Kuinka testata tekoälychatbottia
Opi kattavat tekoälychatbottien testausstrategiat, mukaan lukien toiminnallinen, suorituskyky-, tietoturva- ja käytettävyystestaus. Löydä parhaat käytännöt, työ...
9 min lukuaika
Opi kattavat menetelmät AI-helpdesk-chatbotin tarkkuuden mittaamiseen vuonna 2025. Tutustu precision-, recall-, F1-pisteisiin, käyttäjätyytyväisyysmittareihin ja kehittyneisiin arviointitekniikoihin FlowHuntin avulla.
Mittaa AI-helpdesk-chatbotin tarkkuutta useilla mittareilla, kuten precision- ja recall-laskelmilla, sekaannusmatriiseilla, käyttäjätyytyväisyyspisteillä, ratkaisuprosenteilla ja kehittyneillä LLM-pohjaisilla arviointimenetelmillä. FlowHunt tarjoaa kattavat työkalut automaattiseen tarkkuuden arviointiin ja suorituskyvyn seurantaan.
AI-helpdesk-chatbotin tarkkuuden mittaaminen on olennaista, jotta se pystyy tarjoamaan luotettavia ja hyödyllisiä vastauksia asiakaskyselyihin. Toisin kuin yksinkertaisissa luokittelutehtävissä, chatbotin tarkkuus kattaa useita ulottuvuuksia, jotka on arvioitava yhdessä, jotta saadaan kattava kuva suorituskyvystä. Prosessiin kuuluu analyysi siitä, kuinka hyvin chatbot ymmärtää käyttäjän kyselyt, antaa oikeaa tietoa, ratkaisee ongelmia tehokkaasti ja ylläpitää käyttäjätyytyväisyyttä vuorovaikutuksen aikana. Kattava tarkkuuden mittausstrategia yhdistää määrälliset mittarit laadulliseen palautteeseen vahvuuksien ja kehityskohteiden tunnistamiseksi.
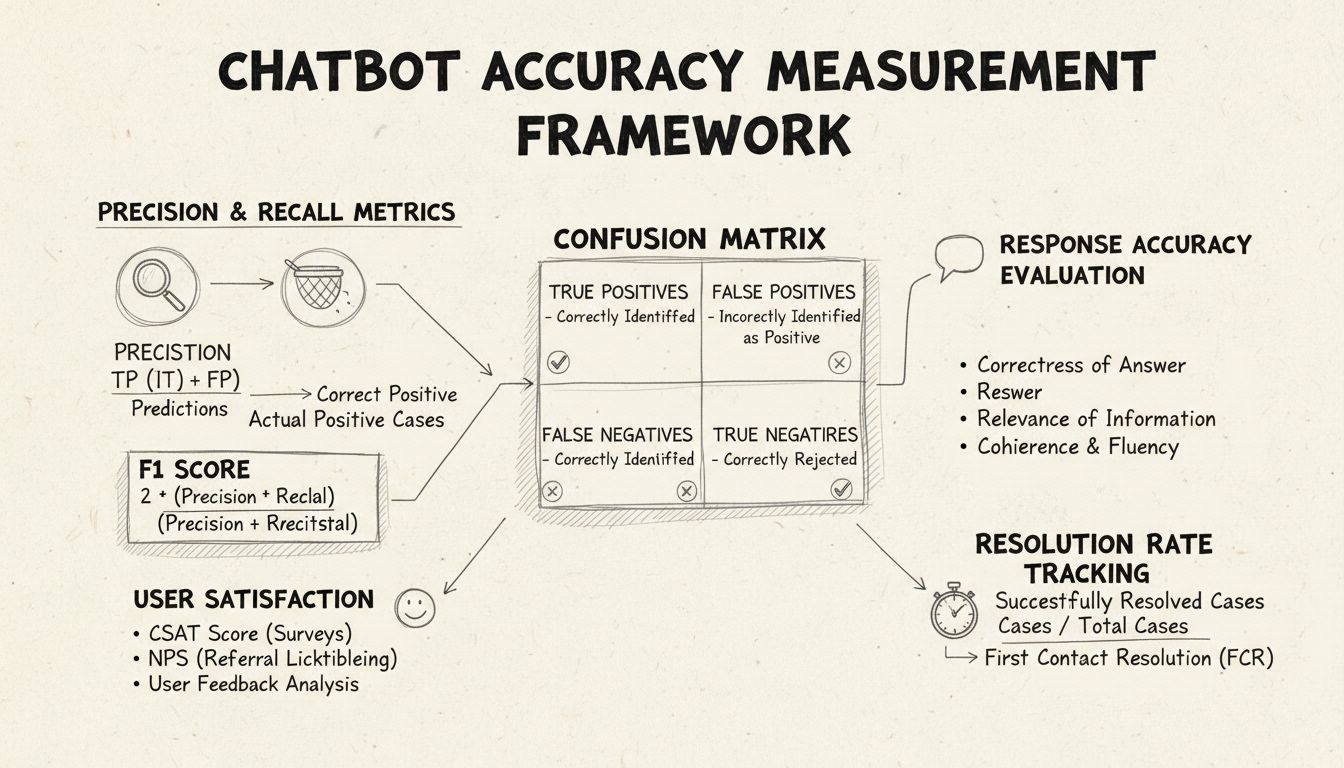
