Integración del Servidor MCP de Neo4j
El Servidor MCP de Neo4j conecta asistentes de IA con la base de datos gráfica Neo4j, permitiendo operaciones seguras en el grafo impulsadas por lenguaje natura...
5 min de lectura
AI
Graph Database
+5
El Servidor MCP de Neo4j conecta asistentes de IA con la base de datos gráfica Neo4j, permitiendo operaciones seguras en el grafo impulsadas por lenguaje natura...
El Servidor MCP de la NASA proporciona una interfaz unificada para que modelos de IA y desarrolladores accedan a más de 20 fuentes de datos de la NASA. Estandar...
Reexpress MCP Server aporta verificación estadística a los flujos de trabajo de LLM. Utilizando el estimador Similarity-Distance-Magnitude (SDM), ofrece estimac...
El servidor MCP Code Executor MCP permite a FlowHunt y otras herramientas impulsadas por LLM ejecutar código Python de forma segura en entornos aislados, gestio...
El Servidor MCP de Exploración de Datos conecta asistentes de IA con conjuntos de datos externos para análisis interactivo. Permite a los usuarios explorar conj...
JupyterMCP permite la integración fluida de Jupyter Notebook (6.x) con asistentes de IA a través del Model Context Protocol. Automatiza la ejecución de código, ...
El Servidor Databricks Genie MCP permite que los grandes modelos de lenguaje interactúen con los entornos de Databricks a través de la API de Genie, admitiendo ...
El Agrupamiento K-Means es un popular algoritmo de aprendizaje automático no supervisado para dividir conjuntos de datos en un número predefinido de grupos dist...
Un Analista de Datos con IA combina habilidades tradicionales de análisis de datos con inteligencia artificial (IA) y aprendizaje automático (ML) para extraer c...
El aprendizaje semisupervisado (SSL) es una técnica de aprendizaje automático que aprovecha tanto datos etiquetados como no etiquetados para entrenar modelos, l...
Un árbol de decisión es una herramienta poderosa e intuitiva para la toma de decisiones y el análisis predictivo, utilizada en tareas de clasificación y regresi...
El Área bajo la curva (AUC) es una métrica fundamental en aprendizaje automático utilizada para evaluar el rendimiento de modelos de clasificación binaria. Cuan...
Anaconda es una distribución integral y de código abierto de Python y R, diseñada para simplificar la gestión de paquetes y el despliegue para la computación ci...
BigML es una plataforma de aprendizaje automático diseñada para simplificar la creación y el despliegue de modelos predictivos. Fundada en 2011, su misión es ha...
Un clasificador de IA es un algoritmo de aprendizaje automático que asigna etiquetas de clase a datos de entrada, categorizando la información en clases predefi...
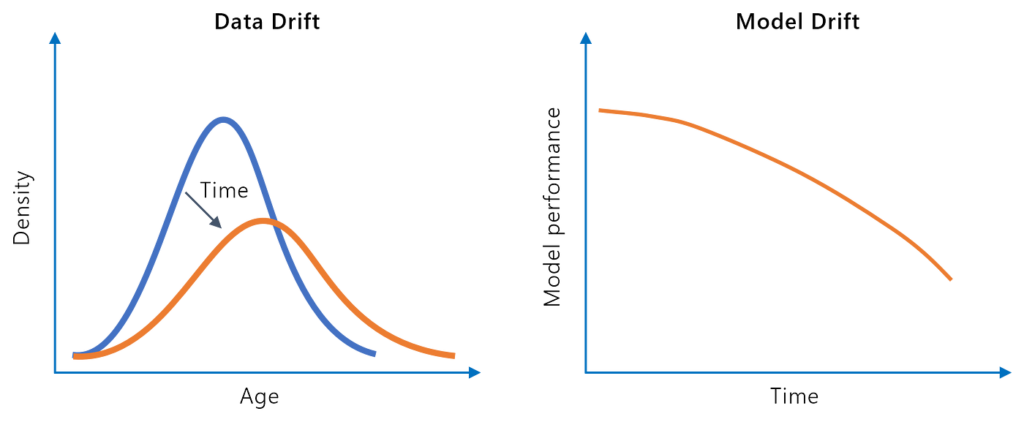
La deriva del modelo, o degradación del modelo, se refiere a la disminución en el rendimiento predictivo de un modelo de aprendizaje automático a lo largo del t...
