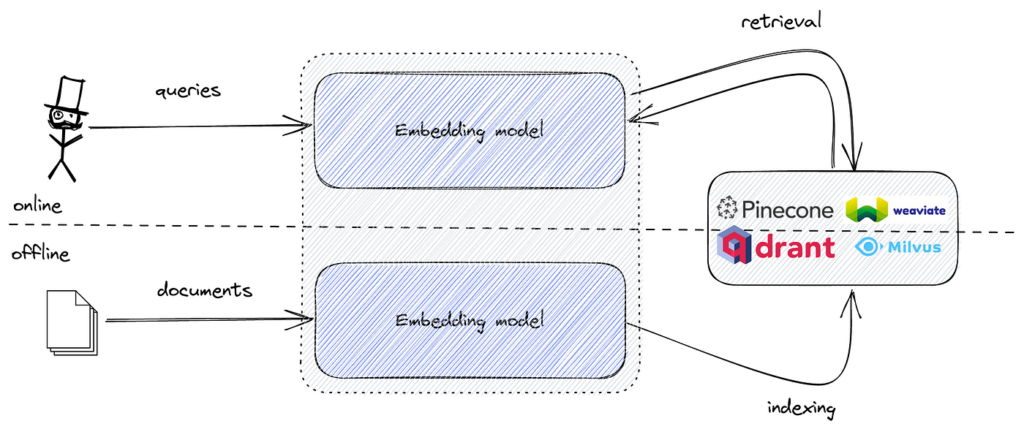
Proceso:
Técnicas clave:
Obtén los últimos consejos, tendencias y ofertas gratis.
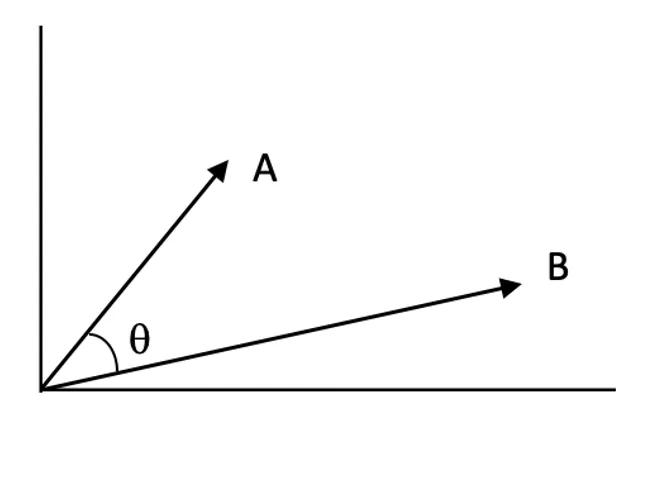
Puntuaciones de similitud:
Las puntuaciones de similitud cuantifican cuán relacionados están dos vectores en el espacio vectorial. Una puntuación más alta indica mayor relevancia entre la consulta y un documento.
Algoritmos de Vecino Más Cercano Aproximado (ANN):
Encontrar vecinos exactos en espacios de alta dimensión es computacionalmente intensivo. Los algoritmos ANN proporcionan aproximaciones eficientes.
La Búsqueda por IA abre una amplia gama de aplicaciones en diversas industrias gracias a su capacidad de comprender e interpretar datos más allá de la simple coincidencia de palabras clave.
Descripción: La Búsqueda Semántica mejora la experiencia del usuario interpretando la intención detrás de las consultas y proporcionando resultados contextualmente relevantes.
Ejemplos:
Descripción: Al comprender las preferencias y el comportamiento del usuario, la Búsqueda por IA puede ofrecer contenido o recomendaciones de productos personalizadas.
Ejemplos:
Descripción: La Búsqueda por IA permite que los sistemas comprendan y respondan consultas de los usuarios con información precisa extraída de documentos.
Ejemplos:
Descripción: La Búsqueda por IA puede indexar y buscar a través de tipos de datos no estructurados como imágenes, audio y videos convirtiéndolos en embeddings.
Ejemplos:
Integrar la Búsqueda por IA en la automatización y los chatbots mejora significativamente sus capacidades.
Beneficios:
Pasos de implementación:
Ejemplo de caso de uso:
Aunque la Búsqueda por IA ofrece numerosas ventajas, existen desafíos a considerar:
Estrategias de mitigación:
La búsqueda semántica y vectorial en IA han surgido como alternativas poderosas a las búsquedas tradicionales basadas en palabras clave y búsquedas difusas, mejorando significativamente la relevancia y precisión de los resultados al comprender el contexto y el significado detrás de las consultas.
Al implementar búsqueda semántica, los datos textuales se convierten en embeddings vectoriales que capturan el significado semántico del texto. Estos embeddings son representaciones numéricas de alta dimensión. Para buscar eficientemente entre estos embeddings y encontrar los más similares a un embedding de consulta, se necesita una herramienta optimizada para la búsqueda de similitud en espacios de alta dimensión.
