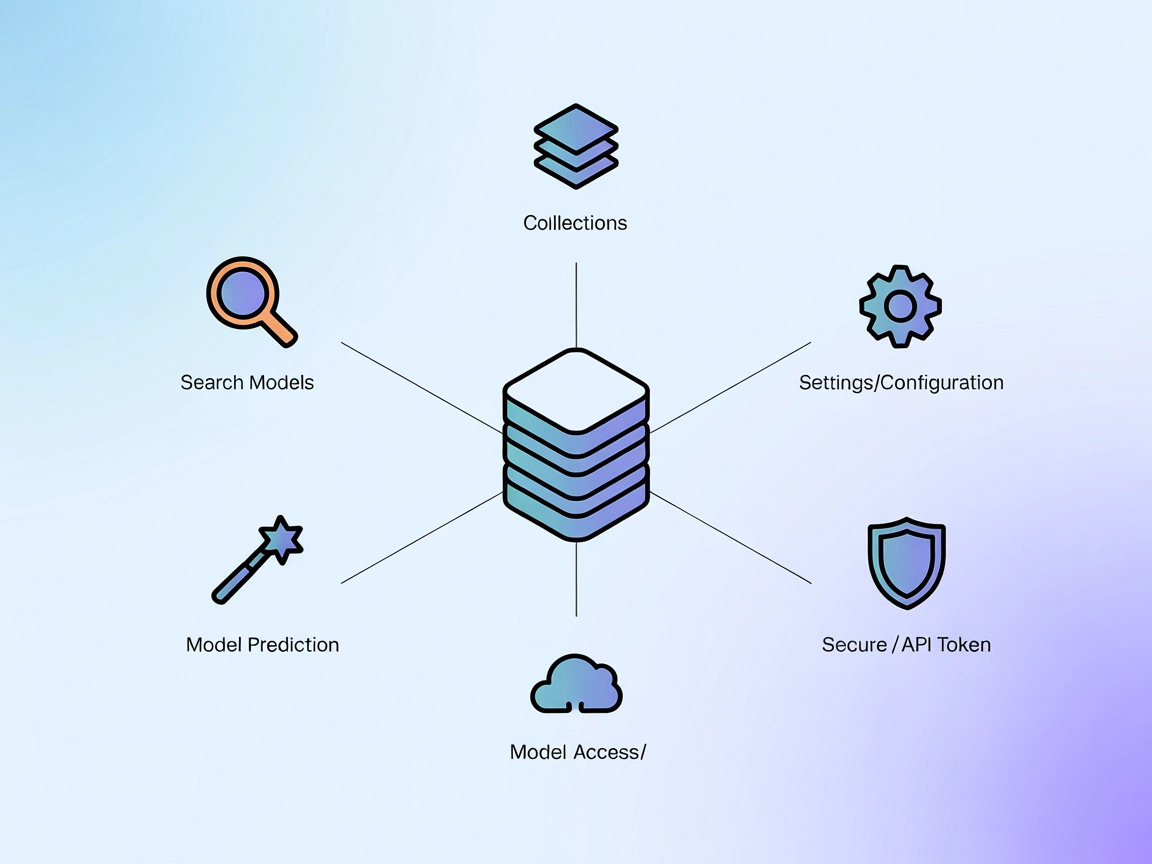
Integración del Servidor MCP de Replicate
El conector de Replicate MCP Server de FlowHunt permite un acceso fluido al extenso centro de modelos de IA de Replicate, facilitando a los desarrolladores busc...
5 min de lectura
AI
MCP Server
+5
El conector de Replicate MCP Server de FlowHunt permite un acceso fluido al extenso centro de modelos de IA de Replicate, facilitando a los desarrolladores busc...
Integra asistentes de IA con Label Studio usando el Servidor MCP de Label Studio. Gestiona sin problemas proyectos de etiquetado, tareas y predicciones a través...