Precision ja recall ovat perusmittareita, jotka johdetaan sekaannusmatriisista ja mittaavat chatbotin suorituskyvyn eri osa-alueita. Precision tarkoittaa oikeiden vastausten osuutta kaikista chatbotin antamista vastauksista, ja se lasketaan kaavalla: Precision = True Positives / (True Positives + False Positives). Tämä mittari vastaa kysymykseen: “Kuinka usein chatbotin antama vastaus on oikea?” Korkea precision-arvo osoittaa, että chatbot harvoin antaa virheellistä tietoa, mikä on ratkaisevaa käyttäjän luottamuksen ylläpitämiseksi helpdesk-tilanteissa.
Recall, eli herkkyys, mittaa oikeiden vastausten osuutta kaikista niistä oikeista vastauksista, jotka chatbotin olisi pitänyt antaa, kaavalla: Recall = True Positives / (True Positives + False Negatives). Tämä mittari kertoo, tunnistaako ja vastaako chatbot onnistuneesti kaikkiin asiakkaan todellisiin ongelmiin. Helpdeskissä korkea recall takaa, että asiakkaat saavat apua ongelmiinsa eivätkä saa turhaan vastausta, ettei chatbot osaa auttaa. Precisionin ja recallin välillä on luontainen kompromissi: toisen optimointi usein vähentää toista, joten tasapainottaminen riippuu liiketoimintasi painopisteistä.
F1-piste tarjoaa yksittäisen mittarin, joka tasapainottaa precisionin ja recallin, ja se lasketaan harmonisena keskiarvona: F1 = 2 × (Precision × Recall) / (Precision + Recall). Tämä mittari on erityisen hyödyllinen, kun tarvitset yhtenäisen suorituskyvyn mittarin tai kun käsittelet epätasapainoisia aineistoja, joissa yksi luokka dominoi muita. Esimerkiksi, jos chatbot käsittelee 1 000 rutiinikyselyä mutta vain 50 monimutkaista eskalaatiota, F1-piste estää mittaria vääristymästä enemmistöluokan suuntaan. F1-piste vaihtelee välillä 0–1, ja arvo 1 tarkoittaa täydellistä precisionia ja recallia, mikä tekee siitä intuitiivisen tavan ymmärtää chatbotin kokonaisvaltaista suorituskykyä.
