
Bard AI Chatbot: Which Company Developed It?
Discover which company developed Bard AI chatbot. Learn about Google's Gemini LLM, its features, capabilities, and how it compares to ChatGPT in 2025.
10 min read
Discover what Google Gemini is, how it works, and how it compares to ChatGPT. Learn about its multimodal capabilities, pricing, and real-world applications for 2025.
Google Gemini is a multimodal AI chatbot and large language model developed by Google DeepMind that can process and generate text, images, audio, and video. Launched in December 2023 and renamed from Bard in February 2024, Gemini powers Google's AI assistant across Pixel phones, Google Search, and Workspace applications.
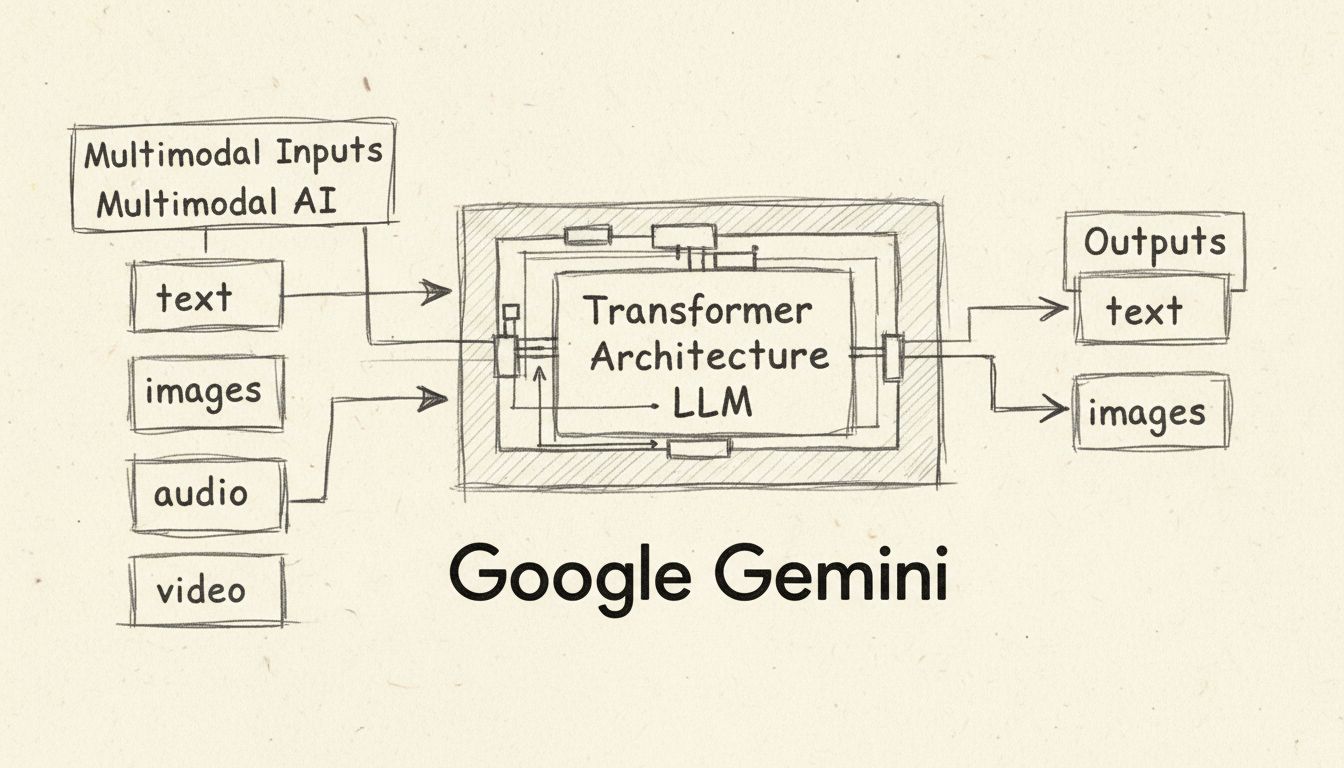
Google Gemini represents a significant advancement in artificial intelligence technology, fundamentally changing how users interact with AI-powered tools. Originally launched as Bard in March 2023, Google rebranded its AI assistant to Gemini in February 2024, reflecting the underlying large language model (LLM) that powers the platform. Gemini is not just a simple chatbot—it’s a sophisticated family of multimodal AI models developed by Google DeepMind that can understand and generate content across multiple data types simultaneously. This breakthrough capability distinguishes Gemini from earlier generation AI tools that primarily focused on text-based interactions. The platform has been integrated across Google’s entire ecosystem, from Pixel smartphones to Google Search and Workspace applications, making it one of the most accessible AI assistants available to consumers and enterprises worldwide.
