¿Qué es Fastai?
Fastai es una biblioteca de aprendizaje profundo construida sobre PyTorch, que ofrece APIs de alto nivel, aprendizaje por transferencia y una arquitectura por c...
12 min de lectura
Fastai
Deep Learning
+5
Fastai es una biblioteca de aprendizaje profundo construida sobre PyTorch, que ofrece APIs de alto nivel, aprendizaje por transferencia y una arquitectura por c...
El ajuste fino de modelos adapta modelos pre-entrenados a nuevas tareas realizando pequeñas modificaciones, reduciendo la necesidad de datos y recursos. Descubr...
AllenNLP es una sólida biblioteca de código abierto para la investigación en PLN, construida sobre PyTorch por AI2. Ofrece herramientas modulares y extensibles,...
El Aprendizaje por Refuerzo (RL) es una rama del aprendizaje automático centrada en entrenar agentes para tomar secuencias de decisiones dentro de un entorno, a...
El aprendizaje por transferencia es una técnica sofisticada de aprendizaje automático que permite reutilizar modelos entrenados en una tarea para otra relaciona...
El Aprendizaje por Transferencia es una poderosa técnica de IA/ML que adapta modelos preentrenados a nuevas tareas, mejorando el rendimiento con datos limitados...
El Aprendizaje Profundo es un subconjunto del aprendizaje automático en la inteligencia artificial (IA) que imita el funcionamiento del cerebro humano en el pro...
Descubre BERT (Bidirectional Encoder Representations from Transformers), un marco de aprendizaje automático de código abierto desarrollado por Google para el pr...
BMXNet es una implementación de código abierto de Redes Neuronales Binarias (BNN) basada en Apache MXNet, que permite un despliegue eficiente de IA con pesos y ...
Caffe es un framework de aprendizaje profundo de código abierto desarrollado por BVLC, optimizado para la velocidad y la modularidad en la construcción de redes...
Chainer es un framework de deep learning de código abierto que ofrece una plataforma flexible, intuitiva y de alto rendimiento para redes neuronales, con gráfic...
La computación neuromórfica es un enfoque de vanguardia en la ingeniería informática que modela tanto los elementos de hardware como de software según el cerebr...
La convergencia en la IA se refiere al proceso mediante el cual los modelos de aprendizaje automático y aprendizaje profundo alcanzan un estado estable a través...
DALL-E es una serie de modelos de texto a imagen desarrollados por OpenAI, que utilizan aprendizaje profundo para generar imágenes digitales a partir de descrip...
El descenso de gradiente es un algoritmo de optimización fundamental ampliamente utilizado en aprendizaje automático y aprendizaje profundo para minimizar funci...
La detección de anomalías en imágenes identifica patrones que se desvían de la norma, siendo crucial para aplicaciones como la inspección industrial y la imagen...
La Distancia de Incepción de Fréchet (FID) es una métrica utilizada para evaluar la calidad de las imágenes producidas por modelos generativos, en particular lo...
DL4J, o DeepLearning4J, es una biblioteca de aprendizaje profundo distribuido y de código abierto para la Máquina Virtual de Java (JVM). Como parte del ecosiste...
Dropout es una técnica de regularización en IA, especialmente en redes neuronales, que combate el sobreajuste desactivando aleatoriamente neuronas durante el en...
La estimación de pose es una técnica de visión por computadora que predice la posición y orientación de una persona u objeto en imágenes o videos identificando ...
Las funciones de activación son fundamentales para las redes neuronales artificiales, ya que introducen no linealidad y permiten el aprendizaje de patrones comp...
Horovod es un sólido marco de entrenamiento distribuido de aprendizaje profundo de código abierto, diseñado para facilitar el escalado eficiente en múltiples GP...
La Inteligencia Artificial (IA) en el sector salud aprovecha algoritmos avanzados y tecnologías como el aprendizaje automático, PLN y aprendizaje profundo para ...
La IA generativa se refiere a una categoría de algoritmos de inteligencia artificial que pueden generar contenido nuevo, como texto, imágenes, música, código y ...
Ideogram IA es una innovadora plataforma de generación de imágenes que utiliza inteligencia artificial para convertir indicaciones de texto en imágenes de alta ...
Keras es una API de redes neuronales de alto nivel, potente y fácil de usar, de código abierto, escrita en Python y capaz de ejecutarse sobre TensorFlow, CNTK o...
La Memoria a Largo Plazo Bidireccional (BiLSTM) es un tipo avanzado de arquitectura de Red Neuronal Recurrente (RNN) que procesa datos secuenciales en ambas dir...
La Memoria a Largo y Corto Plazo (LSTM) es un tipo especializado de arquitectura de Red Neuronal Recurrente (RNN) diseñada para aprender dependencias a largo pl...
Descubre el modelado de secuencias en IA y aprendizaje automático: predice y genera secuencias en datos como texto, audio y ADN usando RNNs, LSTMs, GRUs y Trans...
Un modelo de lenguaje grande (LLM) es un tipo de inteligencia artificial entrenada con grandes cantidades de datos textuales para comprender, generar y manipula...
Apache MXNet es un framework de aprendizaje profundo de código abierto diseñado para el entrenamiento y despliegue eficiente y flexible de redes neuronales prof...
La normalización por lotes es una técnica transformadora en el aprendizaje profundo que mejora significativamente el proceso de entrenamiento de redes neuronale...
El Procesamiento de Lenguaje Natural (PLN) permite a las computadoras comprender, interpretar y generar lenguaje humano utilizando lingüística computacional, ap...
PyTorch es un framework de aprendizaje automático de código abierto desarrollado por Meta AI, reconocido por su flexibilidad, gráficos computacionales dinámicos...