Sekaannusmatriisi on perustyökalu, joka jakaa chatbotin suorituskyvyn neljään luokkaan: True Positives (oikeat vastaukset oikeisiin kyselyihin), True Negatives (oikein jätetyt vastaamatta rajattomiin kysymyksiin), False Positives (virheelliset vastaukset) ja False Negatives (missatut mahdollisuudet auttaa). Tämä matriisi paljastaa erityisiä epäonnistumismalleja, joita voidaan parantaa kohdennetusti. Esimerkiksi, jos matriisista ilmenee paljon vääriä negatiiveja laskutuskyselyissä, voidaan päätellä, että chatbotin koulutusaineistosta puuttuu riittävästi laskutusaiheista esimerkkejä ja se kaipaa vahvistusta kyseisellä alueella.
| Mittari | Määritelmä | Laskentatapa | Liiketoiminnallinen vaikutus |
|---|---|---|---|
| True Positives (TP) | Oikeat vastaukset oikeisiin kyselyihin | Lasketaan suoraan | Rakentaa asiakasluottamusta |
| True Negatives (TN) | Oikein kieltäytyminen rajatuista kysymyksistä | Lasketaan suoraan | Estää väärän tiedon jakamisen |
| False Positives (FP) | Virheelliset annetut vastaukset | Lasketaan suoraan | Heikentää uskottavuutta |
| False Negatives (FN) | Missatut mahdollisuudet auttaa | Lasketaan suoraan | Vähentää tyytyväisyyttä |
| Precision | Positiivisten ennusteiden laatu | TP / (TP + FP) | Luotettavuusmittari |
| Recall | Todellisten positiivisten kattavuus | TP / (TP + FN) | Kattavuusmittari |
| Accuracy | Kokonaiskorrektius | (TP + TN) / Yhteensä | Yleissuorituskyky |
Vastausten tarkkuus mittaa, kuinka usein chatbot antaa tosiasiallisesti oikeaa tietoa, joka suoraan vastaa käyttäjän kysymykseen. Tämä menee yksinkertaista kaavojen sovitusta pidemmälle ja arvioi, onko sisältö tarkkaa, ajantasaista ja tilanteeseen sopivaa. Manuaalisessa arvioinnissa ihmisarvioijat tarkistavat satunnaisotannan keskusteluista ja vertaavat chatbotin vastauksia ennalta määriteltyyn tietokantaan oikeista vastauksista. Automaattiset vertailumenetelmät voidaan toteuttaa NLP-tekniikoilla vertaamalla vastauksia järjestelmään tallennettuihin odotettuihin vastauksiin, mutta nämä vaativat tarkkaa kalibrointia, jotta oikeat vastaukset eri sanamuodoilla eivät tuota vääriä negatiiveja.
Vastausten relevanssi arvioi, vastaako chatbotin vastaus oikeasti käyttäjän kysymykseen, vaikka vastaus ei olisi täysin oikea. Tämä mittari kattaa tilanteet, joissa chatbot antaa hyödyllistä tietoa, joka ei ole tarkka vastaus mutta vie keskustelua kohti ratkaisua. NLP-pohjaiset menetelmät, kuten kosinietäisyys, voivat mitata semanttista samankaltaisuutta käyttäjän kysymyksen ja chatbotin vastauksen välillä ja tuottaa automaattisen relevanssipisteen. Käyttäjäpalautemekanismit, kuten peukku ylös/alas -arvostelut jokaisen vuorovaikutuksen jälkeen, tarjoavat suoran relevanssiarvion tärkeimmiltä henkilöiltä – asiakkailtasi. Näitä palautteita tulee kerätä ja analysoida jatkuvasti, jotta voidaan tunnistaa, minkälaisiin kysymyksiin chatbot suoriutuu hyvin tai huonosti.
Asiakastyytyväisyyspiste (CSAT) mittaa käyttäjätyytyväisyyttä chatbotin kanssa käytyihin vuorovaikutuksiin suorien kyselyiden avulla, yleensä 1–5-asteikolla tai yksinkertaisilla tyytyväisyysarvioilla. Jokaisen vuorovaikutuksen jälkeen käyttäjiä pyydetään arvioimaan tyytyväisyytensä, mikä tarjoaa välitöntä palautetta siitä, täyttikö chatbot heidän tarpeensa. CSAT-pisteet yli 80 % viittaavat vahvaan suoritukseen, kun taas alle 60 % kertovat merkittävistä ongelmista, jotka vaativat tutkimista. CSATin etu on sen yksinkertaisuus ja suoruus – käyttäjät ilmaisevat selkeästi tyytyväisyytensä – mutta siihen voivat vaikuttaa muutkin tekijät kuin chatbotin tarkkuus, kuten asian monimutkaisuus tai käyttäjän odotukset.