Fastai es una biblioteca de aprendizaje profundo construida sobre PyTorch, que ofrece APIs de alto nivel, aprendizaje por transferencia y una arquitectura por c...
Descubre cómo '¿Quiso decir?' (DYM) en PLN identifica y corrige errores en la entrada del usuario, como errores tipográficos u ortográficos, y sugiere alternati...
Un agente inteligente es una entidad autónoma diseñada para percibir su entorno a través de sensores y actuar sobre ese entorno utilizando actuadores, equipada ...
La IA agéntica es una rama avanzada de la inteligencia artificial que capacita a los sistemas para actuar de forma autónoma, tomar decisiones y realizar tareas ...
El agrupamiento es una técnica de aprendizaje automático no supervisado que agrupa puntos de datos similares, permitiendo el análisis exploratorio de datos sin ...
El Agrupamiento K-Means es un popular algoritmo de aprendizaje automático no supervisado para dividir conjuntos de datos en un número predefinido de grupos dist...
El ajuste de hiperparámetros es un proceso fundamental en el aprendizaje automático para optimizar el rendimiento del modelo ajustando parámetros como la tasa d...
El ajuste fino de modelos adapta modelos pre-entrenados a nuevas tareas realizando pequeñas modificaciones, reduciendo la necesidad de datos y recursos. Descubr...
El Ajuste Fino Eficiente en Parámetros (PEFT) es un enfoque innovador en IA y PLN que permite adaptar grandes modelos preentrenados a tareas específicas actuali...
El ajuste por instrucciones es una técnica en IA que afina grandes modelos de lenguaje (LLMs) usando pares de instrucciones y respuestas, mejorando su capacidad...
Amazon SageMaker es un servicio de aprendizaje automático (ML) totalmente gestionado de AWS que permite a los científicos de datos y desarrolladores crear, entr...
El análisis de dependencias es un método de análisis sintáctico en PLN que identifica relaciones gramaticales entre palabras, formando estructuras en forma de á...
El análisis de sentimiento, también conocido como minería de opiniones, es una tarea crucial de IA y PLN para clasificar e interpretar el tono emocional de un t...
El análisis semántico es una técnica crucial del Procesamiento de Lenguaje Natural (PLN) que interpreta y deriva significado del texto, permitiendo que las máqu...
Un Analista de Datos con IA combina habilidades tradicionales de análisis de datos con inteligencia artificial (IA) y aprendizaje automático (ML) para extraer c...
Descubre más sobre la tecnología de analítica predictiva en IA, cómo funciona el proceso y cómo beneficia a diversas industrias.
El aprendizaje adaptativo es un método educativo transformador que aprovecha la tecnología para crear una experiencia de aprendizaje personalizada para cada est...
El Aprendizaje Automático (ML) es un subconjunto de la inteligencia artificial (IA) que permite a las máquinas aprender de los datos, identificar patrones, hace...
El aprendizaje de pocos ejemplos es un enfoque de aprendizaje automático que permite a los modelos hacer predicciones precisas utilizando solo un pequeño número...
El Aprendizaje Federado es una técnica colaborativa de aprendizaje automático en la que múltiples dispositivos entrenan un modelo compartido manteniendo los dat...
El aprendizaje no supervisado es una rama del aprendizaje automático enfocada en encontrar patrones, estructuras y relaciones en datos no etiquetados, permitien...
El aprendizaje no supervisado es una técnica de aprendizaje automático que entrena algoritmos con datos no etiquetados para descubrir patrones, estructuras y re...
El Aprendizaje por Refuerzo (RL) es una rama del aprendizaje automático centrada en entrenar agentes para tomar secuencias de decisiones dentro de un entorno, a...
El Aprendizaje por Refuerzo (RL) es un método de entrenamiento de modelos de aprendizaje automático donde un agente aprende a tomar decisiones realizando accion...
El Aprendizaje por Refuerzo a partir de Retroalimentación Humana (RLHF) es una técnica de aprendizaje automático que integra la intervención humana para guiar e...