Gemini’s defining characteristic is its multimodal architecture, which means it can process and generate multiple types of data simultaneously. Unlike ChatGPT, which primarily handles text-based inputs and outputs, Gemini natively supports text, images, audio, and video as both inputs and outputs. This multimodal capability enables Gemini to understand complex visual information such as charts, diagrams, and photographs without requiring external optical character recognition (OCR) tools. The model can analyze handwritten notes, graphs, and technical drawings to solve intricate problems that would require multiple specialized tools in traditional workflows. Additionally, Gemini supports audio processing across more than 100 languages, enabling real-time speech recognition and translation capabilities. The video understanding feature allows Gemini to process video frames and answer questions about video content, making it invaluable for content analysis and summarization tasks.
The transformer-based neural network architecture that powers Gemini has been specifically enhanced to handle lengthy contextual sequences across different data types. Google DeepMind implemented efficient attention mechanisms in the transformer decoder to help the models process extended contexts, with some versions supporting up to 2 million tokens—significantly more than ChatGPT’s 128,000-token limit. This expanded context window enables Gemini to analyze entire books, lengthy reports, and thousands of lines of code in a single interaction, providing more comprehensive and contextually aware responses.
Google offers multiple versions of Gemini, each optimized for specific use cases and deployment environments. Understanding these variants is crucial for selecting the appropriate model for your requirements. The Gemini 1.0 Nano is the smallest version designed for on-device mobile applications, capable of running on Android devices like the Pixel 8 Pro without requiring internet connectivity. Nano can perform tasks such as describing images, suggesting chat replies, summarizing text, and transcribing speech directly on your device. The Gemini 1.0 Ultra represents the most powerful version of the first generation, built for highly complex tasks including advanced coding, mathematical reasoning, and sophisticated multimodal reasoning. Both Nano and Ultra versions feature a 32,000-token context window.
The newer Gemini 1.5 Pro is a midsized multimodal model that strikes an excellent balance between capability and efficiency, featuring an impressive 2 million-token context window. This version employs a Mixture of Experts (MoE) architecture, where the model is split into smaller specialized neural networks that selectively activate based on input type, resulting in faster performance and reduced computational costs. Gemini 1.5 Flash is a lightweight version created through knowledge distillation, where insights from Gemini 1.5 Pro were transferred to create a more compact and efficient model. Flash maintains a 1 million-token context window while offering lower latency, making it ideal for applications requiring speed and efficiency. The most recent Gemini 2.0 Flash, released in December 2024, is twice as fast as 1.5 Pro and includes new capabilities such as multimodal input and output, long context understanding, and native audio streaming applications.
| Model Version | Context Window | Best For | Key Features |
|---|---|---|---|
| Gemini 1.0 Nano | 32,000 tokens | Mobile on-device tasks | Lightweight, no internet required |
| Gemini 1.0 Ultra | 32,000 tokens | Complex reasoning & coding | Most powerful first-generation model |
| Gemini 1.5 Pro | 2 million tokens | Enterprise applications | Mixture of Experts architecture |
| Gemini 1.5 Flash | 1 million tokens | Speed-critical applications | Knowledge distilled, lower latency |
| Gemini 2.0 Flash | Extended context | Latest applications | 2x faster, multimodal streaming |
Gemini operates using a transformer model architecture, a neural network design that Google itself pioneered in 2017. The system works through three primary mechanisms: encoders transform input sequences into numerical representations called embeddings that capture semantic meaning and token position; a self-attention mechanism enables the model to focus on the most important tokens regardless of their position in the sequence; and decoders use this attention mechanism and encoder embeddings to generate the most statistically probable output sequence. Unlike traditional GPT models that process only text-based prompts, Gemini supports interleaved sequences of audio, images, text, and video as inputs and can produce interleaved text and image outputs.
