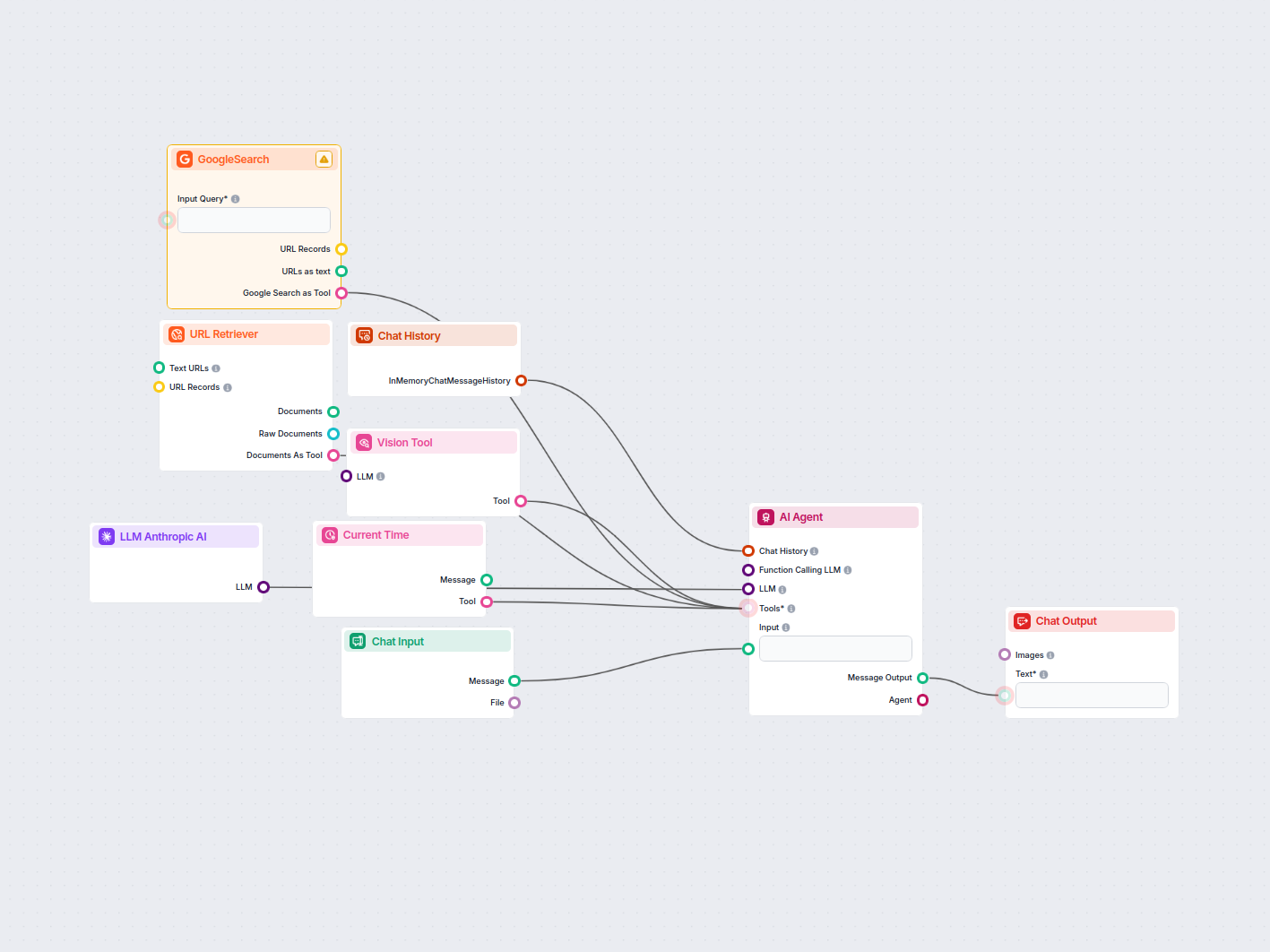
LinkedIn-mainoskilpailija-analysoija
Tämä työnkulku automatisoi LinkedIn-mainosten markkinatutkimuksen tunnistamalla avainsanan tärkeimmät kilpailijat, analysoimalla heidän mainostekstinsä ja visua...
3 min lukuaika
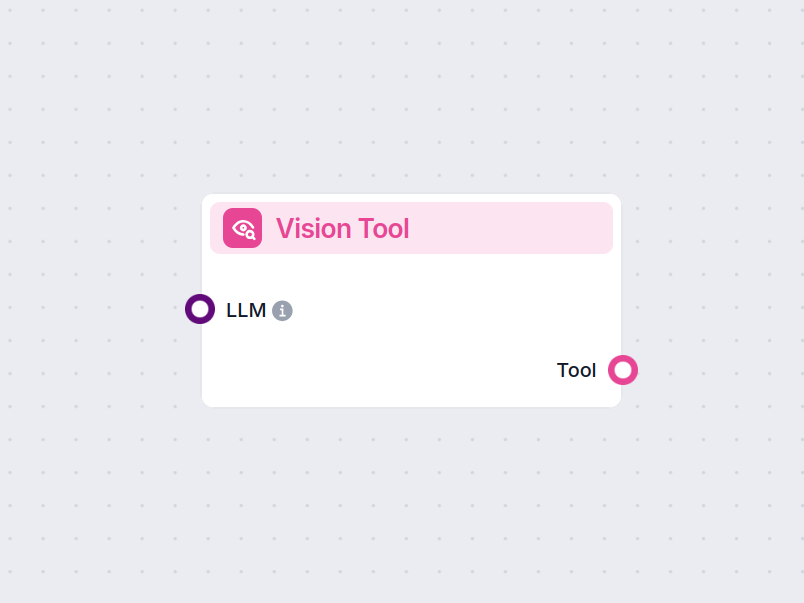
Vision-työkalun avulla tekoäly analysoi kuvia, poimii arvokkaita havaintoja ja vastaa kysymyksiin visuaalisen sisällön pohjalta työnkuluissasi.
