AI-ohjattu tiedonpoiminta automatisoi tietojen käsittelyn, vähentää virheitä ja käsittelee suuria tietomääriä tehokkaasti. Opi parhaista työkaluista, menetelmistä ja tulevaisuuden trendeistä.
AI
Data Extraction
Automation
OCR
Web Scraping
LLM Models
Business Intelligence
Parhaat LLM-mallit tiedonpoimintaan
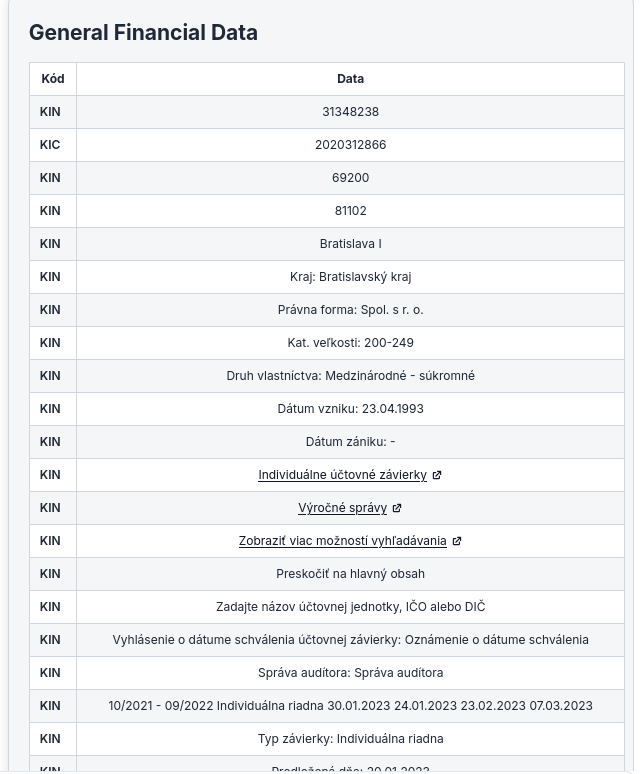
Nämä ovat mallit, joita olemme kokeilleet tiedon poimimiseksi HTML-verkkosivulta. Alla tarkastelemme useiden mallien suorituskykyä, kun niillä on pyritty poimimaan tiettyjä tietoja rakenteisiin muotoihin, kuten markdown-taulukoihin HTML-sivuista.
Tämä on se kehotus (prompt), jota käytimme arvioidessamme eri malleja: haimme rakenteetonta tietoa HTML:stä ja näytimme sen Markdown-taulukkona.
Llama 3.2 -malli
Tämä malli, vaikka onkin arkkitehtuuriltaan innovatiivinen, osoitti rajoituksia ohjeiden tarkassa noudattamisessa tiedonpoiminnassa. Tehtävässämme malli poimi kaiken datan eikä vain ohjeessa määriteltyjä tietoja.
Anthropic AI -mallit
Anthropic AI:n Haiku-malli erottui edukseen arvioinnissamme. Se osoitti vahvaa kykyä ymmärtää ohjeen tarkoitus ja toteuttaa poimintatehtävä erittäin tarkasti. Malli loisti HTML-sisällön jäsentämisessä ja poimitun tiedon muotoilussa hyvin rakenteisiin markdown-taulukoihin. Mallin kyky säilyttää konteksti ja noudattaa yksityiskohtaisia ohjeita teki siitä erityisen tehokkaan tässä käyttötapauksessa.
Vaikka Haiku-malli on Anthropicin pienin malli, se suoriutui arvioinnissa paremmin kuin mikään muu malli.
OpenAI-mallit
OpenAI-mallit ovat tunnettuja monipuolisuudestaan ja kielten ymmärryksestään, mutta ne eivät loistaneet tehtävässämme HTML:n muuttamisessa markdown-taulukoiksi. Suurin ongelma oli taulukoiden muotoilussa: malli tuotti ajoittain taulukoita, joiden sarakkeet olivat pielessä tai markdown-syntaksi oli epäjohdonmukaista, minkä takia tiedonpoiminnan jälkeen tarvittiin manuaalista muokkausta. OpenAI:n tuottamassa datassa oli myös paljon paikkamerkkejä.
