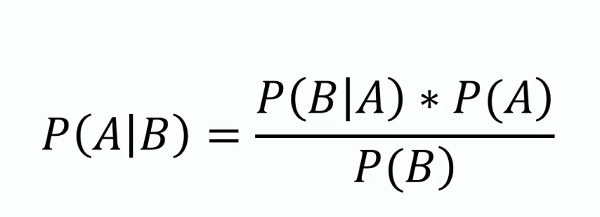

Bayes-verkostot
Bayes-verkosto (BN) on todennäköisyyksiin perustuva graafinen malli, joka esittää muuttujat ja niiden ehdolliset riippuvuudet suunnatun syklittömän graafin (DAG...
3 min lukuaika
Bayesian Networks
AI
+3
Naivibayes on yksinkertainen mutta tehokas luokittelualgoritmien perhe, joka hyödyntää Bayesin kaavaa ja jota käytetään yleisesti skaalautuviin tehtäviin kuten roskapostin tunnistukseen ja tekstiluokitteluun.
Naivibayes on joukko yksinkertaisia, tehokkaita luokittelualgoritmeja, jotka perustuvat Bayesin kaavaan ja olettavat piirteiden olevan ehdollisesti riippumattomia. Sitä käytetään laajasti esimerkiksi roskapostin tunnistukseen ja tekstiluokitteluun sen yksinkertaisuuden ja skaalautuvuuden ansiosta.
Naivibayes on luokittelualgoritmien perhe, joka perustuu Bayesin kaavaan ja hyödyntää ehdollisen todennäköisyyden periaatetta. Termi “naivibayes” viittaa yksinkertaistavaan oletukseen, että kaikki datan piirteet ovat ehdollisesti riippumattomia toisistaan annetun luokkatunnisteen suhteen. Vaikka tämä oletus todellisessa datassa usein rikkoutuu, Naivibayes-luokittelijat tunnetaan yksinkertaisuudestaan ja tehokkuudestaan esimerkiksi tekstiluokittelussa ja roskapostisuodatuksessa.
Bayesin kaava
Tämä kaava muodostaa Naivibayesin perustan, tarjoten tavan päivittää hypoteesin todennäköisyys, kun uutta näyttöä tai tietoa tulee saataville. Matemaattisesti se esitetään seuraavasti:
missä ( P(A|B) ) on posterioritodennäköisyys, ( P(B|A) ) on uskottavuus, ( P(A) ) on prioriodennäköisyys ja ( P(B) ) on evidenssi.
Ehdollinen riippumattomuus
Naiviolettamus siitä, että jokainen piirre on riippumaton kaikista muista piirteistä annetun luokkatunnisteen suhteen. Tämä oletus yksinkertaistaa laskentaa ja mahdollistaa algoritmin skaalautumisen suuriin aineistoihin.
Posterioritodennäköisyys
Luokkatunnisteen todennäköisyys annettujen piirteiden perusteella, laskettuna Bayesin kaavalla. Tämä on keskeinen osa Naivibayesin tekemissä ennusteissa.
Naivibayes-luokittelijoiden tyypit
Naivibayes-luokittelijat toimivat laskemalla kullekin luokalle posterioritodennäköisyyden annettujen piirteiden perusteella ja valitsevat luokan, jolla on korkein posterioritodennäköisyys. Prosessi sisältää seuraavat vaiheet:
Naivibayes-luokittelijat ovat erityisen tehokkaita seuraavissa käyttökohteissa:
Kuvitellaan roskapostisuodatin, joka käyttää Naivibayesia. Koulutusdata sisältää sähköposteja, jotka on merkitty “roskapostiksi” tai “ei roskapostiksi”. Jokainen sähköposti kuvataan piirteillä, kuten tiettyjen sanojen esiintymisellä. Koulutuksen aikana algoritmi laskee kunkin sanan todennäköisyyden annetussa luokassa. Uudelle sähköpostille algoritmi laskee posterioritodennäköisyyden “roskapostille” ja “ei roskapostille” ja valitsee korkeamman todennäköisyyden mukaisen luokan.
Naivibayes-luokittelijat voidaan integroida tekoälyjärjestelmiin ja chatboteihin parantamaan niiden luonnollisen kielen käsittelyominaisuuksia. Esimerkiksi niitä voidaan käyttää käyttäjän viestin tarkoituksen tunnistamiseen, tekstien luokitteluun ennalta määriteltyihin kategorioihin tai sopimattoman sisällön suodattamiseen. Tämä parantaa vuorovaikutuksen laatua ja tekoälyratkaisujen osuvuutta. Lisäksi algoritmin tehokkuus tekee siitä sopivan reaaliaikaisiin sovelluksiin, mikä on tärkeää tekoälyautomaation ja chatbot-järjestelmien kannalta.
