
Tiedonhaku
Tiedonhaku hyödyntää tekoälyä, luonnollisen kielen käsittelyä ja koneoppimista tiedon tehokkaaseen ja tarkkaan hakemiseen käyttäjän tarpeiden mukaan. Tiedonhaku...
5 min lukuaika
Information Retrieval
AI
+4

AI-haku hyödyntää koneoppimista ja vektoriupotuksia ymmärtääkseen hakutarkoituksen ja kontekstin, tarjoten erittäin osuvia tuloksia pelkkien avainsanojen sijaan.
AI-haku käyttää koneoppimista ymmärtääkseen hakukyselyiden kontekstin ja tarkoituksen, muuntaen ne numeerisiksi vektoreiksi tarkempia tuloksia varten. Toisin kuin perinteiset avainsanahaun menetelmät, AI-haku tulkitsee semanttisia suhteita, mikä tekee siitä tehokkaan erilaisille datatyypeille ja kielille.
AI-haku – usein kutsuttu myös semanttiseksi tai vektorihakuksi – on hakumenetelmä, joka hyödyntää koneoppimismalleja ymmärtääkseen hakukyselyiden tarkoituksen ja kontekstuaalisen merkityksen. Toisin kuin perinteinen avainsanahaku, AI-haku muuntaa datan ja kyselyt numeerisiksi esityksiksi, joita kutsutaan vektoreiksi tai upotuksiksi. Tämä mahdollistaa hakukoneen ymmärtää semanttiset suhteet eri tietoelementtien välillä ja tarjoaa osuvampia sekä tarkempia tuloksia, vaikka täsmällisiä avainsanoja ei esiintyisikään.
AI-haku edustaa merkittävää kehitysaskelta hakuteknologioissa. Perinteiset hakukoneet perustuvat pitkälti avainsanojen täsmäytykseen, jossa tiettyjen termien esiintyminen sekä kyselyssä että dokumenteissa määrittää osuvuuden. AI-haku sen sijaan hyödyntää koneoppimismalleja ymmärtääkseen kyselyiden ja datan taustalla olevan kontekstin ja merkityksen.
Muuntaessaan tekstiä, kuvia, ääntä ja muuta jäsentämätöntä dataa korkeaan ulottuvuuteen vektoreiksi, AI-haku voi mitata erilaisten sisältöjen samankaltaisuutta. Tämä mahdollistaa hakukoneen tarjoamaan kontekstuaalisesti osuvia tuloksia, vaikka niissä ei esiintyisikään täsmälleen samoja avainsanoja kuin hakukyselyssä.
Keskeiset osat:
AI-haun ytimessä on vektoriupotusten käsite. Vektoriupotukset ovat datan numeerisia esityksiä, jotka kuvaavat tekstin, kuvien tai muiden tietotyyppien semanttista merkitystä. Nämä upotukset sijoittavat toisiinsa semanttisesti liittyvät tietoelementit lähelle toisiaan moniulotteisessa vektoriavaruudessa.
Miten se toimii:
Esimerkki:
Perinteiset avainsanapohjaiset hakukoneet toimivat täsmäyttämällä kyselyn termit dokumentteihin, joissa esiintyy samoja termejä. Ne hyödyntävät usein käänteisiä indeksejä ja termien esiintymistiheyksiä tulosten järjestämiseen.
Avainsanahaun rajoitukset:
AI-haun edut:
| Ominaisuus | Avainsanapohjainen haku | AI-haku (Semanttinen/Vektori) |
|---|---|---|
| Täsmäytys | Täsmällinen avainsanaosuma | Semanttinen samankaltaisuus |
| Kontekstin ymmärrys | Rajoittunut | Korkea |
| Synonyymien käsittely | Vaatii manuaaliset synonyymilistat | Automaattinen upotusten avulla |
| Kirjoitusvirheet | Saattaa epäonnistua ilman epäselvyyshakua | Sietää paremmin semanttisen kontekstin ansiosta |
| Tarkoituksen ymmärrys | Vähäinen | Merkittävä |
Semanttinen haku on AI-haun ydin, jossa keskitytään käyttäjän tarkoituksen ja kyselyiden kontekstuaalisen merkityksen ymmärtämiseen.