Tiedonpoiminnan menetelmät
Tiedonpoimintamenetelmät ovat tärkeitä yrityksille, jotka haluavat hyödyntää dataansa mahdollisimman tehokkaasti. Menetelmät vaihtelevat monimutkaisuudeltaan ja sopivat eri tietotyypeille ja liiketoimintatarpeisiin.
Verkkokaavinta
Verkkokaavinta on suosittu tapa kerätä tietoa suoraan verkkosivustoilta. Siinä käytetään automaattisia työkaluja tai skriptejä suurten tietomäärien keräämiseksi verkkosivuilta. Menetelmä on erityisen hyödyllinen julkisesti saatavilla olevan tiedon, kuten hintojen, tuote-esittelyjen tai asiakasarvioiden keräämisessä. Työkalut kuten BeautifulSoup ja Cheerio ovat tunnettuja staattisten verkkosivujen sisällön kaapimisesta. Lisäksi AI-ohjatut kaapimet voivat automatisoida ja tehostaa prosessia, mikä säästää aikaa ja vaivaa.
Tekstin poiminta
Tekstin poiminta keskittyy tietyn tiedon etsimiseen lähteistä, joissa on paljon tekstiä. Tämä menetelmä on tärkeä dokumenttien, sähköpostien ja muiden tekstipainotteisten formaattien käsittelyssä. Kehittyneet tekstinpoimintatekniikat löytävät ja poimivat esimerkiksi nimiä, päivämääriä ja talouslukuja rakenteettomasta tekstistä. Usein prosessissa käytetään koneoppimismalleja, jotka tarkentuvat ja nopeutuvat ajan myötä.
API-työkalut
API-työkalut helpottavat tiedonpoimintaa tarjoamalla rakenteellisen tavan käyttää ulkoisia tietolähteitä. API:en kautta yritykset voivat hakea tietoja esimerkiksi sosiaalisen median palveluista, tietokannoista ja pilvisovelluksista turvallisesti ja tehokkaasti. Tämä lähestymistapa on täydellinen reaaliaikaisen datan integrointiin liiketoimintasovelluksiin, mikä mahdollistaa sujuvan tiedonkulun ja ajantasaiset tiedot.
Tiedonlouhinta
Tiedonlouhinnassa analysoidaan suuria tietomääriä, jotta löydetään kaavoja, yhteyksiä ja oivalluksia, joita ei muuten helposti havaita. Menetelmä on arvokas yrityksille, jotka haluavat optimoida prosessejaan, ennakoida trendejä tai ymmärtää asiakaskäyttäytymistä paremmin. Tiedonlouhintatekniikoita voidaan käyttää sekä rakenteelliseen että rakenteettomaan dataan, mikä tekee niistä monipuolisia työkaluja strategiseen päätöksentekoon.
OCR (Optinen merkkientunnistus)
OCR-teknologia muuntaa kirjoitetun tekstin, kuten käsinkirjoitetut muistiinpanot tai painetut dokumentit, muokattavaksi ja haettavaksi digitaaliseksi dataksi. Menetelmä on erityisen hyödyllinen paperipohjaisen tiedon digitalisoinnissa, mikä tehostaa dokumenttien hallintaa ja parantaa tiedon saatavuutta. OCR-moottorit ovat kehittyneet tarkemmiksi ja nopeammiksi fyysisten dokumenttien muuntamisessa digimuotoon.
Näiden tiedonpoimintamenetelmien lisääminen liiketoimintasuunnitelmaan voi merkittävästi parantaa datankäsittelykykyä, mikä johtaa parempaan päätöksentekoon ja tehokkaampiin prosesseihin. Valitsemalla oikean tai yhdistelmän menetelmiä yritykset voivat varmistaa, että ne hyödyntävät dataansa maksimaalisesti.
Parhaat tiedonpoimintatyökalut
Docsumo
Tietoa Docsumosta
Docsumo on dokumenttien käsittelyyn ja tiedonpoimintaan tarkoitettu työkalu, joka automatisoi tietojen syöttöprosessin poimimalla tietoa erilaisista dokumenteista. Älykkään OCR-teknologian ansiosta se vähentää merkittävästi manuaalisen tiedonsyötön tarvetta ja aikaa, tehden siitä arvokkaan työkalun useilla toimialoilla, kuten rahoituksessa, terveydenhuollossa ja vakuutusalalla.