El aprendizaje por transferencia es una técnica sofisticada de aprendizaje automático que permite reutilizar modelos entrenados en una tarea para otra relaciona...
El Aprendizaje por Transferencia es una poderosa técnica de IA/ML que adapta modelos preentrenados a nuevas tareas, mejorando el rendimiento con datos limitados...
El Aprendizaje Profundo es un subconjunto del aprendizaje automático en la inteligencia artificial (IA) que imita el funcionamiento del cerebro humano en el pro...
El aprendizaje semisupervisado (SSL) es una técnica de aprendizaje automático que aprovecha tanto datos etiquetados como no etiquetados para entrenar modelos, l...
El aprendizaje supervisado es un enfoque fundamental en el aprendizaje automático y la inteligencia artificial, donde los algoritmos aprenden a partir de conjun...
El aprendizaje supervisado es un concepto fundamental de la IA y el aprendizaje automático donde los algoritmos se entrenan con datos etiquetados para hacer pre...
El Aprendizaje Zero-Shot es un método en IA donde un modelo reconoce objetos o categorías de datos sin haber sido entrenado explícitamente en esas categorías, u...
Un árbol de decisión es una herramienta poderosa e intuitiva para la toma de decisiones y el análisis predictivo, utilizada en tareas de clasificación y regresi...
Un Árbol de Decisión es un algoritmo de aprendizaje supervisado utilizado para tomar decisiones o hacer predicciones basadas en datos de entrada. Se visualiza c...
El Área bajo la curva (AUC) es una métrica fundamental en aprendizaje automático utilizada para evaluar el rendimiento de modelos de clasificación binaria. Cuan...
La auto-clasificación automatiza la categorización de contenido analizando propiedades y asignando etiquetas mediante tecnologías como aprendizaje automático, P...
Bagging, abreviatura de Bootstrap Aggregating, es una técnica fundamental de aprendizaje en conjunto en IA y aprendizaje automático que mejora la precisión y ro...
Garbage In, Garbage Out (GIGO) resalta cómo la calidad de la salida de los sistemas de IA y otros sistemas depende directamente de la calidad de la entrada. Des...
Descubre BERT (Bidirectional Encoder Representations from Transformers), un marco de aprendizaje automático de código abierto desarrollado por Google para el pr...
Anaconda es una distribución integral y de código abierto de Python y R, diseñada para simplificar la gestión de paquetes y el despliegue para la computación ci...
BigML es una plataforma de aprendizaje automático diseñada para simplificar la creación y el despliegue de modelos predictivos. Fundada en 2011, su misión es ha...
Descubre cómo el sistema Blackwell de NVIDIA marca el inicio de una nueva era en la computación acelerada, revolucionando industrias a través de tecnología avan...
La Búsqueda por IA es una metodología de búsqueda semántica o basada en vectores que utiliza modelos de aprendizaje automático para comprender la intención y el...
Caffe es un framework de aprendizaje profundo de código abierto desarrollado por BVLC, optimizado para la velocidad y la modularidad en la construcción de redes...
Chainer es un framework de deep learning de código abierto que ofrece una plataforma flexible, intuitiva y de alto rendimiento para redes neuronales, con gráfic...
Explora las diferencias clave entre los chatbots con guion y los chatbots de IA, sus usos prácticos y cómo están transformando la interacción con los clientes e...
ChatGPT es un chatbot de IA de última generación desarrollado por OpenAI, que utiliza un avanzado Procesamiento de Lenguaje Natural (PLN) para permitir conversa...
La clasificación de texto, también conocida como categorización o etiquetado de texto, es una tarea central de PLN que asigna categorías predefinidas a document...
Un clasificador de IA es un algoritmo de aprendizaje automático que asigna etiquetas de clase a datos de entrada, categorizando la información en clases predefi...
