Koneoppiminen
Koneoppiminen (ML) on tekoälyn (AI) osa-alue, joka mahdollistaa koneiden oppimisen datasta, kaavojen tunnistamisen, ennusteiden tekemisen ja päätöksenteon paran...
2 min lukuaika
Machine Learning
AI
+4
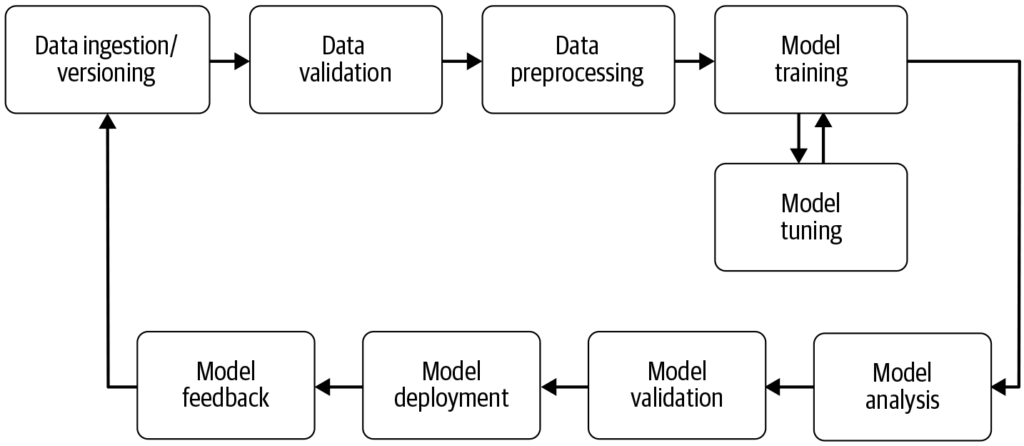
Koneoppimisen putki automatisoi vaiheet datan keruusta mallin käyttöönottoon, parantaen tehokkuutta, toistettavuutta ja skaalautuvuutta koneoppimisprojekteissa.
Koneoppimisen putki on automatisoitu työnkulku, joka virtaviivaistaa mallien kehityksen, koulutuksen, arvioinnin ja käyttöönoton. Se parantaa tehokkuutta, toistettavuutta ja skaalautuvuutta mahdollistaen tehtävät datan keruusta mallin käyttöönottoon ja ylläpitoon.
Koneoppimisen putki on automatisoitu työnkulku, joka kattaa sarjan vaiheita koneoppimismallien kehityksessä, koulutuksessa, arvioinnissa ja käyttöönotossa. Sen tavoitteena on virtaviivaistaa ja standardoida prosessit, joilla raakadata muutetaan käyttökelpoisiksi oivalluksiksi koneoppimisalgoritmien avulla. Putkiratkaisu mahdollistaa datan, mallin koulutuksen ja käyttöönoton tehokkaan käsittelyn, helpottaen koneoppimisen operaatioiden hallintaa ja skaalaamista.
Lähde: Building Machine Learning
Datan keruu: Alkuvaihe, jossa dataa kerätään eri lähteistä, kuten tietokannoista, API-rajapinnoista tai tiedostoista. Datan keruu on järjestelmällinen käytäntö, jonka tarkoituksena on hankkia merkityksellistä tietoa yhtenäisen ja kattavan aineiston rakentamiseksi tiettyä liiketoiminnallista tarkoitusta varten. Tämä raakadata on olennaista koneoppimismallien rakentamisessa, mutta vaatii usein esikäsittelyä ollakseen käyttökelpoista. Kuten AltexSoft korostaa, datan keruu sisältää tiedon järjestelmällisen keräämisen analytiikan ja päätöksenteon tueksi. Prosessi on ratkaiseva, sillä se luo perustan kaikille seuraaville putken vaiheille ja on usein jatkuvaa, jotta mallit koulutetaan ajantasaisella datalla.
Datan esikäsittely: Raakadata puhdistetaan ja muunnetaan mallin koulutukseen sopivaan muotoon. Tavallisia esikäsittelyvaiheita ovat puuttuvien arvojen käsittely, kategoristen muuttujien koodaus, numeeristen piirteiden skaalaus sekä datan jakaminen koulutus- ja testijoukkoihin. Tämä vaihe varmistaa, että data on oikeassa muodossa ja vapaa ristiriitaisuuksista, jotka voisivat vaikuttaa mallin suorituskykyyn.