Avainominaisuudet
Älykäs OCR-teknologia: Automatisoi tiedonpoiminnan erilaisista dokumenteista.
Human-in-the-Loop (HITL): Varmistaa tiedonpoiminnan tarkkuuden ihmisen valvonnalla epävarmoissa tapauksissa.
Laaja yhteensopivuus: Käsittelee erilaisia dokumenttityyppejä ja -formaatteja.
Integraatiomahdollisuudet: Voidaan yhdistää muihin ohjelmistoihin työnkulun tehostamiseksi.
Arvostelut
Plussat:
Helppokäyttöisyys: Intuitiivinen käyttöliittymä ja helppo dokumenttikartoitus.
Automaatio: Tehostaa tiedonpoimintaa ja vähentää manuaalista työtä.
Hinta-laatusuhde: Edullinen verrattuna muihin vaihtoehtoihin.
Asiakastuki: Nopea ja avulias tukitiimi.
Jatkuva kehitys: Säännölliset päivitykset ja ominaisuuksien parannukset.
Miinukset:
Oppimiskäyrä: Joillekin käyttäjille pieni oppimiskynnys.
Dokumenttirajoitteet: Voi olla haasteita monimutkaisten dokumenttien kanssa.
Toivottuja ominaisuuksia: Käyttäjät toivovat lisää räätälöintimahdollisuuksia.
Integraatiohaasteita: Joillakin vaikeuksia ohjelmistojen yhdistämisessä.
Rahoituslaitokset, jotka tarvitsevat tehokasta lainojen ja tilien käsittelyä.
Vakuutusyhtiöt, jotka haluavat virtaviivaistaa korvaus- ja sopimusprosessit.
Terveydenhuollon toimijat, jotka haluavat parantaa potilastietojen käsittelyä.
Logistiikkayritykset, jotka haluavat tehostaa toimitusten ja laskutuksen prosesseja.
Kiinteistöalan yritykset vuokrasopimusten ja hakemusten hallintaan.
Suositukset: Suosittelemme Docsumoa yrityksille, jotka käsittelevät suuria määriä dokumentteja ja tarvitsevat luotettavaa tiedonpoimintaa. Automaatio-ominaisuudet parantavat tehokkuutta ja tarkkuutta, mikä tekee siitä korvaamattoman työkalun monille aloille.
Hevo Data
Tietoa Hevo Datasta
Hevo Data on kattava dataintegraatioalusta, jonka avulla yritykset voivat yhdistää ja integroida tietoa useista lähteistä yhdeksi kokonaisuudeksi. Alusta on suunniteltu käyttäjäystävälliseksi, ja käyttäjät voivat luoda dataputkia ilman koodausosaamista. Tämä saavutettavuus tekee siitä ihanteellisen ratkaisun yrityksille, jotka haluavat hyödyntää dataansa analytiikkaan ja raportointiin. Hevo Data tukee monia tietolähteitä, kuten tietokantoja, pilvitallennusta ja SaaS-sovelluksia, mahdollistaen tietotyönkulkujen sujuvoittamisen ja päätöksenteon tehostamisen.
Avainominaisuudet
Kooditon dataintegraatio: Hevo Data mahdollistaa dataputkien luomisen ja hallinnan ilman koodausta, joten se sopii myös ei-teknisille käyttäjille.
Reaaliaikainen tiedon replikaatio: Alusta tarjoaa reaaliaikaisen tiedon replikaation, jolloin yrityksillä on aina ajantasaista tietoa analytiikkaan ja raportointiin.
Monipuoliset tietolähteet: Hevo Data tukee laajasti tietokantoja, pilvipalveluita ja erilaisia SaaS-sovelluksia, mahdollistaen saumattoman integraation.
Tiedon muunnos: Käyttäjät voivat muuntaa tietoa osana putkistoprosessia, jotta data sopii analyysiin.
Käyttäjäystävällinen käyttöliittymä: Intuitiivinen käyttöliittymä helpottaa putkien perustamista ja hallintaa.
Automaatiotoiminnot: Hevo Data mahdollistaa automaation tiedon työnkuluissa, mikä vähentää manuaalista työtä ja lisää tehokkuutta.
