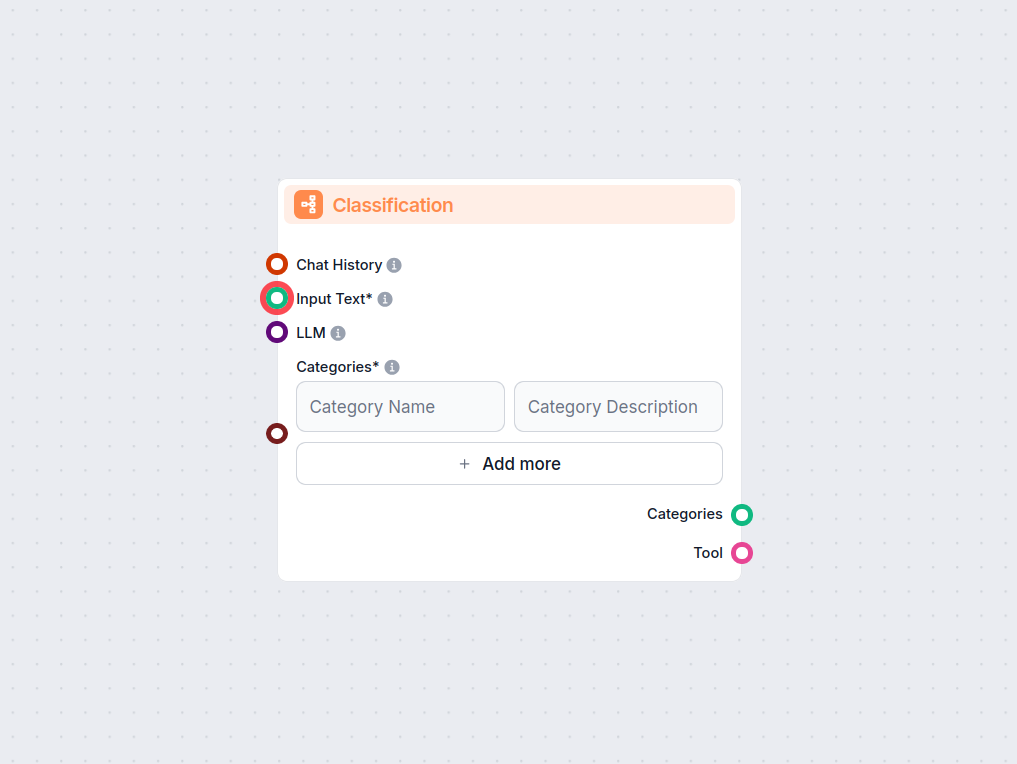
Clasificación de Texto
Desbloquea la categorización automatizada de texto en tus flujos de trabajo con el componente de Clasificación de Texto para FlowHunt. Clasifica fácilmente el t...
3 min de lectura
AI
Classification
+3
Desbloquea la categorización automatizada de texto en tus flujos de trabajo con el componente de Clasificación de Texto para FlowHunt. Clasifica fácilmente el t...
El aprendizaje supervisado es un enfoque fundamental en el aprendizaje automático y la inteligencia artificial, donde los algoritmos aprenden a partir de conjun...
El aprendizaje supervisado es un concepto fundamental de la IA y el aprendizaje automático donde los algoritmos se entrenan con datos etiquetados para hacer pre...
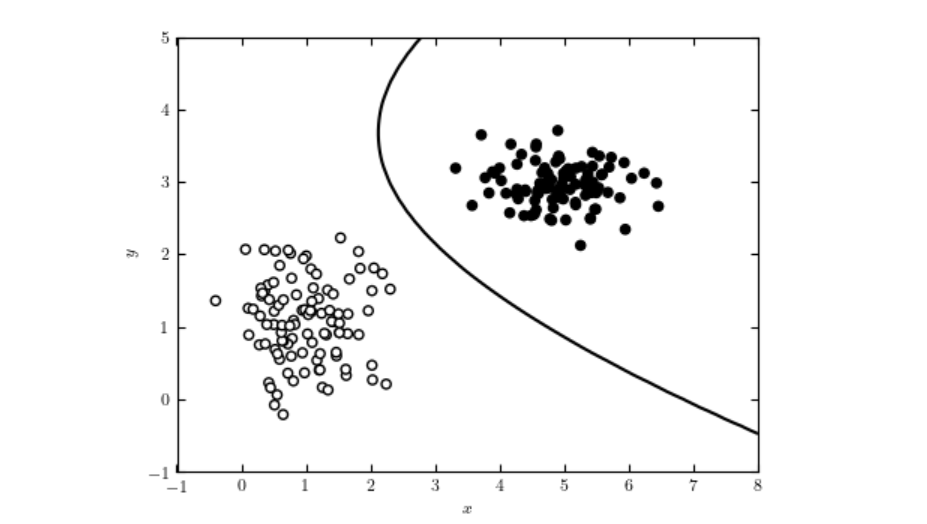
Un árbol de decisión es una herramienta poderosa e intuitiva para la toma de decisiones y el análisis predictivo, utilizada en tareas de clasificación y regresi...
El Área bajo la curva (AUC) es una métrica fundamental en aprendizaje automático utilizada para evaluar el rendimiento de modelos de clasificación binaria. Cuan...
Un clasificador de IA es un algoritmo de aprendizaje automático que asigna etiquetas de clase a datos de entrada, categorizando la información en clases predefi...
La entropía cruzada es un concepto fundamental tanto en la teoría de la información como en el aprendizaje automático, y sirve como una métrica para medir la di...
El Impulso por Gradiente es una potente técnica de ensamblaje de aprendizaje automático para regresión y clasificación. Construye modelos secuencialmente, norma...
LightGBM, o Light Gradient Boosting Machine, es un avanzado framework de gradient boosting desarrollado por Microsoft. Diseñado para tareas de aprendizaje autom...
Una matriz de confusión es una herramienta de aprendizaje automático para evaluar el desempeño de los modelos de clasificación, detallando verdaderos/falsos pos...
Aprende sobre los Modelos de IA Discriminativos: modelos de aprendizaje automático enfocados en clasificación y regresión mediante el modelado de los límites de...
Naive Bayes es una familia de algoritmos de clasificación basados en el Teorema de Bayes, que aplican la probabilidad condicional con la suposición simplificada...
La pérdida logarítmica, o pérdida logarítmica/pérdida de entropía cruzada, es una métrica clave para evaluar el rendimiento de modelos de aprendizaje automático...
La precisión top-k es una métrica de evaluación de aprendizaje automático que evalúa si la clase verdadera se encuentra entre las k clases predichas principales...
Explora el recall en aprendizaje automático: una métrica crucial para evaluar el rendimiento del modelo, especialmente en tareas de clasificación donde identifi...
El algoritmo de vecinos más cercanos (KNN) es un algoritmo de aprendizaje supervisado no paramétrico utilizado para tareas de clasificación y regresión en apren...