Piirteiden suunnittelu: Uusien piirteiden luominen tai olennaisten piirteiden valinta datasta mallin ennustekyvyn parantamiseksi. Tämä vaihe saattaa vaatia alakohtaista osaamista ja luovuutta. Piirteiden suunnittelu on luova prosessi, jossa raakadata muunnetaan merkityksellisiksi piirteiksi, jotka kuvaavat ongelmaa paremmin ja parantavat koneoppimismallien suorituskykyä.
Mallin valinta: Sopivat koneoppimisalgoritmit valitaan ongelmatyypin (esim. luokittelu, regressio), datan ominaisuuksien ja suorituskykyvaatimusten perusteella. Tässä vaiheessa voidaan myös tehdä hyperparametrien viritystä. Oikean mallin valinta on ratkaisevaa, sillä se vaikuttaa ennusteiden tarkkuuteen ja tehokkuuteen.
Mallin koulutus: Valitut mallit koulutetaan käyttämällä koulutusdataa. Tässä vaiheessa malli oppii datan taustalla olevat rakenteet ja suhteet. Tarvittaessa voidaan hyödyntää myös esikoulutettuja malleja uuden mallin kouluttamisen sijaan. Koulutus on olennainen vaihe, jossa malli oppii tekemään perusteltuja ennusteita.
Mallin arviointi: Koulutuksen jälkeen mallin suorituskyky arvioidaan erillisellä testidatalla tai ristiinvalidoinnilla. Arviointimetriikat riippuvat ongelmasta, mutta voivat sisältää esimerkiksi tarkkuuden, osuvuuden, palautuksen, F1-pisteen, keskineliövirheen ja muita. Tämä vaihe on tärkeä, jotta voidaan varmistaa mallin toimivuus uudella datalla.
Mallin käyttöönotto: Kun malli on kehitetty ja arvioitu riittävän hyväksi, se voidaan ottaa käyttöön tuotantoympäristössä tekemään ennusteita uudesta, näkemättömästä datasta. Käyttöönotto voi sisältää API-rajapintojen luomista ja integrointia muihin järjestelmiin. Käyttöönotto on putken viimeinen vaihe, jossa malli tuodaan todelliseen käyttöön.
Valvonta ja ylläpito: Käyttöönoton jälkeen mallin suorituskykyä on tärkeää seurata jatkuvasti ja kouluttaa uudelleen tarpeen mukaan, jotta se sopeutuu muuttuviin datan rakenteisiin ja pysyy tarkkana ja luotettavana käytännön ympäristöissä. Tämä jatkuva prosessi varmistaa, että malli pysyy ajan tasalla ja relevanttina.
Luonnollisen kielen käsittely yhdistää ihmisen ja tietokoneen vuorovaikutuksen. Tutustu sen keskeisiin ominaisuuksiin, toimintaperiaatteisiin ja sovelluksiin! (NLP): NLP-tehtävät sisältävät usein useita toistuvia vaiheita, kuten datan lukemisen, tekstin puhdistuksen, tokenisoinnin ja sentimenttianalyysin. Putket auttavat näiden vaiheiden moduloinnissa, mahdollistaen helpon muokkaamisen ilman vaikutuksia muihin osiin.
Ennakoiva huolto: Esimerkiksi valmistavassa teollisuudessa putkia voidaan käyttää laitevikojen ennustamiseen sensoridatan avulla, mikä mahdollistaa ennakoivan huollon ja vähentää seisokkeja.
Rahoitusala: Putket voivat automatisoida talousdatan käsittelyä petosten tunnistukseen, luottoriskien arviointiin tai osakekurssien ennustamiseen, tehostaen päätöksentekoa.
Terveydenhuolto: Terveydenhuollossa putket voivat käsitellä esimerkiksi lääketieteellisiä kuvia tai potilastietoja diagnostiikan tukena tai potilastulosten ennustamisessa, parantaen hoitostrategioita.
Koneoppimisen putket ovat keskeinen osa tekoälyä ja automaatiota tarjoamalla rakenteellisen kehyksen koneoppimistehtävien automatisointiin. AI-automaation alueella putket varmistavat, että mallit koulutetaan ja otetaan käyttöön tehokkaasti, mahdollistaen AI-järjestelmien, kuten [chatbottien], oppimisen ja sopeutumisen uuteen dataan ilman manuaalista puuttumista. Tämä automaatio on ratkaisevaa AI-sovellusten skaalaamisessa ja niiden suorituskyvyn varmistamisessa eri toimialoilla. Putkia hyödyntämällä organisaatiot voivat kehittää AI-osaamistaan ja varmistaa koneoppimismalliensa ajantasaisuuden ja toimivuuden muuttuvissa ympäristöissä.