Vahvat tietoturvakäytännöt: Alusta käyttää vahvoja suojausprotokollia herkän tiedon suojaamiseksi siirron ja tallennuksen aikana.
Arvostelut
Hevo Data on saanut positiivista palautetta käytön helppoudesta, reaaliaikaisista ominaisuuksista ja kattavista integraatioista. Monet arvostavat kooditonta lähestymistapaa, jonka ansiosta tiimit voivat luoda dataputkia nopeasti ilman laajaa teknistä osaamista. Reaaliaikainen replikaatio on korostettu tärkeäksi eduksi yrityksille, jotka tarvitsevat ajantasaista tietoa päätöksentekoon. Osa käyttäjistä on kuitenkin maininnut, että edistyneempien ominaisuuksien opettelussa on hieman oppimiskäyrää.
Mielipiteemme
Hevo Dataa suositellaan erityisesti pienille ja keskisuurille yrityksille, jotka haluavat tehostaa dataintegraatioprosessejaan ilman suuria teknisiä resursseja. Se sopii erityisesti tiimeille, jotka tarvitsevat reaaliaikaista data-analytiikkaa ja raportointia. Yritykset esimerkiksi verkkokaupan, rahoituksen ja markkinoinnin aloilla hyötyvät merkittävästi Hevo Datan avulla tiedon yhdistämisestä päätöksenteon tueksi. Kaiken kaikkiaan Hevo Data on erinomainen valinta luotettavaa ja helppokäyttöistä dataintegraatiota etsiville organisaatioille.
Airbyte
Tietoa Airbytesta
Airbyte on avoimen lähdekoodin dataintegraatioalusta, joka auttaa yrityksiä synkronoimaan tietonsa eri järjestelmien välillä tehokkaasti. Se mahdollistaa ELT (Extract, Load, Transform) -dataputkien rakentamisen eri lähteiden ja kohteiden välille, jolloin tiedonsiirto ja raportointi sujuvat saumattomasti. Airbyte perustettiin tammikuussa 2020, ja sen tavoitteena on yksinkertaistaa dataintegraatiota tarjoamalla koodittoman työkalun, jonka avulla käyttäjät voivat yhdistää järjestelmiä ilman laajaa ohjelmointia. Yli 400 valmiin liittimen ansiosta Airbyte on noussut nopeasti suosioon ja saanut merkittäviä rahoituksia perustamisensa jälkeen.
Avainominaisuudet
Laaja liitinkirjasto: Yli 400 valmista liitintä, joiden avulla voidaan yhdistää lukuisiin tietolähteisiin ja kohteisiin.
Helppokäyttöinen käyttöliittymä: Yksinkertainen, kooditon käyttöönotto ja hallinta ei-teknisille käyttäjille.
Avoin lähdekoodi: Käyttäjät voivat muokata ja kehittää alustaa tarpeidensa mukaan.
Reaaliaikainen valvonta: Sisäänrakennetut työkalut putkien suorituskyvyn seuraamiseen ja ongelmien ilmoituksiin.
Mukautetut muunnokset: Yhteensopivuus dbt:n (data build tool) kanssa mahdollistaa muunnokset latauksen jälkeen.
Joustavat replikointivaihtoehdot: Tukee täydellistä päivitystä, inkrementaalista ja lokipohjaista muutostietojen keruuta (CDC).
Yhteisön tuki: Suuri ja aktiivinen yhteisö kehittää ja tukee alustaa.
Tietoturvaominaisuudet: Mukana OAuth ja kehittynyt tunnistautuminen eri lähteille.
Tulevat kehitykset: Tavoitteena laajentaa ominaisuuksia ja liittimiä, 500 korkealaatuista liitintä vuoteen 2024 mennessä.
Arvostelut
Positiivista palautetta: Käyttäjät arvostavat helppokäyttöisyyttä, laajoja integraatioita, avoimen lähdekoodin luonnetta ja asiakastukea. Monien mielestä alusta on käyttäjäystävällinen ja mahdollistaa nopean dataputkien perustamisen.