Naivibayes on joukko yksinkertaisia mutta tehokkaita todennäköisyyspohjaisia algoritmeja, jotka perustuvat Bayesin kaavan soveltamiseen vahvoin riippumattomuusoletuksin piirteiden välillä. Sitä käytetään laajasti luokittelutehtävissä yksinkertaisuutensa ja tehokkuutensa ansiosta. Tässä muutamia tieteellisiä artikkeleita, joissa käsitellään Naivibayes-luokittelijan sovelluksia ja parannuksia:
Roskapostisuodatuksen parantaminen yhdistämällä Naivibayes ja yksinkertainen k-lähimmän naapurin etsintä
Kirjoittaja: Daniel Etzold
Julkaistu: 30. marraskuuta 2003
Tässä artikkelissa tutkitaan Naivibayesin käyttöä sähköpostin luokittelussa ja korostetaan sen helppoa toteutusta ja tehokkuutta. Tutkimuksessa esitetään empiirisiä tuloksia siitä, miten Naivibayesin yhdistäminen k-lähimmän naapurin etsintään voi parantaa roskapostisuodattimen tarkkuutta. Yhdistelmä paransi hieman tarkkuutta, kun piirteitä oli paljon, ja merkittävästi, kun piirteitä oli vähän. Lue artikkeli.
Paikallisesti painotettu Naivibayes
Kirjoittajat: Eibe Frank, Mark Hall, Bernhard Pfahringer
Julkaistu: 19. lokakuuta 2012
Tässä artikkelissa käsitellään Naivibayesin keskeistä heikkoutta eli ominaisuuksien riippumattomuusoletusta. Siinä esitellään paikallisesti painotettu Naivibayes, joka oppii paikallisia malleja ennustusvaiheessa ja näin lieventää riippumattomuusoletusta. Kokeelliset tulokset osoittavat, että lähestymistapa harvoin heikentää tarkkuutta ja usein parantaa sitä merkittävästi. Menetelmää kiitetään myös sen käsitteellisestä ja laskennallisesta yksinkertaisuudesta verrattuna muihin tekniikoihin. Lue artikkeli.
Naivibayes-loukkautumisen tunnistus planeettamönkijöille
Kirjoittaja: Dicong Qiu
Julkaistu: 31. tammikuuta 2018
Tässä tutkimuksessa käsitellään Naivibayes-luokittelijoiden käyttöä planeettamönkijöiden loukkautumisen tunnistamisessa. Siinä määritellään loukkautumisen kriteerit ja osoitetaan Naivibayesin käyttö tällaisissa tilanteissa. Artikkelissa kuvataan AutoKrawler-mönkijöillä tehdyt kokeet ja esitellään Naivibayesin tehokkuus autonomisissa pelastusmenettelyissä. Lue artikkeli.
Naivibayes on luokittelualgoritmien perhe, joka perustuu Bayesin kaavaan ja olettaa, että kaikki piirteet ovat ehdollisesti riippumattomia annetun luokkatunnisteen suhteen. Sitä käytetään laajasti tekstin luokittelussa, roskapostisuodatuksessa ja sentimenttianalyysissä.
Tärkeimmät tyypit ovat Gaussin Naivibayes (jatkuville piirteille), Multinomialinen Naivibayes (diskreeteille piirteille kuten sanamäärille) ja Bernoullin Naivibayes (binäärisille/piirteille).
Naivibayes on helppo toteuttaa, laskennallisesti tehokas, skaalautuu suuriin aineistoihin ja käsittelee hyvin korkean ulottuvuuden dataa.
Suurin rajoitus on piirteiden riippumattomuusoletus, joka ei usein päde todellisessa datassa. Se voi myös antaa nollatodennäköisyyden näkemättömille piirteille, mutta tätä voidaan lieventää esimerkiksi Laplace-sileytyksellä.
Naivibayesia käytetään tekoälyjärjestelmissä ja chatboteissa esimerkiksi tarkoituksen tunnistamiseen, tekstiluokitteluun, roskapostisuodattamiseen ja sentimenttianalyysiin, mikä parantaa luonnollisen kielen käsittelyn kyvykkyyksiä ja mahdollistaa reaaliaikaiset päätökset.
Älykkäät chatbotit ja tekoälytyökalut saman katon alla. Yhdistä intuitiivisia lohkoja ja muuta ideasi automatisoiduiksi Floweiksi.
Bayes-verkosto (BN) on todennäköisyyksiin perustuva graafinen malli, joka esittää muuttujat ja niiden ehdolliset riippuvuudet suunnatun syklittömän graafin (DAG...
Integroi Naverin OpenAPI-palvelut AI-työnkulkuihisi Naver MCP -palvelimen avulla. Hae reaaliaikaisesti blogi-, uutis-, kirja-, tietosanakirja-, kuva- ja paikall...
No-Code AI -alustat mahdollistavat käyttäjille tekoäly- ja koneoppimismallien rakentamisen, käyttöönoton ja hallinnan ilman koodin kirjoittamista. Nämä alustat ...