The training process for Gemini involved massive multilingual and multimodal datasets spanning text, images, audio, and video. Google DeepMind applied advanced data filtering techniques to optimize training quality and ensure the model learns from diverse, high-quality information sources. During both training and inference phases, Gemini benefits from Google’s latest tensor processing unit chips, Trillium (the sixth generation of Google Cloud TPU), which provide improved performance, reduced latency, and lower costs compared to previous generations. These specialized processors are significantly more energy-efficient than earlier versions, making Gemini more sustainable and cost-effective to operate at scale.
Google has strategically integrated Gemini throughout its product suite, making AI assistance available in everyday tools. On Google Pixel phones, Gemini serves as the default AI assistant, replacing Google Assistant. Users can activate Gemini over any app, including Chrome, to ask questions about what’s on their screen, summarize webpages, or get more information about pictures. The Pixel 8 Pro was the first device engineered to run Gemini Nano, enabling on-device AI processing without cloud connectivity. In Google Search, Gemini powers AI Overviews, which provide detailed, contextually rich answers at the top of search results. These overviews break down complicated topics into bite-sized explanations, helping users understand complex subjects more quickly. Users aged 13 and older in the US can access AI Overviews, with availability expanding to users aged 18 and above in countries including the UK, India, Mexico, Brazil, Indonesia, and Japan.
Within Google Workspace, Gemini appears in the Docs side panel to help write and edit content, in Gmail to assist with drafting emails and suggesting responses, and in other applications like Google Maps to provide summaries of places and areas. Android developers can build with Gemini Nano through the Android operating system’s AICore system capability, enabling developers to create intelligent applications with on-device AI processing. Google Cloud’s Vertex AI service provides access to Gemini Pro for developers building custom applications, while Google AI Studio offers a web-based tool for prototyping and developing applications with Gemini.
Gemini offers flexible pricing options to accommodate different user needs and budgets. The free tier provides access to Gemini with the 1.5 Flash model featuring a 32,000-token context window, perfect for everyday users and those exploring AI capabilities. Users must be at least 13 years old (18 in Europe) and have a personal Google account to access the free version. Gemini Advanced costs $20 per month and provides access to the more powerful 1.5 Pro model with its 2 million-token context window, along with advanced features like Deep Research, image generation with Nano Banana Pro, and video creation capabilities. This subscription also includes 100 AI credit points monthly for video generation in Flow and Whisk.
For businesses, Google offers Gemini Business at $20 per user monthly (on annual plans) or $24 monthly (paid monthly), designed for small to medium-sized enterprises. Gemini Enterprise costs $30 per user monthly on annual plans with custom pricing available through Google’s sales team for larger deployments. Developers can access Gemini through the free API tier with limited usage, allowing them to test and prototype before committing to paid plans. The Google AI Pro subscription at $21.99 per month provides comprehensive access to Gemini 3 Pro, Deep Research, and video generation with Veo 3.1, while the Google AI Ultra tier at $274.99 per month offers maximum access to all features including Deep Think and Gemini Agent capabilities.
When comparing Gemini to ChatGPT, several key differences emerge that affect their suitability for different applications. Multimodal capabilities represent a significant distinction—Gemini was built as a multimodal model from the ground up, supporting text, images, audio, and video, while ChatGPT originally focused on text and later added image support with GPT-4. Context window length is another crucial differentiator, with Gemini 1.5 Pro supporting 2 million tokens compared to ChatGPT’s 128,000-token limit, enabling Gemini to process significantly more information in a single interaction. Developer availability differs substantially, as ChatGPT is available through OpenAI’s API and has been licensed to Microsoft for integration into Bing, while Gemini is primarily available through Google’s ecosystem and services.
In terms of performance benchmarks, Gemini Ultra surpasses ChatGPT in several areas including GSM8K for mathematical reasoning, HumanEval for code generation, and MMLU for natural language understanding, where Gemini Ultra even exceeded human expert performance. However, ChatGPT still performs better in the HellaSwag benchmark for common sense reasoning and natural language inference. Integration depth favors Gemini for Google ecosystem users, as it’s deeply integrated into Google Search, Workspace, and Pixel devices, while ChatGPT requires separate access through OpenAI’s platform or Microsoft’s Bing integration. Both platforms have similar concerns regarding hallucinations and bias, though both companies have implemented safety measures to mitigate these risks.