Descubre más sobre Claude 3.5 Sonnet de Anthropic: cómo se compara con otros modelos, sus fortalezas, debilidades y aplicaciones en áreas como razonamiento, pro...
Clearbit es una potente plataforma de activación de datos que ayuda a las empresas, especialmente a los equipos de ventas y marketing, a enriquecer los datos de...
El colapso del modelo es un fenómeno en la inteligencia artificial donde un modelo entrenado se degrada con el tiempo, especialmente cuando depende de datos sin...
Aprende los fundamentos de la clasificación de intenciones en IA, sus técnicas, aplicaciones en el mundo real, desafíos y tendencias futuras para mejorar la int...
Descubre la importancia y las aplicaciones del Human in the Loop (HITL) en los chatbots de IA, donde la experiencia humana mejora los sistemas de IA para lograr...
Explora los fundamentos del razonamiento de la IA, incluyendo sus tipos, importancia y aplicaciones en el mundo real. Descubre cómo la IA imita el pensamiento h...
La computación cognitiva representa un modelo tecnológico transformador que simula los procesos de pensamiento humano en escenarios complejos. Integra IA y proc...
Un Consultor de IA conecta la tecnología de inteligencia artificial con la estrategia empresarial, guiando a las empresas en la integración de IA para impulsar ...
La convergencia en la IA se refiere al proceso mediante el cual los modelos de aprendizaje automático y aprendizaje profundo alcanzan un estado estable a través...
Un corpus (plural: corpora) en IA se refiere a un conjunto grande y estructurado de textos o datos de audio utilizados para entrenar y evaluar modelos de IA. Lo...
Descubre los costos asociados con el entrenamiento y la implementación de Modelos de Lenguaje Grandes (LLMs) como GPT-3 y GPT-4, incluyendo gastos computacional...
La Creación de Contenido con IA aprovecha la inteligencia artificial para automatizar y mejorar la generación, curación y personalización de contenido digital e...
Ideogram.ai es una potente herramienta que democratiza la creación de imágenes con IA, haciéndola accesible para una amplia variedad de usuarios. Explora su int...
Una curva de aprendizaje en inteligencia artificial es una representación gráfica que ilustra la relación entre el rendimiento de aprendizaje de un modelo y var...
Una curva Característica Operativa del Receptor (ROC) es una representación gráfica utilizada para evaluar el rendimiento de un sistema clasificador binario a m...
DataRobot es una plataforma integral de IA que simplifica la creación, implementación y gestión de modelos de aprendizaje automático, haciendo que la IA predict...
Los datos de entrenamiento se refieren al conjunto de datos utilizado para instruir algoritmos de IA, permitiéndoles reconocer patrones, tomar decisiones y pred...
Descubre qué son los datos no estructurados y cómo se comparan con los estructurados. Aprende sobre los desafíos y las herramientas utilizadas para datos no est...
Los datos sintéticos se refieren a información generada artificialmente que imita datos del mundo real. Se crean mediante algoritmos y simulaciones por computad...
Los deepfakes son una forma de medios sintéticos donde la IA se utiliza para generar imágenes, videos o grabaciones de audio muy realistas pero falsas. El térmi...