Net Promoter Score mittaa käyttäjien halukkuutta suositella chatbotia muille, ja se lasketaan kysymällä “Kuinka todennäköisesti suosittelisit tätä chatbotia kollegallesi?” asteikolla 0–10. Vastaajat, jotka antavat 9–10, ovat promoottoreita, 7–8 passiivisia ja 0–6 kriitikoita. NPS = (Promoottorit – Kriitikot) / Vastaajien kokonaismäärä × 100. Tämä mittari korreloi vahvasti pitkäaikaisen asiakasuskollisuuden kanssa ja tarjoaa näkymän siihen, luoko chatbot positiivisia kokemuksia, joita käyttäjät haluavat jakaa. NPS yli 50:tä pidetään erinomaisena, kun taas negatiivinen NPS ilmaisee vakavia suoritusongelmia.
Tunnereaktioanalyysi tarkastelee käyttäjäviestien tunnepitoisuutta ennen ja jälkeen chatbotin kanssa käydyn vuorovaikutuksen mittaamaan tyytyväisyyttä. Kehittyneet NLP-menetelmät luokittelevat viestit positiivisiksi, neutraaleiksi tai negatiivisiksi ja paljastavat, ovatko käyttäjät tyytyväisempiä vai turhautuneempia keskustelun jälkeen. Positiivinen tunne-ero osoittaa chatbotin onnistuneen ratkaisemaan huolia, kun taas negatiivinen kertoo mahdollisista epäonnistumisista. Tämä mittari tavoittaa tunnepitoisia ulottuvuuksia, joita perinteiset tarkkuusmittarit eivät huomioi, tarjoten arvokasta tietoa käyttäjäkokemuksen laadusta.
Ensikontaktin ratkaisuprosentti mittaa niiden asiakasongelmien osuutta, jotka chatbot ratkaisee ilman eskalointia ihmisedustajalle. Tämä mittari vaikuttaa suoraan toiminnan tehokkuuteen ja asiakastyytyväisyyteen, sillä asiakkaat haluavat ratkaisun heti ilman siirtoa eteenpäin. FCR yli 70 % indikoi vahvaa suorituskykyä, kun taas alle 50 % viittaa siihen, ettei chatbotilla ole riittävästi tietoa tai kykyä ratkaista yleisimpiä kysymyksiä. Kun FCR jaotellaan ongelmakategorioittain, voidaan nähdä, mitkä ongelmat chatbot ratkaisee hyvin ja mitkä vaativat ihmistukea – tämä ohjaa koulutusta ja tietopohjan kehittämistä.
Eskalointiprosentti mittaa, kuinka usein chatbot siirtää keskustelut ihmisedustajille, kun taas fallback-taajuus kertoo, kuinka usein chatbot antaa yleisiä vastauksia, kuten “En ymmärrä” tai “Voisitko muotoilla kysymyksesi uudelleen”. Korkea eskalointiprosentti (yli 30 %) osoittaa, että chatbotilta puuttuu tietoa tai varmuutta monissa tilanteissa, kun taas korkea fallback-taajuus viittaa heikkoon intentiotunnistukseen tai riittämättömään koulutusaineistoon. Näillä mittareilla tunnistetaan chatbotin kyvykkyyksien aukkoja, joita voidaan paikata laajentamalla tietopohjaa, kouluttamalla mallia uudelleen tai kehittämällä luonnollisen kielen ymmärrystä.
Vasteaika mittaa, kuinka nopeasti chatbot vastaa käyttäjän viesteihin – tavallisesti millisekunneissa tai sekunneissa. Käyttäjät odottavat lähes välittömiä vastauksia; yli 3–5 sekunnin viiveet heikentävät tyytyväisyyttä merkittävästi. Käsittelyaika mittaa koko ajan siitä, kun käyttäjä aloittaa yhteydenoton siihen asti, kunnes ongelma on ratkaistu tai eskaloitu, tarjoten näkymän chatbotin tehokkuuteen. Lyhyemmät käsittelyajat osoittavat chatbotin ymmärtävän ja ratkaisevan ongelmat nopeasti, kun taas pidemmät ajat viittaavat useisiin tarkennuskierroksiin tai monimutkaisiin kysymyksiin. Mittareita kannattaa seurata eri ongelmakategorioissa erikseen, sillä monimutkaiset tekniset ongelmat vaativat luonnostaan pidemmän käsittelyajan kuin yksinkertaiset FAQ-kysymykset.