Prosessi:
Keskeiset tekniikat:
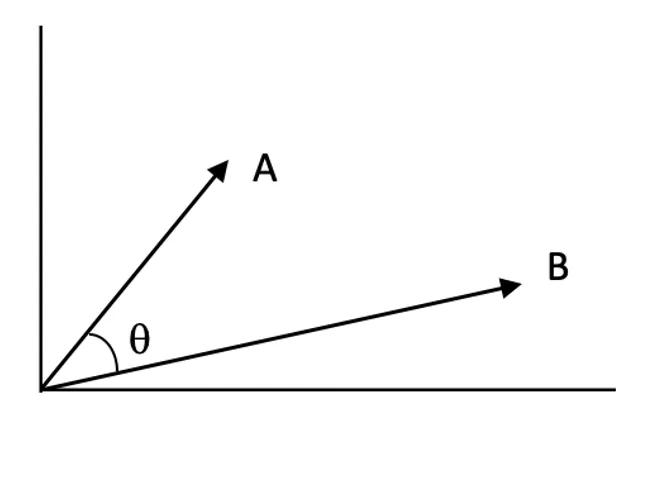
Samankaltaisuuspisteet:
Samankaltaisuuspisteet ilmaisevat, kuinka läheisesti kaksi vektoria liittyvät toisiinsa vektoriavaruudessa. Korkeampi piste tarkoittaa suurempaa osuvuutta kyselyn ja dokumentin välillä.
Likimääräiset lähimmän naapurin (ANN) algoritmit:
Täsmällisten lähimpien naapureiden etsiminen korkeaulotteisissa avaruuksissa on laskennallisesti raskasta. ANN-algoritmit tarjoavat tehokkaat arviot.
AI-haku avaa laajan sovellusalueen eri toimialoilla kyvykkyytensä ansiosta ymmärtää dataa pelkkää avainsanavastaavuutta syvemmin.
Kuvaus: Semanttinen haku parantaa käyttäjäkokemusta tulkitsemalla kyselyiden tarkoituksen ja tarjoamalla kontekstuaalisesti osuvia tuloksia.
Esimerkkejä:
Kuvaus: Ymmärtämällä käyttäjän mieltymyksiä ja käyttäytymistä AI-haku voi tarjota personoituja sisältö- tai tuotesuosituksia.
Esimerkkejä:
Kuvaus: AI-haku mahdollistaa järjestelmien ymmärtää ja vastata käyttäjän kyselyihin tarkalla tiedolla dokumenteista.
Esimerkkejä:
Kuvaus: AI-haku voi indeksoida ja etsiä jäsentämättömiä datatyyppejä, kuten kuvia, ääntä ja videoita, muuntamalla ne upotuksiksi.
Esimerkkejä:
AI-haun integrointi automaatiojärjestelmiin ja chatboteihin parantaa niiden kyvykkyyttä merkittävästi.
Hyödyt:
Toteutusvaiheet:
Käyttöesimerkki:
Vaikka AI-haku tarjoaa paljon etuja, on olemassa myös haasteita:
Ratkaisustrategioita:
Semanttinen ja vektorihaku tekoälyssä ovat nousseet tehokkaiksi vaihtoehdoiksi perinteiselle avainsanapohjaiselle ja epätarkalle haulle, parantaen merkittävästi hakutulosten osuvuutta ja tarkkuutta ymmärtämällä kyselyiden kontekstin ja merkityksen.
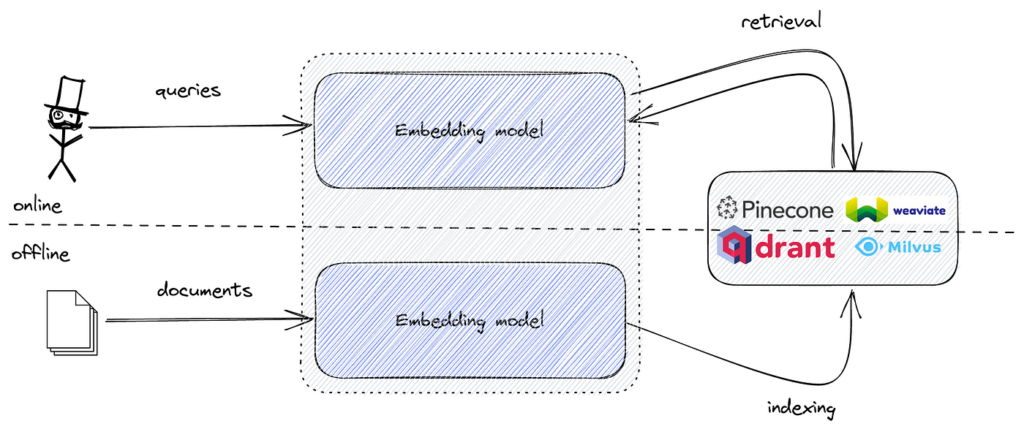
Semanttista hakua toteutettaessa tekstidata muunnetaan vektoriupotuksiksi, jotka vangitsevat tekstin semanttisen merkityksen. Nämä upotukset ovat korkeaulotteisia numeerisia esityksiä. Jotta upotuksia voidaan hakea tehokkaasti ja löytää kyselyupotusta lähimpänä olevat, tarvitaan työkalu, joka on optimoitu samankaltaisuushakuun korkeaulotteisessa avaruudessa.