El encadenamiento de modelos es una técnica de aprendizaje automático en la que varios modelos se enlazan secuencialmente, utilizando la salida de cada modelo c...
Google Colaboratory (Google Colab) es una plataforma de cuadernos Jupyter basada en la nube de Google, que permite a los usuarios escribir y ejecutar código Pyt...
El Impulso por Gradiente es una potente técnica de ensamblaje de aprendizaje automático para regresión y clasificación. Construye modelos secuencialmente, norma...
La inferencia causal es un enfoque metodológico utilizado para determinar las relaciones de causa y efecto entre variables, crucial en las ciencias para compren...
Explora cómo la Ingeniería y Extracción de Características mejoran el rendimiento de los modelos de IA al transformar datos en bruto en información valiosa. Des...
Jupyter Notebook es una aplicación web de código abierto que permite a los usuarios crear y compartir documentos con código en vivo, ecuaciones, visualizaciones...
Kaggle es una comunidad y plataforma en línea para científicos de datos e ingenieros de aprendizaje automático para colaborar, aprender, competir y compartir co...
La limpieza de datos es el proceso crucial de detectar y corregir errores o inconsistencias en los datos para mejorar su calidad, asegurando precisión, consiste...
La minería de datos es un proceso sofisticado de análisis de grandes conjuntos de datos en bruto para descubrir patrones, relaciones y conocimientos que pueden ...
El modelado predictivo es un proceso sofisticado en la ciencia de datos y la estadística que pronostica resultados futuros analizando patrones de datos históric...
NumPy es una biblioteca de Python de código abierto crucial para la computación numérica, que proporciona operaciones eficientes con arrays y funciones matemáti...
Pandas es una biblioteca de manipulación y análisis de datos de código abierto para Python, reconocida por su versatilidad, estructuras de datos robustas y faci...
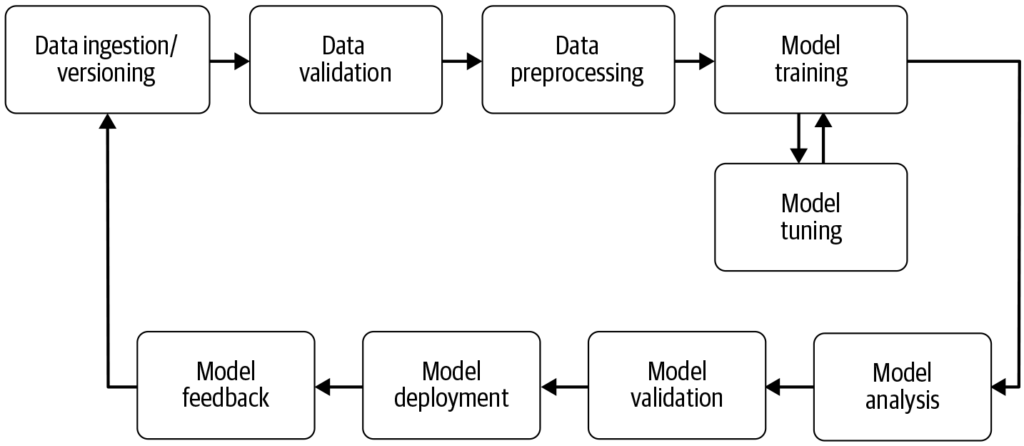
Un pipeline de aprendizaje automático es un flujo de trabajo automatizado que agiliza y estandariza el desarrollo, entrenamiento, evaluación y despliegue de mod...
El R-cuadrado ajustado es una medida estadística utilizada para evaluar la bondad de ajuste de un modelo de regresión, teniendo en cuenta el número de predictor...
La reducción de dimensionalidad es una técnica fundamental en el procesamiento de datos y el aprendizaje automático, que reduce el número de variables de entrad...
La regresión lineal es una técnica analítica fundamental en estadística y aprendizaje automático, que modela la relación entre variables dependientes e independ...
Scikit-learn es una potente biblioteca de aprendizaje automático de código abierto para Python, que proporciona herramientas simples y eficientes para el anális...
Explora el sesgo en IA: comprende sus fuentes, impacto en el aprendizaje automático, ejemplos del mundo real y estrategias de mitigación para construir sistemas...
El algoritmo de vecinos más cercanos (KNN) es un algoritmo de aprendizaje supervisado no paramétrico utilizado para tareas de clasificación y regresión en apren...