Tutkimuksia koneoppimisen putkista
“Deep Pipeline Embeddings for AutoML” (Sebastian Pineda Arango ja Josif Grabocka, 2023) käsittelee koneoppimisen putkien optimoinnin haasteita automaattisessa koneoppimisessa (AutoML). Artikkelissa esitellään uusi neuroverkkopohjainen arkkitehtuuri, joka mallintaa syviä vuorovaikutuksia putken komponenttien välillä. Kirjoittajat ehdottavat putkien upottamista latentteihin esityksiin ainutlaatuisella komponenttikohtaisella koodausratkaisulla. Näitä upotuksia käytetään Bayesian optimoinnissa optimaalisten putkien löytämiseksi. Artikkeli korostaa metaoppimisen hyödyntämistä verkon parametrien hienosäätöön ja esittelee parhaat tulokset putkioptimoinnissa useilla tietoaineistoilla. Lue lisää.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” (Tien-Dung Nguyen ym., 2020) pureutuu koneoppimisen putkien aikaa vievään arviointiin AutoML-prosesseissa. Tutkimus kritisoi perinteisiä, kuten Bayesilaisia ja geneettisiä optimointimenetelmiä tehottomuudesta. Ratkaisuksi esitetään AVATAR, sijaismalli, joka arvioi putkien kelvollisuutta ilman niiden suorittamista. Menetelmä nopeuttaa monimutkaisten putkien koostamista ja optimointia suodattamalla virheelliset putket jo varhaisessa vaiheessa. Lue lisää.
“Data Pricing in Machine Learning Pipelines” (Zicun Cong ym., 2021) tarkastelee datan keskeistä roolia koneoppimisen putkissa ja datan hinnoittelun merkitystä monen osapuolen yhteistyön mahdollistajana. Artikkeli esittelee uusimmat kehitykset datan hinnoittelussa koneoppimisen kontekstissa ja korostaa sen merkitystä putken eri vaiheissa. Se tarjoaa näkemyksiä hinnoittelustrategioista koulutusdatan keruuseen, yhteismallin koulutukseen ja koneoppimispalvelujen tarjoamiseen, korostaen dynaamisen ekosysteemin muodostumista. Lue lisää.
Koneoppimisen putki on automatisoitu sarja vaiheita – datan keruusta ja esikäsittelystä mallin koulutukseen, arviointiin ja käyttöönottoon – joka virtaviivaistaa ja standardoi koneoppimismallien rakentamisen ja ylläpidon prosessin.
Keskeisiä komponentteja ovat datan keruu, datan esikäsittely, piirteiden suunnittelu, mallin valinta, mallin koulutus, mallin arviointi, mallin käyttöönotto sekä jatkuva valvonta ja ylläpito.
Koneoppimisen putket mahdollistavat modulaarisuuden, tehokkuuden, toistettavuuden, skaalautuvuuden, paremman yhteistyön ja helpottavat mallien käyttöönottoa tuotantoympäristöihin.
Käyttökohteita ovat muun muassa kieliteknologia (NLP), ennakoiva huolto teollisuudessa, taloudellinen riskien arviointi ja petosten tunnistus sekä terveydenhuollon diagnostiikka.
Haasteita ovat muun muassa datan laadun varmistaminen, putken monimutkaisuuden hallinta, integrointi olemassa oleviin järjestelmiin sekä laskenta- ja infrastruktuurikustannusten hallinta.
Varaa demo ja tutustu, miten FlowHunt voi auttaa sinua automatisoimaan ja skaalaamaan koneoppimisen työnkulut vaivattomasti.
Koneoppiminen (ML) on tekoälyn (AI) osa-alue, joka mahdollistaa koneiden oppimisen datasta, kaavojen tunnistamisen, ennusteiden tekemisen ja päätöksenteon paran...
Siirtäoppiminen on tehokas tekoälyn ja koneoppimisen menetelmä, jossa valmiiksi koulutettuja malleja mukautetaan uusiin tehtäviin. Tämä parantaa suorituskykyä v...
Opi, miten FlowHuntin Prompt-komponentilla voit määritellä tekoälybotin roolin ja käyttäytymisen, varmistaen osuvat ja yksilölliset vastaukset. Mukauta kehottei...