Komponentin kuvaus
Vision-työkalu on komponentti, jonka avulla AI-työnkulut voivat käsitellä ja analysoida liitettyjä kuvia. Se antaa tekoälyagenteille mahdollisuuden “nähdä” kuvia, poimia niistä merkityksellistä tietoa ja vastata kysymyksiin visuaalisesta sisällöstä. Tämä tekee siitä erityisen arvokkaan tilanteissa, joissa kuvien ymmärtäminen tai tulkinta on olennaista, kuten asiakirjojen käsittelyssä, visuaalisessa laadunvarmistuksessa, sisällön moderoinnissa tai multimedia-analyysissä.
| Syötteen nimi | Tyyppi | Kuvaus | Pakollinen | Edistynyt |
|---|---|---|---|---|
| LLM (malli) | BaseChatModel | Kielen mallia käytetään tekstivastausten tuottamiseen kuvan analyysin perusteella. | Ei | Ei |
| Työkalun kuvaus | String (multi) | Kuvaus, joka auttaa agenttia ymmärtämään, miten työkalua käytetään. | Ei | Kyllä |
| Työkalun nimi | String | Tämän työkalun viitenimi agentin työnkuluissa. | Ei | Kyllä |
| Yksityiskohtainen | Boolean | Vaihtoehto yksityiskohtaisen (verbose) tulostuksen aktivoimiseksi vianmääritystä tai läpinäkyvyyttä varten. | Ei | Kyllä |
| Ulostulon nimi | Tyyppi | Kuvaus |
|---|---|---|
| Työkalu | Työkalu | Konfiguroitu Vision-työkalun instanssi integrointia varten |
Vision-työkalu tuottaa Työkalu-instanssin, jota tekoälyagentit voivat käyttää kuvien käsittelyyn ja niihin liittyvien vastausten tuottamiseen.
Vision-työkalun integrointi tekoälyprosesseihin mahdollistaa visuaalisen datan hyödyntämisen, ei pelkästään tekstin. Se yhdistää kielen ja kuvan ymmärryksen, avaten mahdollisuuksia monipuolisempiin, vuorovaikutteisempiin ja älykkäämpiin sovelluksiin.
Hyödyt tiivistettynä:
Käyttämällä Vision-työkalua saat työnkuluistasi entistä monipuolisempia ja kyvykkäämpiä, mahdollistaen uuden sukupolven sovellukset, jotka hyödyntävät sekä teksti- että kuvaymmärrystä.
Auttaaksemme sinua pääsemään nopeasti alkuun, olemme valmistaneet useita esimerkkiflow-malleja, jotka osoittavat, kuinka käyttää Vision-työkalu-komponenttia tehokkaasti. Nämä mallit esittelevät erilaisia käyttötapauksia ja parhaita käytäntöjä, helpottaen sinun ymmärtämistäsi ja komponentin toteuttamista omissa projekteissasi.
Tämä työnkulku automatisoi LinkedIn-mainosten markkinatutkimuksen tunnistamalla avainsanan tärkeimmät kilpailijat, analysoimalla heidän mainostekstinsä ja visua...
Vision-työkalun avulla työnkulkusi voi käsitellä kuvia, poimia niistä olennaista tietoa ja vastata kysymyksiin kuvan sisällöstä tekoälyn avulla.
Kyllä, Vision-työkalu on suunniteltu tulkitsemaan kuvia työnkulun kontekstissa, jolloin tekoälyagentit voivat yhdistää visuaalista ja tekstuaalista tietoa älykkäämpää automaatiota varten.
Tyypillisiä käyttötapauksia ovat asiakirjojen käsittely, automaattinen visuaalinen tarkastus, tiedon poiminta kuvista ja chatbot-keskustelujen tehostaminen kuvaymmärryksellä.
Ehdottomasti. Vision-työkalu on FlowHuntin plug-and-play-komponentti, joka voidaan helposti yhdistää muihin kuvan analyysiä vaativiin työnkulun osiin.
Voit valita tai määrittää tekoälymallin, mutta FlowHunt tarjoaa järkevät oletusasetukset nopeaa käyttöönottoa ja kokeilua varten.
Tehosta työnkulkujasi tekoälypohjaisella kuvien ymmärtämisellä—kokeile Vision-työkalua FlowHuntissa jo tänään.
Tutustu GPT 4 Vision Preview -tekoälyagentin edistyneisiin kykyihin. Tämä syväsukellus paljastaa, miten se menee tekstin tuottamista pidemmälle ja esittelee sen...
Luo luovia kuvatekstejä vaivattomasti tekoälyn avulla. Lataa kuva ja saat heti iskevän kuvatekstin – täydellinen sosiaaliseen mediaan tai luoviin projekteihin....
Tämä työnkulku ottaa vastaan käyttäjän lähettämät kuvagenerointipromptit ja parantaa niitä tekoälyn parhaiden käytäntöjen avulla. Näin promptit ovat yksityiskoh...