Kritiikkiä: Jotkut käyttäjät ovat kokeneet suorituskykyongelmia suurten tietomäärien kanssa ja toivovat parempaa dokumentaatiota. Osa kokee, että edistyneet ominaisuudet ovat vielä rajallisia.
Mielipiteemme
Airbyte sopii erityisesti:
Startupeille ja pk-yrityksille: Edullisuus ja helppo integrointi sopivat rajallisia resursseja omaaville.
Dataohjatuille markkinointitiimeille: Reaaliaikainen data tehostaa markkinointistrategioita.
Data-insinööreille ja analyytikoille: Tarjoaa joustavuutta ja räätälöitävyyttä ammattilaisille.
Yrityksille, jotka rakentavat markkinointidatavarastoja: Yhdistää tehokkaasti eri lähteiden dataa.
Organisaatioille, jotka keskittyvät asiakastiedon integrointiin: Yksinkertaistaa kattavan asiakasnäkymän luomista.
Yhteenvetona Airbyte tarjoaa vahvan ratkaisun monille käyttäjille, jotka haluavat tehostaa dataintegraatioprosessejaan. Sen avoin lähdekoodi, laajat ominaisuudet ja yhteisön tuki tekevät siitä houkuttelevan valinnan yrityksille, jotka haluavat hyödyntää dataansa tehokkaasti.
Import.io
Tietoa Import.iosta
Import.io on verkkotiedon integrointialusta, jonka avulla käyttäjät voivat poimia, muuntaa ja ladata tietoja verkosta käyttökelpoiseen muotoon. Tuote on suunniteltu auttamaan yrityksiä keräämään tietoa erilaisista verkkolähteistä analysointia ja päätöksentekoa varten. Import.io tarjoaa SaaS-ratkaisun, joka muuntaa monimutkaisen verkkodatan rakenteisiin muotoihin, kuten JSON, CSV tai Google Sheets. Tämä on tärkeää yrityksille, jotka tarvitsevat dataa kilpailija-analyysiin, markkinatutkimukseen ja strategiseen suunnitteluun. Alusta on rakennettu ratkaisemaan verkkodatan poiminnan haasteita, kuten CAPTCHA-tunnistukset, kirjautumiset ja vaihtelevat verkkorakenteet.
Avainominaisuudet
Moni-URL-koulutus: Kouluta sama poimija useille eri rakenteisille sivuille.
Automaattinen optimointi: Optimoi poimijat toimimaan tehokkaasti automaattisesti.
URL-generointi: Luo tarvittavat URL-osoitteet kaavoilla, kuten sivunumeroilla ja kategorianimillä.
Monisivuinen poiminta: Poimi tietoa useilta sivuilta, automaattisella sivutuksen tunnistuksella.
Verkkosivujen kuvakaappaukset: Ota ja tallenna kuvakaappaukset kaikista sivuista, joilta tietoa poimitaan.
Autentikoitu poiminta: Poimi tietoa kirjautumisen taakse jääviltä sivuilta käyttäjätunnuksilla.
Kuvien ja tiedostojen lataus: Poimi kuvat ja dokumentit verkkodatan lisäksi.
Helppo ajastus: Ajasta säännölliset tiedonpoimintatehtävät.
“Ensinnäkin erittäin helppokäyttöinen. Työkalu mahdollistaa räätälöidyn datan generoinnin verkkokaavinnalla.”
“Import.io on hyvä, melko yksinkertainen API-luontityökalu. Käyttöliittymä ei ehkä ole kaunein, mutta helppo navigoida.”
Negatiiviset arviot:
“Surkea asiakaspalvelu… Tililtäni veloitettiin yli 1000 $ liikaa.”
“Heidän palauttamansa data on hirveää sekasotkua… Olemme havainneet lukemattomia virheitä.”
“Myyjä lupasi liikoja, työkalu ei täyttänyt odotuksia.”
Mielipiteemme
Import.io on erinomainen valinta markkinointitiimeille, verkkokaupoille, data-analyytikoille ja tutkijoille, jotka haluavat tehostaa tiedonkeruutaan ilman laajaa teknistä osaamista. Sen käyttäjäystävällinen käyttöliittymä ja monipuoliset ominaisuudet soveltuvat laajasti kilpailija-analyysiin, markkinatutkimukseen ja sosiaalisen median seurantaan. Import.io erottuu kyvyllään tarjota helposti lähestyttävää ja toimivaa verkkodataa, samalla kun se säästää aikaa ja vähentää operatiivisia kustannuksia.