LLM Arvostelijana on kehittynyt arviointitapa, jossa suuri kielimalli arvioi toisen AI-järjestelmän tuotoksia. Tämä menetelmä on erityisen tehokas arvioitaessa chatbotin vastauksia useiden laatukriteerien perusteella, kuten tarkkuus, relevanssi, johdonmukaisuus, sujuvuus, turvallisuus, kattavuus ja sävy. Tutkimukset osoittavat, että LLM-arvioijat voivat saavuttaa jopa 85 %:n yhteneväisyyden ihmisarvioiden kanssa, tehden siitä skaalautuvan vaihtoehdon manuaaliselle arvioinnille. Menetelmä sisältää tarkkojen arviointikriteerien määrittelyn, yksityiskohtaisten arvostelijapromptien laadinnan esimerkein, sekä sekä alkuperäisen käyttäjäkysymyksen että chatbotin vastauksen antamisen arvostelijalle, jolloin saadaan rakenteellisia pisteitä tai yksityiskohtaista palautetta.
LLM Arvostelijana -prosessissa käytetään tavallisesti kahta arviointitapaa: yksittäisen vastauksen arviointi, jossa arvostelija pisteyttää yksittäisen vastauksen joko ilman viitettä (referenceless) tai vertailevasti (odotettuun vastaukseen verraten), sekä parivertailu, jossa arvostelija vertailee kahta vastausta ja valitsee paremman. Tämä joustavuus mahdollistaa sekä absoluuttisen suorituskyvyn että suhteellisten parannusten arvioinnin esimerkiksi eri chatbot-versioita testattaessa. FlowHuntin alusta tukee LLM Arvostelijana -menetelmän käyttöönottoa visuaalisella käyttöliittymällä, integraatioilla johtaviin kielimalleihin kuten ChatGPT ja Claude, sekä CLI-työkaluilla raportointiin ja automaattisiin arviointeihin.
Perustarkkuuden laskennan lisäksi yksityiskohtainen sekaannusmatriisianalyysi paljastaa chatbotin epäonnistumisten erityisiä malleja. Tarkastelemalla, millaiset kyselyt tuottavat vääriä positiivisia tai negatiivisia, voidaan tunnistaa järjestelmällisiä heikkouksia. Esimerkiksi, jos matriisista näkyy, että chatbot luokittelee usein laskutuskysymykset tekniseksi tuen kysymyksiksi, kyseessä on koulutusaineiston epätasapaino tai intentiotunnistusongelma laskutusaiheessa. Luomalla erilliset sekaannusmatriisit eri kysymyskategorioille, voidaan tehdä kohdennettuja parannuksia yleisen mallin uudelleenkoulutuksen sijaan.
A/B-testaus vertailee chatbotin eri versioita selvittääkseen, mikä niistä suoriutuu paremmin keskeisissä mittareissa. Tämä voi tarkoittaa erilaisten vastausmallien, tietopohjakokoonpanojen tai taustalla olevan kielimallin testaamista. Jakamalla osa liikenteestä satunnaisesti kullekin versiolle ja vertailemalla esimerkiksi FCR-prosenttia, CSAT-pisteitä ja vastausten tarkkuutta, voidaan tehdä tietoon perustuvia päätöksiä parannusten käyttöönotosta. A/B-testauksen tulee olla riittävän pitkäkestoinen, jotta se kattaa käyttäjäkyselyiden luontaisen vaihtelun ja tulosten tilastollisen merkitsevyyden.
