How to Test AI Chatbot
Learn comprehensive AI chatbot testing strategies including functional, performance, security, and usability testing. Discover best practices, tools, and framew...
12 min read
Learn comprehensive methods to measure AI helpdesk chatbot accuracy in 2025. Discover precision, recall, F1 scores, user satisfaction metrics, and advanced evaluation techniques with FlowHunt.
Measure AI helpdesk chatbot accuracy using multiple metrics including precision and recall calculations, confusion matrices, user satisfaction scores, resolution rates, and advanced LLM-based evaluation methods. FlowHunt provides comprehensive tools for automated accuracy assessment and performance monitoring.
Measuring the accuracy of an AI helpdesk chatbot is essential for ensuring it delivers reliable, helpful responses to customer inquiries. Unlike simple classification tasks, chatbot accuracy encompasses multiple dimensions that must be evaluated together to provide a complete picture of performance. The process involves analyzing how well the chatbot understands user queries, provides correct information, resolves issues effectively, and maintains user satisfaction throughout interactions. A comprehensive accuracy measurement strategy combines quantitative metrics with qualitative feedback to identify strengths and areas requiring improvement.
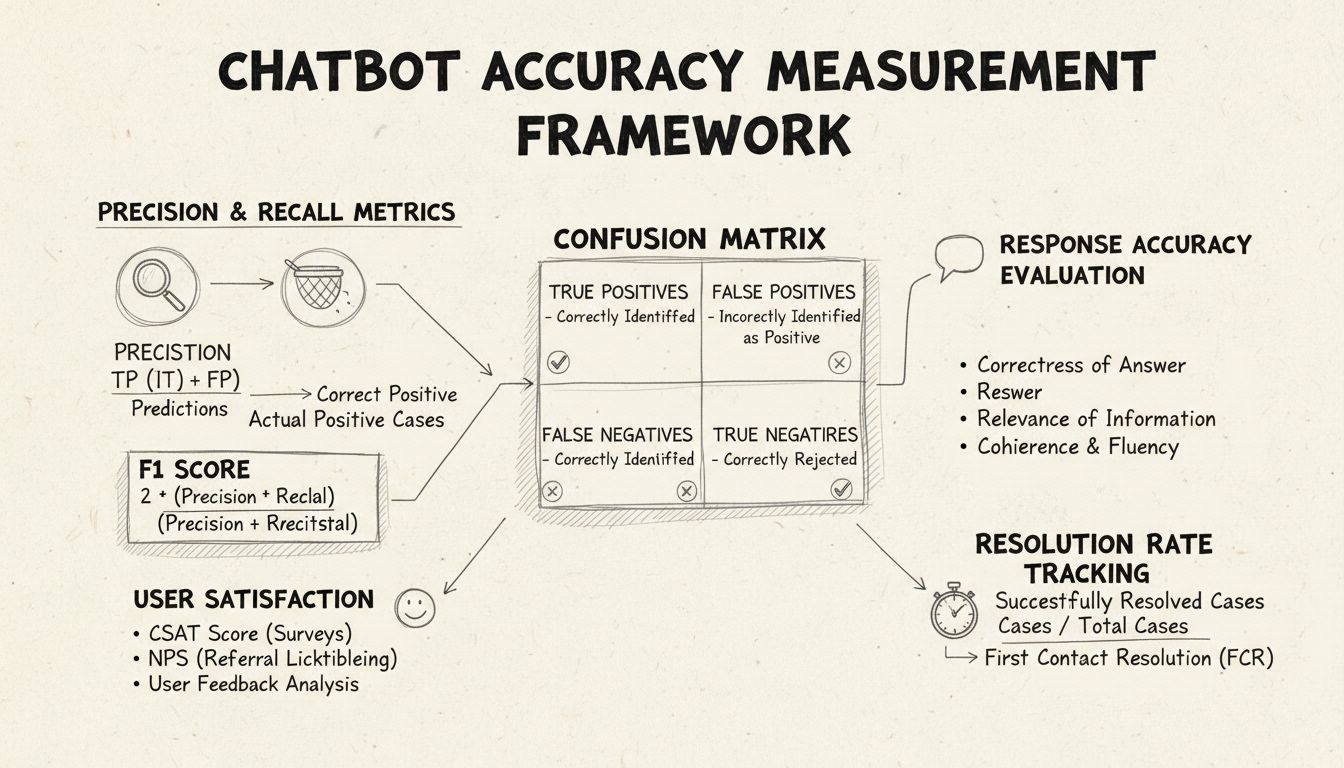
Precision and recall are fundamental metrics derived from the confusion matrix that measure different aspects of chatbot performance. Precision represents the proportion of correct responses out of all responses the chatbot provided, calculated using the formula: Precision = True Positives / (True Positives + False Positives). This metric answers the question: “When the chatbot provides an answer, how often is it correct?” A high precision score indicates the chatbot rarely gives incorrect information, which is critical for maintaining user trust in helpdesk scenarios.