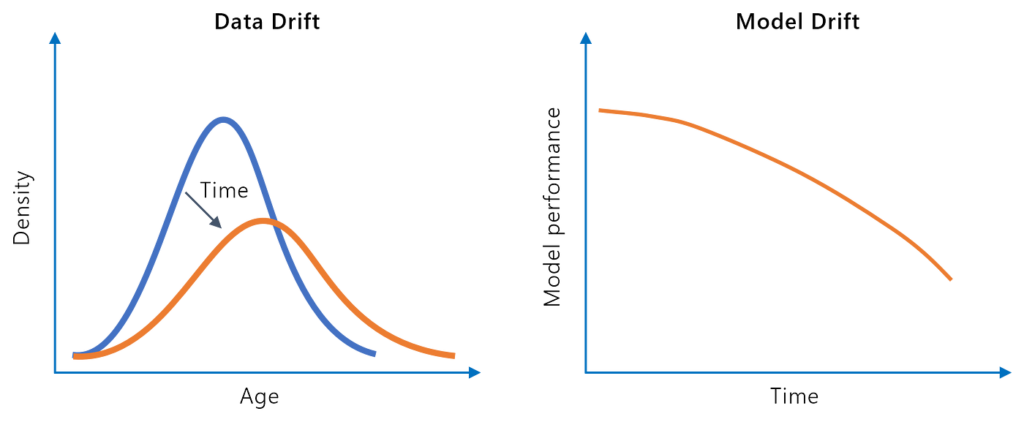
La deriva del modelo, o degradación del modelo, se refiere a la disminución en el rendimiento predictivo de un modelo de aprendizaje automático a lo largo del t...
El Desarrollo de Prototipos de IA es el proceso iterativo de diseñar y crear versiones preliminares de sistemas de IA, lo que permite la experimentación, valida...
El descenso de gradiente es un algoritmo de optimización fundamental ampliamente utilizado en aprendizaje automático y aprendizaje profundo para minimizar funci...
Explora el mundo de los modelos de agentes de IA con un análisis completo de 20 sistemas de vanguardia. Descubre cómo piensan, razonan y se desempeñan en divers...
La detección de anomalías es el proceso de identificar puntos de datos, eventos o patrones que se desvían de la norma esperada dentro de un conjunto de datos, a...
La detección de fraude financiero con IA se refiere a la aplicación de tecnologías de inteligencia artificial para identificar y prevenir actividades fraudulent...
La detección de fraudes con IA aprovecha el aprendizaje automático para identificar y mitigar actividades fraudulentas en tiempo real. Mejora la precisión, la e...
DL4J, o DeepLearning4J, es una biblioteca de aprendizaje profundo distribuido y de código abierto para la Máquina Virtual de Java (JVM). Como parte del ecosiste...
Dropout es una técnica de regularización en IA, especialmente en redes neuronales, que combate el sobreajuste desactivando aleatoriamente neuronas durante el en...
Descubre cómo la IA agéntica y los sistemas multiagente revolucionan la automatización de flujos de trabajo con toma de decisiones autónoma, adaptabilidad y col...
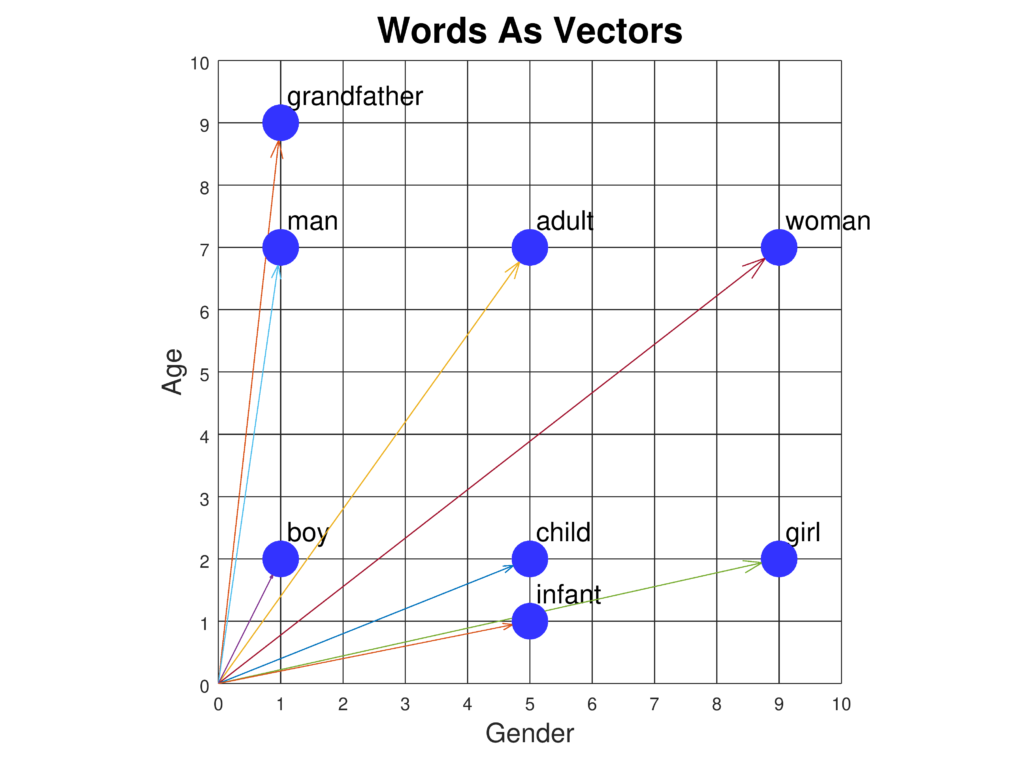
Los embeddings de palabras son representaciones sofisticadas de las palabras en un espacio vectorial continuo, capturando relaciones semánticas y sintácticas pa...