Tämä kattava raportti antaa potentiaalisille käyttäjille kaikki tarvittavat tiedot Import.ion arviointiin verkkodatan poimintaratkaisuna.
Tiedonpoiminnan tulevaisuuden trendit
Tulevaisuudessa tiedonpoiminta tulee muuttumaan merkittävästi uusien trendien myötä. Tekoälyä hyödyntävät mallit johtavat kehitystä, tuoden lisää tarkkuutta ja tehokkuutta koneoppimisen avulla. Lisäksi edge-analytiikka mahdollistaa tiedon käsittelyn siellä, missä se syntyy, mikä vähentää viivettä ja siirrettävän tiedon määrää. Toinen iso trendi on tiedon saavutettavuuden parantaminen, jossa AI auttaa murtamaan esteitä ja mahdollistaa yhä useammalle organisaation jäsenelle pääsyn tärkeisiin oivalluksiin. Lisäksi painopiste siirtyy kohti eettisiä ja tietosuojaa kunnioittavia tiedonkeruun käytäntöjä. Näiden trendien kehittyessä ajan tasalla pysyminen ja joustavuus ovat avainasemassa, jotta tiedonpoiminnasta saadaan strategista kilpailuetua.
Usein kysytyt kysymykset
Mitkä ovat AI-ohjatun tiedonpoiminnan tärkeimmät hyödyt?
AI-ohjattu tiedonpoiminta lisää tehokkuutta automatisoimalla tietojen käsittelyn, vähentää manuaalisia virheitä ja pystyy käsittelemään suuria tietomääriä, jolloin yritykset voivat kohdistaa resurssejaan strategisempiin tehtäviin.
Mitkä ovat parhaat mallit AI-tiedonpoimintaan?
Johtavia malleja ovat muun muassa Anthropic AI:n Haiku, joka on erityisen hyvä HTML:stä rakenteellisen tiedon poiminnassa, sekä OpenAI:n ja Llama 3.2:n mallit – tosin Anthropicin malli noudatti parhaiten rakenteelliseen poimintaan liittyviä ohjeita.
Mitkä ovat yleisimmät tiedonpoimintamenetelmät?
Yleisiä menetelmiä ovat verkkokaavinta, tekstin poiminta, API-integraatio, tiedonlouhinta ja OCR (Optinen merkkientunnistus), joista kukin soveltuu eri tietotyypeille ja liiketoiminnan tarpeisiin.
Mitä työkaluja suositellaan AI-ohjattuun tiedonpoimintaan?
Parhaita työkaluja ovat Docsumo dokumenttien käsittelyyn ja OCR:ään, Hevo Data ja Airbyte koodittomaan dataintegraatioon sekä Import.io verkkotiedon poimintaan ja muuntamiseen.
Mitkä tulevaisuuden trendit muovaavat AI-tiedonpoimintaa?
Keskeisiä trendejä ovat tekoälyn ja koneoppimisen lisääntyvä käyttö tarkkuuden parantamiseksi, edge-analytiikka nopeampaan käsittelyyn, parempi tiedon saavutettavuus organisaatioissa sekä eettisiin ja tietosuojaan liittyviin käytäntöihin panostaminen.
Valmis rakentamaan oman tekoälysi?
Älykkäät chatbotit ja AI-työkalut saman katon alla. Yhdistä intuitiivisia lohkoja ja muuta ideasi automatisoiduiksi Flows-ratkaisuiksi.
Tekstintuotanto suurilla kielimalleilla (LLM) tarkoittaa koneoppimismallien kehittynyttä käyttöä ihmismäisen tekstin tuottamiseen annetuista kehotteista. Tutust...
Tutustu suurten kielimallien (LLM) kuten GPT-3:n ja GPT-4:n koulutus- ja käyttökustannuksiin, mukaan lukien laskenta-, energia- ja laitteistokulut, sekä selvitä...
5 min lukuaika
LLM
AI
+4
Evästeiden Suostumus Käytämme evästeitä parantaaksemme selauskokemustasi ja analysoidaksemme liikennettämme. See our privacy policy.