Recall, also known as sensitivity, measures the proportion of correct responses out of all the correct answers the chatbot should have provided, using the formula: Recall = True Positives / (True Positives + False Negatives). This metric addresses whether the chatbot successfully identifies and responds to all legitimate customer issues. In helpdesk contexts, high recall ensures that customers receive assistance for their problems rather than being told the chatbot cannot help when it actually could. The relationship between precision and recall creates a natural trade-off: optimizing for one often reduces the other, requiring careful balance based on your specific business priorities.
The F1 Score provides a single metric that balances both precision and recall, calculated as the harmonic mean: F1 = 2 × (Precision × Recall) / (Precision + Recall). This metric proves particularly valuable when you need a unified performance indicator or when dealing with imbalanced datasets where one class significantly outnumbers others. For example, if your chatbot handles 1,000 routine inquiries but only 50 complex escalations, the F1 Score prevents the metric from being skewed by the majority class. The F1 Score ranges from 0 to 1, with 1 representing perfect precision and recall, making it intuitive for stakeholders to understand overall chatbot performance at a glance.
The confusion matrix is a foundational tool that breaks down chatbot performance into four categories: True Positives (correct responses to valid queries), True Negatives (correctly declining to answer out-of-scope questions), False Positives (incorrect responses), and False Negatives (missed opportunities to help). This matrix reveals specific patterns in chatbot failures, enabling targeted improvements. For instance, if the matrix shows high false negatives for billing inquiries, you can identify that the chatbot’s training data lacks sufficient billing-related examples and needs enhancement in that domain.
| Metric | Definition | Calculation | Business Impact |
|---|---|---|---|
| True Positives (TP) | Correct responses to valid queries | Counted directly | Builds customer trust |
| True Negatives (TN) | Correctly declining out-of-scope questions | Counted directly | Prevents misinformation |
| False Positives (FP) | Incorrect responses provided | Counted directly | Damages credibility |
| False Negatives (FN) | Missed opportunities to help | Counted directly | Reduces satisfaction |
| Precision | Quality of positive predictions | TP / (TP + FP) | Reliability metric |
| Recall | Coverage of actual positives | TP / (TP + FN) | Completeness metric |
| Accuracy | Overall correctness | (TP + TN) / Total | General performance |
Response accuracy measures how often the chatbot provides factually correct information that directly addresses the user’s query. This goes beyond simple pattern matching to evaluate whether the content is accurate, current, and appropriate for the context. Manual review processes involve having human evaluators assess a random sample of conversations, comparing chatbot responses against a predefined knowledge base of correct answers. Automated comparison methods can be implemented using natural language processing techniques to match responses against expected answers stored in your system, though these require careful calibration to avoid false negatives when the chatbot provides correct information using different wording than the reference answer.
