Aprendizaje Profundo
El Aprendizaje Profundo es un subconjunto del aprendizaje automático en la inteligencia artificial (IA) que imita el funcionamiento del cerebro humano en el pro...
4 min de lectura
Deep Learning
AI
+5
El Aprendizaje Profundo es un subconjunto del aprendizaje automático en la inteligencia artificial (IA) que imita el funcionamiento del cerebro humano en el pro...
Descubre cómo el sistema Blackwell de NVIDIA marca el inicio de una nueva era en la computación acelerada, revolucionando industrias a través de tecnología avan...
Chainer es un framework de deep learning de código abierto que ofrece una plataforma flexible, intuitiva y de alto rendimiento para redes neuronales, con gráfic...
Explora los fundamentos del razonamiento de la IA, incluyendo sus tipos, importancia y aplicaciones en el mundo real. Descubre cómo la IA imita el pensamiento h...
Explora las capacidades avanzadas del Agente de IA Claude 3. Este análisis en profundidad revela cómo Claude 3 va más allá de la generación de texto, mostrando ...
El descenso de gradiente es un algoritmo de optimización fundamental ampliamente utilizado en aprendizaje automático y aprendizaje profundo para minimizar funci...
Dropout es una técnica de regularización en IA, especialmente en redes neuronales, que combate el sobreajuste desactivando aleatoriamente neuronas durante el en...
Las funciones de activación son fundamentales para las redes neuronales artificiales, ya que introducen no linealidad y permiten el aprendizaje de patrones comp...
Descubre el Generador de Leyendas para Imágenes potenciado por IA de FlowHunt. Crea al instante leyendas atractivas y relevantes para tus imágenes con temas y t...
Keras es una API de redes neuronales de alto nivel, potente y fácil de usar, de código abierto, escrita en Python y capaz de ejecutarse sobre TensorFlow, CNTK o...
La Memoria a Largo Plazo Bidireccional (BiLSTM) es un tipo avanzado de arquitectura de Red Neuronal Recurrente (RNN) que procesa datos secuenciales en ambas dir...
La Memoria a Largo y Corto Plazo (LSTM) es un tipo especializado de arquitectura de Red Neuronal Recurrente (RNN) diseñada para aprender dependencias a largo pl...
La memoria asociativa en la inteligencia artificial (IA) permite a los sistemas recordar información basada en patrones y asociaciones, imitando la memoria huma...
Apache MXNet es un framework de aprendizaje profundo de código abierto diseñado para el entrenamiento y despliegue eficiente y flexible de redes neuronales prof...
La normalización por lotes es una técnica transformadora en el aprendizaje profundo que mejora significativamente el proceso de entrenamiento de redes neuronale...
El reconocimiento de patrones es un proceso computacional para identificar patrones y regularidades en los datos, crucial en campos como la IA, la informática, ...
Una Red Generativa Antagónica (GAN) es un marco de aprendizaje automático con dos redes neuronales—un generador y un discriminador—que compiten para generar dat...
Las redes neuronales recurrentes (RNN) son una sofisticada clase de redes neuronales artificiales diseñadas para procesar datos secuenciales utilizando la memor...
Una Red de Creencias Profundas (DBN) es un sofisticado modelo generativo que utiliza arquitecturas profundas y Máquinas de Boltzmann Restringidas (RBMs) para ap...
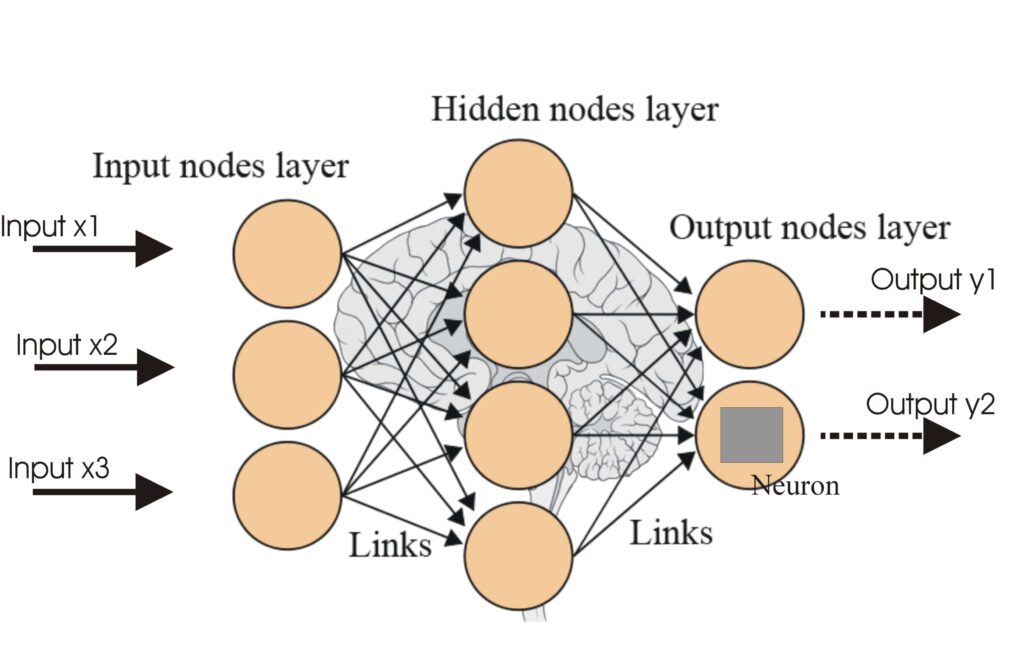
Una red neuronal, o red neuronal artificial (ANN), es un modelo computacional inspirado en el cerebro humano, esencial en la IA y el aprendizaje automático para...
Las Redes Neuronales Artificiales (ANNs) son un subconjunto de algoritmos de aprendizaje automático modelados a partir del cerebro humano. Estos modelos computa...
La regularización en inteligencia artificial (IA) se refiere a un conjunto de técnicas utilizadas para evitar el sobreajuste en los modelos de aprendizaje autom...
La retropropagación es un algoritmo para entrenar redes neuronales artificiales ajustando los pesos para minimizar el error de predicción. Descubre cómo funcion...
Torch es una biblioteca de aprendizaje automático de código abierto y un marco de computación científica basado en Lua, optimizado para tareas de aprendizaje pr...
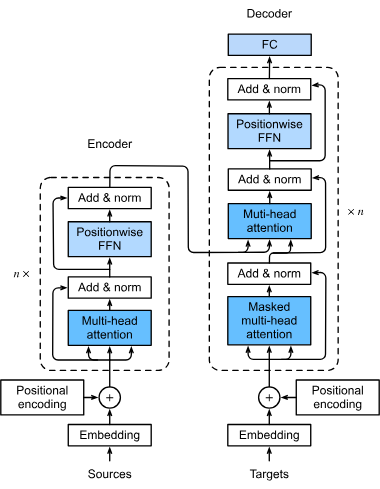
Un modelo transformador es un tipo de red neuronal específicamente diseñada para manejar datos secuenciales, como texto, voz o datos de series temporales. A dif...
Los transformadores son una arquitectura revolucionaria de redes neuronales que ha transformado la inteligencia artificial, especialmente en el procesamiento de...