El encadenamiento de modelos es una técnica de aprendizaje automático en la que varios modelos se enlazan secuencialmente, utilizando la salida de cada modelo c...
La entropía cruzada es un concepto fundamental tanto en la teoría de la información como en el aprendizaje automático, y sirve como una métrica para medir la di...
El Error Absoluto Medio (MAE) es una métrica fundamental en aprendizaje automático para evaluar modelos de regresión. Mide la magnitud promedio de los errores e...
El error de entrenamiento en IA y aprendizaje automático es la discrepancia entre las salidas predichas por un modelo y las salidas reales durante el entrenamie...
El error de generalización mide qué tan bien un modelo de aprendizaje automático predice datos no vistos, equilibrando el sesgo y la varianza para asegurar apli...
La escasez de datos se refiere a la falta de datos suficientes para entrenar modelos de aprendizaje automático o realizar análisis completos, lo que dificulta e...
Un Especialista en Garantía de Calidad de IA asegura la precisión, fiabilidad y rendimiento de los sistemas de IA mediante el desarrollo de planes de prueba, la...
La estimación de pose es una técnica de visión por computadora que predice la posición y orientación de una persona u objeto en imágenes o videos identificando ...
La Explicabilidad en IA se refiere a la capacidad de comprender e interpretar las decisiones y predicciones realizadas por los sistemas de inteligencia artifici...
La extracción de características transforma datos en bruto en un conjunto reducido de características informativas, mejorando el aprendizaje automático al simpl...
Descubre una solución escalable en Python para la extracción de datos de facturas utilizando OCR basado en IA. Aprende a convertir PDFs, subir imágenes a la API...
Una fecha de corte de conocimiento es el punto específico en el tiempo después del cual un modelo de IA ya no tiene información actualizada. Descubra por qué es...
Las funciones de activación son fundamentales para las redes neuronales artificiales, ya que introducen no linealidad y permiten el aprendizaje de patrones comp...
Aprende cómo automatizar la creación de textos descriptivos a partir de imágenes usando la API y el generador de flujos de FlowHunt.io, mejorando la presencia e...
Descubre las diferencias clave entre la generación aumentada por recuperación (RAG) y la generación aumentada por caché (CAG) en IA. Aprende cómo RAG recupera i...
Gensim es una popular biblioteca de Python de código abierto para procesamiento de lenguaje natural (NLP), especializada en modelado de temas no supervisado, in...
La Gestión de Proyectos de IA en I+D se refiere a la aplicación estratégica de tecnologías de inteligencia artificial (IA) y aprendizaje automático (ML) para me...
Google Colaboratory (Google Colab) es una plataforma de cuadernos Jupyter basada en la nube de Google, que permite a los usuarios escribir y ejecutar código Pyt...
Mostrando 1 a 100 de 211 resultados