Descubre qué es el Reconocimiento de Imágenes en IA. Para qué se utiliza, cuáles son las tendencias y en qué se diferencia de tecnologías similares.
El Reconocimiento de Texto en Escenas (STR) es una rama especializada del Reconocimiento Óptico de Caracteres (OCR) enfocada en identificar e interpretar texto ...
El Reconocimiento Óptico de Caracteres (OCR) es una tecnología transformadora que convierte documentos como papeles escaneados, PDFs o imágenes en datos editabl...
Una Red Neuronal Convolucional (CNN) es un tipo especializado de red neuronal artificial diseñada para procesar datos en cuadrículas estructuradas, como imágene...
Las redes neuronales recurrentes (RNN) son una sofisticada clase de redes neuronales artificiales diseñadas para procesar datos secuenciales utilizando la memor...
Una Red de Creencias Profundas (DBN) es un sofisticado modelo generativo que utiliza arquitecturas profundas y Máquinas de Boltzmann Restringidas (RBMs) para ap...
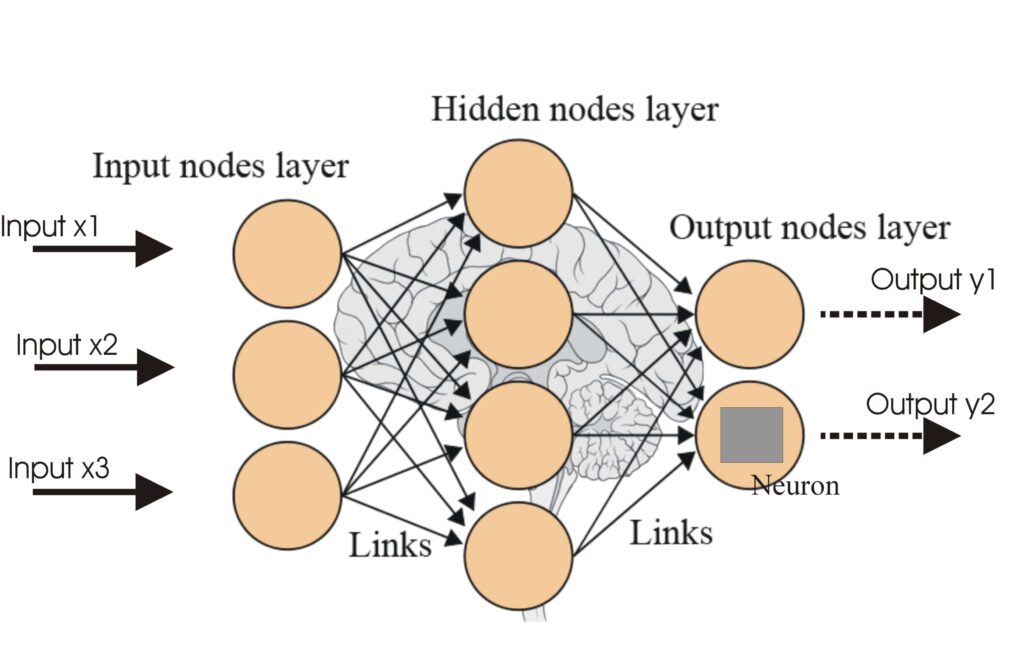
Una red neuronal, o red neuronal artificial (ANN), es un modelo computacional inspirado en el cerebro humano, esencial en la IA y el aprendizaje automático para...
Las Redes Neuronales Artificiales (ANNs) son un subconjunto de algoritmos de aprendizaje automático modelados a partir del cerebro humano. Estos modelos computa...
La retropropagación es un algoritmo para entrenar redes neuronales artificiales ajustando los pesos para minimizar el error de predicción. Descubre cómo funcion...
La segmentación de instancias es una tarea de visión por computadora que detecta y delimita cada objeto distinto en una imagen con precisión a nivel de píxel. M...
La segmentación semántica es una técnica de visión por computadora que divide las imágenes en múltiples segmentos, asignando a cada píxel una etiqueta de clase ...
Stable Diffusion es un modelo avanzado de generación de imágenes a partir de texto que utiliza aprendizaje profundo para producir imágenes fotorrealistas y de a...
TensorFlow es una biblioteca de código abierto desarrollada por el equipo de Google Brain, diseñada para el cálculo numérico y el aprendizaje automático a gran ...
Torch es una biblioteca de aprendizaje automático de código abierto y un marco de computación científica basado en Lua, optimizado para tareas de aprendizaje pr...
Un Transformador Generativo Preentrenado (GPT) es un modelo de IA que aprovecha técnicas de aprendizaje profundo para producir texto que imita de cerca la escri...
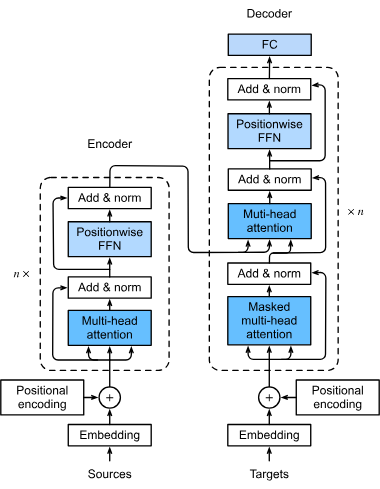
Los transformadores son una arquitectura revolucionaria de redes neuronales que ha transformado la inteligencia artificial, especialmente en el procesamiento de...
Un vector de embedding es una representación numérica densa de datos en un espacio multidimensional, capturando relaciones semánticas y contextuales. Descubre c...
La Visión por Computadora es un campo dentro de la inteligencia artificial (IA) enfocado en habilitar a las computadoras para interpretar y comprender el mundo ...