Response relevance evaluates whether the chatbot’s answer actually addresses what the user asked, even if the answer isn’t perfectly correct. This dimension captures situations where the chatbot provides helpful information that, while not the exact answer, moves the conversation toward resolution. NLP-based methods like cosine similarity can measure semantic similarity between the user’s question and the chatbot’s response, providing an automated relevance score. User feedback mechanisms, such as thumbs-up/thumbs-down ratings after each interaction, offer direct relevance assessment from the people who matter most—your customers. These feedback signals should be continuously collected and analyzed to identify patterns in which types of queries the chatbot handles well versus poorly.
The Customer Satisfaction Score (CSAT) measures user satisfaction with chatbot interactions through direct surveys, typically using a 1-5 scale or simple satisfaction ratings. After each interaction, users are asked to rate their satisfaction, providing immediate feedback on whether the chatbot met their needs. CSAT scores above 80% generally indicate strong performance, while scores below 60% signal significant issues requiring investigation. The advantage of CSAT is its simplicity and directness—users explicitly state whether they’re satisfied—but it can be influenced by factors beyond chatbot accuracy, such as the complexity of the issue or user expectations.
Net Promoter Score measures the likelihood of users recommending the chatbot to others, calculated by asking “How likely are you to recommend this chatbot to a colleague?” on a 0-10 scale. Respondents rating 9-10 are promoters, 7-8 are passives, and 0-6 are detractors. NPS = (Promoters - Detractors) / Total Respondents × 100. This metric correlates strongly with long-term customer loyalty and provides insight into whether the chatbot creates positive experiences that users want to share. An NPS above 50 is considered excellent, while negative NPS indicates serious performance issues.
Sentiment analysis examines the emotional tone of user messages before and after chatbot interactions to gauge satisfaction. Advanced NLP techniques classify messages as positive, neutral, or negative, revealing whether users become more satisfied or frustrated during conversations. A positive sentiment shift indicates the chatbot successfully resolved concerns, while negative shifts suggest the chatbot may have frustrated users or failed to address their needs. This metric captures emotional dimensions that traditional accuracy metrics miss, providing valuable context for understanding user experience quality.
First Contact Resolution measures the percentage of customer issues resolved by the chatbot without requiring escalation to human agents. This metric directly impacts operational efficiency and customer satisfaction, as customers prefer resolving issues immediately rather than being transferred. FCR rates above 70% indicate strong chatbot performance, while rates below 50% suggest the chatbot lacks sufficient knowledge or capability to handle common inquiries. Tracking FCR by issue category reveals which types of problems the chatbot handles well and which require human intervention, guiding training and knowledge base improvements.
The escalation rate measures how often the chatbot hands off conversations to human agents, while fallback frequency tracks how often the chatbot defaults to generic responses like “I don’t understand” or “Please rephrase your question.” High escalation rates (above 30%) indicate the chatbot lacks knowledge or confidence in many scenarios, while high fallback rates suggest poor intent recognition or insufficient training data. These metrics identify specific gaps in chatbot capabilities that can be addressed through knowledge base expansion, model retraining, or improved natural language understanding components.
Response time measures how quickly the chatbot replies to user messages, typically measured in milliseconds to seconds. Users expect near-instantaneous responses; delays above 3-5 seconds significantly impact satisfaction. Handle time measures the total duration from when a user initiates contact until the issue is resolved or escalated, providing insight into chatbot efficiency. Shorter handle times indicate the chatbot quickly understands and resolves issues, while longer times suggest the chatbot requires multiple clarification rounds or struggles with complex queries. These metrics should be tracked separately for different issue categories, as complex technical problems naturally require longer handle times than simple FAQ questions.
LLM As a Judge represents a sophisticated evaluation approach where one large language model assesses the quality of another AI system’s outputs. This methodology proves particularly effective for evaluating chatbot responses across multiple quality dimensions simultaneously, such as accuracy, relevance, coherence, fluency, safety, completeness, and tone. Research demonstrates that LLM judges can achieve up to 85% alignment with human evaluations, making them a scalable alternative to manual review. The approach involves defining specific evaluation criteria, crafting detailed judge prompts with examples, providing the judge with both the original user query and the chatbot’s response, and receiving structured scores or detailed feedback.