FAISS proporciona los algoritmos y estructuras de datos necesarios para realizar esta tarea de manera eficiente. Al combinar embeddings semánticos con FAISS, es posible crear un potente motor de búsqueda semántica capaz de manejar grandes volúmenes de datos con baja latencia.
Implementar búsqueda semántica con FAISS en Python implica varios pasos:
Vamos a detallar cada paso.
Prepara tu conjunto de datos (por ejemplo, artículos, tickets de soporte, descripciones de productos).
Ejemplo:
documents = [
"Cómo restablecer tu contraseña en nuestra plataforma.",
"Solución de problemas de conectividad de red.",
"Guía para instalar actualizaciones de software.",
"Mejores prácticas para copias de seguridad y recuperación de datos.",
"Configuración de autenticación de dos factores para mayor seguridad."
]
Limpia y da formato a los datos según sea necesario.
Convierte los datos textuales en embeddings vectoriales usando modelos Transformer preentrenados de librerías como Hugging Face (transformers o sentence-transformers).
Ejemplo:
from sentence_transformers import SentenceTransformer
import numpy as np
# Cargar un modelo preentrenado
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generar embeddings para todos los documentos
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 como requiere FAISS.Crea un índice FAISS para almacenar los embeddings y permitir una búsqueda de similitud eficiente.
Ejemplo:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 realiza búsqueda por fuerza bruta usando distancia L2 (Euclidiana).Convierte la consulta del usuario en un embedding y encuentra los vecinos más cercanos.
Ejemplo:
query = "¿Cómo cambio la contraseña de mi cuenta?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Utiliza los índices para mostrar los documentos más relevantes.
Ejemplo:
print("Principales resultados para tu consulta:")
for idx in indices[0]:
print(documents[idx])
Salida esperada:
Principales resultados para tu consulta:
Cómo restablecer tu contraseña en nuestra plataforma.
Configuración de autenticación de dos factores para mayor seguridad.
Mejores prácticas para copias de seguridad y recuperación de datos.
FAISS proporciona varios tipos de índices:
Uso de un índice de archivos invertidos (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalización y búsqueda por producto interno:
Usar similitud de coseno puede ser más efectivo para datos textuales
La Búsqueda por IA es una metodología de búsqueda moderna que utiliza aprendizaje automático y embeddings vectoriales para comprender la intención y el significado contextual de las consultas, entregando resultados más precisos y relevantes que la búsqueda tradicional basada en palabras clave.
A diferencia de la búsqueda basada en palabras clave, que depende de coincidencias exactas, la Búsqueda por IA interpreta las relaciones semánticas y la intención detrás de las consultas, siendo efectiva para el lenguaje natural y entradas ambiguas.
Los embeddings vectoriales son representaciones numéricas de texto, imágenes u otros tipos de datos que capturan su significado semántico, permitiendo que el motor de búsqueda mida la similitud y el contexto entre diferentes piezas de datos.
La Búsqueda por IA impulsa la búsqueda semántica en comercio electrónico, recomendaciones personalizadas en streaming, sistemas de respuesta a preguntas en soporte al cliente, exploración de datos no estructurados y recuperación de documentos en investigación y empresas.
Las herramientas populares incluyen FAISS para una búsqueda eficiente de similitud vectorial, y bases de datos vectoriales como Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch y Pgvector para almacenamiento y recuperación escalable de embeddings.
Al integrar la Búsqueda por IA, los chatbots y los sistemas de automatización pueden comprender las consultas de los usuarios más profundamente, recuperar respuestas contextualmente relevantes y ofrecer respuestas dinámicas y personalizadas.
Los desafíos incluyen altos requerimientos computacionales, complejidad en la interpretabilidad de modelos, necesidad de datos de alta calidad y garantizar la privacidad y seguridad al tratar información sensible.
FAISS es una librería de código abierto para la búsqueda eficiente de similitud en embeddings vectoriales de alta dimensión, ampliamente utilizada para construir motores de búsqueda semántica capaces de manejar grandes volúmenes de datos.
Descubre cómo la búsqueda semántica impulsada por IA puede transformar la recuperación de información, los chatbots y los flujos de trabajo de automatización.
Descubre qué es Perplexity AI, cómo funciona y cómo se compara con ChatGPT. Conoce la búsqueda en tiempo real, las citas de fuentes y las funciones avanzadas de...
Descubre qué es un Motor de Insights: una plataforma avanzada impulsada por IA que mejora la búsqueda y el análisis de datos comprendiendo el contexto y la inte...
Perplexity AI es un motor de búsqueda avanzado potenciado por IA y una herramienta conversacional que aprovecha el PLN y el aprendizaje automático para ofrecer ...