FlowHunt tarjoaa integroidun alustan AI-helpdesk-chatbotien rakentamiseen, käyttöönottoon ja arviointiin kehittyneillä tarkkuuden mittausominaisuuksilla. Alustan visuaalinen rakentaja mahdollistaa teknisesti vähemmän orientoituneiden käyttäjien luoda monipuolisia chatbot-virtoja, ja AI-komponentit integroituvat johtaviin kielimalleihin kuten ChatGPT ja Claude. FlowHuntin arviointityökalut tukevat LLM Arvostelijana -menetelmää, jolloin voit määrittää omat arviointikriteerisi ja arvioida chatbotin suorituskykyä automaattisesti koko keskusteluaineistossasi.
Kattavan tarkkuusmittauksen toteuttamiseksi FlowHuntilla aloita määrittelemällä omat arviointikriteerisi liiketoimintatavoitteiden mukaan – painotatko tarkkuutta, nopeutta, käyttäjätyytyväisyyttä vai ratkaisuprosentteja. Määrittele arvostelevalle LLM:lle tarkat ohjeet siitä, miten vastaukset arvioidaan, mukaan lukien esimerkit hyvistä ja huonoista vastauksista. Lataa keskusteluaineistosi tai yhdistä live-liikenne, ja suorita arvioinnit tuottaaksesi yksityiskohtaiset raportit kaikista mittareista. FlowHuntin hallintapaneeli tarjoaa reaaliaikaisen näkymän chatbotin suorituskykyyn, mahdollistaen nopean ongelmien tunnistamisen ja parannusten validoinnin.
Luo vertailupohja ennen parannusten käyttöönottoa, jotta muutosten vaikutusta voidaan arvioida. Kerää mittauksia jatkuvasti eikä vain ajoittain, jotta suorituskyvyn heikentyminen havaitaan ajoissa esimerkiksi datadriftin tai mallin vanhenemisen vuoksi. Toteuta palautesilmukka, jossa käyttäjäarviot ja korjaukset syötetään automaattisesti takaisin koulutusprosessiin, mikä jatkuvasti parantaa chatbotin tarkkuutta. Segmentoi mittarit ongelmakategorian, käyttäjätyypin ja aikajakson mukaan, jotta löydät tarkat kehityskohteet – älä tyydy pelkkiin kokonaiskeskiarvoihin.
Varmista, että arviointiaineisto edustaa oikeita käyttäjäkysymyksiä ja odotettuja vastauksia, vältä keinotekoisia testitapauksia, jotka eivät vastaa todellista käyttöä. Vertaile säännöllisesti automaattisia mittareita ihmisten arvioihin ottamalla satunnaisotanta keskusteluista manuaaliseen tarkasteluun, jotta mittausjärjestelmä pysyy kalibroituna todelliseen laatuun. Dokumentoi mittausmenetelmäsi ja mittarien määritelmät selkeästi, jotta arviointi pysyy yhtenäisenä ajan myötä ja tulosten viestintä on johdonmukaista sidosryhmille. Lopuksi, aseta jokaiselle mittarille liiketoimintatavoitteisiin perustuvat suorituskykytavoitteet, jotka tuovat jatkuvuutta kehitykseen ja selkeät päämäärät optimointityölle.
FlowHuntin kehittynyt AI-automaatioalusta auttaa sinua luomaan, ottamaan käyttöön ja arvioimaan suorituskykyisiä helpdesk-chatbotteja sisäänrakennetuilla tarkkuuden mittaustyökaluilla ja LLM-pohjaisilla arviointikyvykkyyksillä.
Opi kattavat tekoälychatbottien testausstrategiat, mukaan lukien toiminnallinen, suorituskyky-, tietoturva- ja käytettävyystestaus. Löydä parhaat käytännöt, työ...
Hallitse AI-chatbottien käyttö kattavalla oppaallamme. Opi tehokkaat kysymysten asettelun tekniikat, parhaat käytännöt ja kuinka saat parhaan hyödyn irti AI-cha...
Opi, miksi AI-mallin tarkkuus ja vakaus ovat tärkeitä koneoppimisessa. Tutustu siihen, miten nämä mittarit vaikuttavat sovelluksiin kuten petosten tunnistukseen...