The LLM As a Judge process typically employs two evaluation approaches: single output evaluation, where the judge scores an individual response using either referenceless evaluation (without ground truth) or reference-based comparison (against an expected response), and pairwise comparison, where the judge compares two outputs to identify the superior one. This flexibility allows evaluation of both absolute performance and relative improvements when testing different chatbot versions or configurations. FlowHunt’s platform supports LLM As a Judge implementations through its drag-and-drop interface, integration with leading LLMs like ChatGPT and Claude, and CLI toolkit for advanced reporting and automated evaluations.
Beyond basic accuracy calculations, detailed confusion matrix analysis reveals specific patterns in chatbot failures. By examining which types of queries produce false positives versus false negatives, you can identify systematic weaknesses. For example, if the matrix shows the chatbot frequently misclassifies billing questions as technical support issues, this reveals a training data imbalance or intent recognition problem specific to billing domain. Creating separate confusion matrices for different issue categories enables targeted improvements rather than generic model retraining.
A/B testing compares different versions of the chatbot to determine which performs better on key metrics. This might involve testing different response templates, knowledge base configurations, or underlying language models. By randomly routing a portion of traffic to each version and comparing metrics like FCR rate, CSAT scores, and response accuracy, you can make data-driven decisions about which improvements to implement. A/B testing should run for sufficient duration to capture natural variation in user queries and ensure statistical significance of results.
FlowHunt provides an integrated platform for building, deploying, and evaluating AI helpdesk chatbots with advanced accuracy measurement capabilities. The platform’s visual builder enables non-technical users to create sophisticated chatbot flows, while its AI components integrate with leading language models like ChatGPT and Claude. FlowHunt’s evaluation toolkit supports implementing LLM As a Judge methodology, allowing you to define custom evaluation criteria and automatically assess chatbot performance across your entire conversation dataset.
To implement comprehensive accuracy measurement with FlowHunt, begin by defining your specific evaluation criteria aligned with business objectives—whether prioritizing accuracy, speed, user satisfaction, or resolution rates. Configure the platform’s judging LLM with detailed prompts that specify how to evaluate responses, including concrete examples of high-quality and poor responses. Upload your conversation dataset or connect live traffic, then run evaluations to generate detailed reports showing performance across all metrics. FlowHunt’s dashboard provides real-time visibility into chatbot performance, enabling rapid identification of issues and validation of improvements.
Establish a baseline measurement before implementing improvements, creating a reference point for evaluating the impact of changes. Collect measurements continuously rather than periodically, enabling early detection of performance degradation due to data drift or model decay. Implement feedback loops where user ratings and corrections automatically feed back into the training process, continuously improving chatbot accuracy. Segment metrics by issue category, user type, and time period to identify specific areas requiring attention rather than relying solely on aggregate statistics.
Ensure your evaluation dataset represents real user queries and expected responses, avoiding artificial test cases that don’t reflect actual usage patterns. Regularly validate automated metrics against human judgment by having evaluators manually assess a sample of conversations, ensuring your measurement system remains calibrated to actual quality. Document your measurement methodology and metrics definitions clearly, enabling consistent evaluation over time and clear communication of results to stakeholders. Finally, establish performance targets for each metric aligned with business objectives, creating accountability for continuous improvement and providing clear goals for optimization efforts.
FlowHunt's advanced AI automation platform helps you create, deploy, and evaluate high-performing helpdesk chatbots with built-in accuracy measurement tools and LLM-based evaluation capabilities.
Learn comprehensive AI chatbot testing strategies including functional, performance, security, and usability testing. Discover best practices, tools, and framew...
Master AI chatbot usage with our comprehensive guide. Learn effective prompting techniques, best practices, and how to get the most from AI chatbots in 2025. Di...
Learn the best ways to greet AI chatbots and optimize your interactions. Discover greeting techniques, prompt engineering tips, and communication strategies for...