FAISS tarjoaa tarvittavat algoritmit ja tietorakenteet tämän tehtävän suorittamiseen tehokkaasti. Yhdistämällä semanttiset upotukset FAISSiin voidaan rakentaa tehokas semanttinen hakukone, joka käsittelee suuria tietojoukkoja pienellä viiveellä.
FAISSin avulla semanttisen haun toteutus Pythonilla etenee seuraavasti:
Käydään vaiheet läpi tarkemmin.
Valmistele aineistosi (esim. artikkelit, tukipyynnöt, tuotekuvaukset).
Esimerkki:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Puhdista ja muotoile tekstidata tarpeen mukaan.
Muunna tekstidata vektoriupotuksiksi hyödyntämällä esikoulutettuja Transformer-malleja, kuten Hugging Face (transformers tai sentence-transformers) -kirjastoja.
Esimerkki:
from sentence_transformers import SentenceTransformer
import numpy as np
# Lataa esikoulutettu malli
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Luo upotukset kaikille dokumenteille
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32, kuten FAISS vaatii.Luo FAISS-indeksi upotusten tallentamista ja tehokasta samankaltaisuushakua varten.
Esimerkki:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 suorittaa yksinkertaisen (brute-force) haun käyttäen L2- (euklidista) etäisyyttä.Muunna käyttäjän kysely upotukseksi ja etsi lähimmät naapurit.
Esimerkki:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Tulosta osuvimmat dokumentit indeksien avulla.
Esimerkki:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Odotettu tulos:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS tarjoaa useita indeksityyppejä:
Käänteistiedostoindeksin (IndexIVFFlat) käyttö:
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalisointi ja sisätulohaku:
Kosinietäisyyden käyttäminen voi olla tehokkaampaa tekstipohjaisessa datassa
AI-haku on moderni hakumenetelmä, joka hyödyntää koneoppimista ja vektoriupotuksia ymmärtääkseen kyselyiden tarkoituksen ja kontekstin, tarjoten tarkempia ja osuvampia tuloksia kuin perinteinen avainsanahaku.
Toisin kuin avainsanahaku, joka perustuu täsmällisiin osumiin, AI-haku tulkitsee kyselyiden semanttisia suhteita ja tarkoitusta, minkä ansiosta se toimii tehokkaasti luonnollisella kielellä ja epäselvissä syötteissä.
Vektoriupotukset ovat tekstin, kuvien tai muiden datatyyppien numeerisia esityksiä, jotka kuvaavat niiden semanttista merkitystä ja mahdollistavat hakukoneen mittaamaan samankaltaisuutta sekä kontekstia eri tietoelementtien välillä.
AI-haku mahdollistaa semanttisen haun verkkokaupoissa, personoidut suositukset suoratoistossa, kysymys-vastaus-järjestelmät asiakaspalvelussa, jäsentämättömän datan selaamisen sekä dokumenttien haun tutkimuksessa ja yritysympäristöissä.
Suosittuja työkaluja ovat mm. FAISS tehokkaaseen vektoripohjaiseen samankaltaisuushakuun sekä vektoripohjaiset tietokannat, kuten Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch ja Pgvector upotusten skaalautuvaan tallennukseen ja hakuun.
AI-haun integrointi mahdollistaa, että chatbotit ja automaatiojärjestelmät ymmärtävät käyttäjäkyselyitä syvemmin, hakevat kontekstuaalisesti osuvia vastauksia ja tarjoavat dynaamisia, personoituja reaktioita.
Haasteita ovat mm. korkeat laskennalliset vaatimukset, mallien tulkinnan vaikeus, laadukkaan datan tarve sekä yksityisyyden ja tietoturvan varmistaminen arkaluontoisen tiedon kanssa.
FAISS on avoimen lähdekoodin kirjasto tehokkaaseen korkean ulottuvuuden vektoriupotusten samankaltaisuushakuun, jota käytetään laajasti semanttisten hakukoneiden rakentamiseen suurille tietojoukoille.
Opi, miten tekoälyllä tehostettu semanttinen haku voi mullistaa tiedonhankinnan, chatbotit ja automaatioprosessit.
Tiedonhaku hyödyntää tekoälyä, luonnollisen kielen käsittelyä ja koneoppimista tiedon tehokkaaseen ja tarkkaan hakemiseen käyttäjän tarpeiden mukaan. Tiedonhaku...
Tutustu tekoälyn hakuhakuun perustuvan generoinnin (RAG) ja välimuistiin perustuvan generoinnin (CAG) tärkeimpiin eroihin. RAG hakee reaaliaikaista tietoa joust...
Ota selvää, mitä Insight Engine on—edistynyt, tekoälypohjainen alusta, joka parantaa tiedonhakua ja analyysiä ymmärtämällä kontekstin ja käyttäjän aikomuksen. L...