Gemini’s versatile capabilities enable numerous practical applications across different industries and use cases. In software development, Gemini can understand, explain, and generate code across popular programming languages including Python, Java, C++, and Go. Google’s AlphaCode 2 system uses a customized version of Gemini Pro to solve competitive programming problems involving theoretical computer science and complex mathematics. For content creation and analysis, Gemini can summarize lengthy documents, generate creative content, and analyze visual materials without external tools. The malware analysis capability allows security professionals to use Gemini 1.5 Pro to accurately determine whether files or code snippets are malicious and generate detailed reports, while Gemini Flash enables rapid, large-scale malware dissection.
Language translation leverages Gemini’s multilingual capabilities to translate between more than 100 languages with near-human accuracy. In education, Gemini assists students by breaking down complex topics, creating study materials, and providing personalized learning support through the Learning Coach Gem feature. Business intelligence applications benefit from Gemini’s ability to analyze charts, diagrams, and complex visuals to extract insights from business data. The Gems feature allows users to create customized AI experts on any topic, with premade options including a learning coach, brainstorming partner, and writing editor. Project Astra, Google’s universal AI agent initiative, builds on Gemini models to create agents that can process, remember, and understand multimodal information in real time, demonstrating potential for autonomous AI assistants.
Despite its advanced capabilities, Gemini faces several important limitations that users should understand. AI hallucinations remain a concern, where Gemini occasionally generates factually incorrect information and presents it as truthful. This issue has been particularly notable in AI Overviews search results, where the system has sometimes provided bizarre or inaccurate advice. Bias in training data can lead to skewed outputs if the training data excludes certain demographic groups or contains inherent biases. In February 2024, Google paused Gemini’s image generation capability after the system produced inaccurate portrayals of historical figures and demonstrated racial bias by showing Black and Asian Nazi soldiers, which Google later corrected.
Context understanding limitations mean that Gemini sometimes fails to fully grasp the nuance and context of complex prompts, resulting in responses that may not be entirely relevant to user queries. Originality and creativity constraints exist, particularly in the free version, which struggles with complicated multi-step prompts requiring nuanced reasoning. Intellectual property concerns have emerged, with Google facing regulatory fines in France for training Gemini on news stories and content without publisher knowledge or consent. Training data recency is another limitation, as Gemini’s knowledge has a cutoff date and may not include the most recent developments or events. Users should verify critical information from authoritative sources rather than relying solely on Gemini’s outputs, particularly for sensitive applications.
Google continues to advance Gemini’s capabilities with regular updates and new features. The release of Gemini 2.0 Flash in December 2024 demonstrated significant performance improvements, with the model running twice as fast as 1.5 Pro while maintaining quality. Gemini Live enables natural, hands-free conversations with the AI assistant, offering 10 voice options and the ability to pause and resume conversations seamlessly. The Deep Research feature allows users to search hundreds of websites, analyze findings, and generate comprehensive reports, functioning as a personalized research assistant. Canvas provides a collaborative workspace for writing and coding projects, while Gems enable users to create specialized AI experts tailored to specific tasks or domains.
Looking ahead, Google plans to expand Gemini’s availability globally, with the goal of reaching over a billion users by the end of 2025. The company is also developing more specialized versions of Gemini for specific industries and use cases, including enhanced capabilities for healthcare, finance, and scientific research. Integration with emerging technologies like augmented reality and advanced robotics is expected to create new possibilities for AI-assisted workflows. For businesses seeking to leverage AI automation at scale, platforms like FlowHunt provide enterprise-grade solutions to integrate Gemini and other AI models into automated workflows, enabling organizations to maximize the value of AI technology while maintaining control and security over their processes.
FlowHunt is the leading AI automation platform that helps you build, deploy, and manage intelligent workflows. Unlike other AI tools, FlowHunt provides enterprise-grade automation capabilities to integrate Gemini and other AI models into your business processes seamlessly.
Discover which company developed Bard AI chatbot. Learn about Google's Gemini LLM, its features, capabilities, and how it compares to ChatGPT in 2025.

Discover the key announcements from Google I/O 2025, including Gemini 2.5 Flash, Project Astra, Android XR, AI agents in Android Studio, Gemini Nano, Gemma 3n, ...

Gemini Flash 2.0 is setting new standards in AI with enhanced performance, speed, and multimodal capabilities. Explore its potential in real-world applications.