Transformer
Transformer-malli on eräänlainen neuroverkko, joka on erityisesti suunniteltu käsittelemään sekventiaalista dataa, kuten tekstiä, puhetta tai aikasarjatietoa. T...
2 min lukuaika
Transformer
Neural Networks
+3
Transformerit ovat mullistavia neuroverkkoja, jotka hyödyntävät self-attentionia rinnakkaiseen tietojenkäsittelyyn ja mahdollistavat mallien kuten BERT ja GPT käytön NLP:ssä, tietokonenäössä ja muilla alueilla.
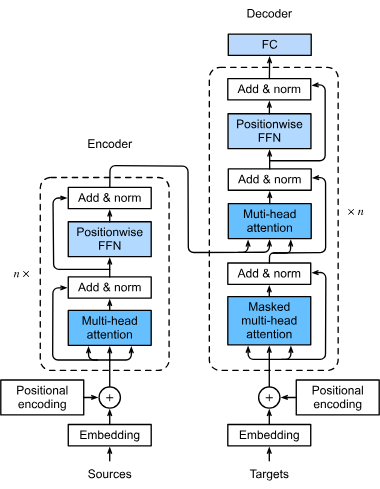
Ensimmäinen vaihe transformerin prosessointiputkessa on muuntaa syötteen sanat tai tokenit numeerisiksi vektoreiksi eli embeddingeiksi. Nämä embeddingit kuvaavat semanttista merkitystä ja ovat olennaisia, jotta malli voi ymmärtää tokenien välisiä suhteita. Tämä muunnos on välttämätön, jotta malli voi käsitellä tekstidataa matemaattisessa muodossa.
Transformerit eivät käsittele dataa luontaisesti järjestyksessä, joten positiokoodausta käytetään tuomaan tietoa kunkin tokenin sijainnista sekvenssissä. Tämä on tärkeää sekvenssin järjestyksen säilyttämiseksi, mikä on olennaista esimerkiksi käännöstehtävissä, joissa konteksti riippuu sanojen järjestyksestä.
Multi-head attention -mekanismi on transformereiden kehittynyt osa, joka mahdollistaa mallin huomioida eri osia syötteestä samanaikaisesti. Laskemalla useita attention-pisteitä malli voi tunnistaa erilaisia suhteita ja riippuvuuksia datassa, parantaen kykyä ymmärtää ja tuottaa monimutkaisia tietokuvioita.
Transformerit noudattavat tyypillisesti encoder-decoder-arkkitehtuuria:
Attention-mekanismin jälkeen data kulkee syväsyötteisten neuroverkkojen läpi, jotka tekevät ei-lineaarisia muunnoksia ja auttavat mallia oppimaan monimutkaisia kuvioita. Nämä verkot viimeistelevät mallin tuottaman ulostulon.
Nämä tekniikat vakauttavat ja nopeuttavat koulutusprosessia. Kerrosnormalisointi pitää ulostulot tietyllä alueella, mikä helpottaa tehokasta mallin koulutusta. Jäännösyhteydet mahdollistavat gradienttien virtaamisen verkossa ilman katoamista, mikä helpottaa syvien neuroverkkojen koulutusta.
Transformerit käsittelevät sekvenssidataa, kuten lauseen sanoja tai muuta järjestettyä tietoa. Ne käyttävät self-attentionia arvioidakseen, miten eri sekvenssin osat liittyvät toisiinsa, mikä mahdollistaa mallin keskittymisen olennaisiin elementteihin, jotka vaikuttavat lopputulokseen.
Self-attentionissa jokainen token verrataan jokaiseen muuhun tokeniin sekvenssissä, jolloin lasketaan attention-pisteet. Nämä pisteet osoittavat kunkin tokenin merkittävyyden suhteessa muihin, mahdollistaen mallin keskittyä tärkeimpiin osiin sekvenssissä. Tämä on ratkaisevaa kontekstin ja merkityksen ymmärtämisessä kielitehtävissä.
Nämä ovat transformerimallin rakennuspalikoita, koostuen self-attention- ja syväsyötteisistä kerroksista. Useita lohkoja pinotaan syväoppiviksi malleiksi, jotka pystyvät tunnistamaan monimutkaisia kuvioita datassa. Moduulirakenne mahdollistaa tehokkaan skaalautuvuuden tehtävän kompleksisuuden mukaan.
Transformerit ovat tehokkaampia kuin RNN- ja CNN-mallit, koska ne pystyvät käsittelemään kokonaisia sekvenssejä kerralla. Tämä mahdollistaa erittäin suurten mallien, kuten GPT-3:n (175 miljardia parametria), rakentamisen. Skaalautuvuus mahdollistaa suurten tietomäärien tehokkaan käsittelyn.
Perinteiset mallit kamppailevat pitkän kantaman riippuvuuksien kanssa niiden peräkkäisen luonteen vuoksi. Transformerit ylittävät tämän rajoituksen self-attentionilla, jonka avulla voidaan huomioida kaikki sekvenssin osat samanaikaisesti. Tämä tekee niistä erittäin tehokkaita tehtävissä, joissa kontekstin ymmärtäminen pitkillä tekstipätkillä on tärkeää.
Vaikka transformerit kehitettiin alun perin NLP-tehtäviin, niitä on sovellettu monille aloille, kuten tietokonenäköön, proteiinien laskennalliseen mallinnukseen ja jopa aikasarjaennustamiseen. Tämä monipuolisuus osoittaa transformerien laajan sovellettavuuden eri aloilla.
Transformerit ovat parantaneet merkittävästi NLP-tehtävien, kuten käännöksen, tiivistämisen ja sentimenttianalyysin suorituskykyä. BERT ja GPT ovat esimerkkejä malleista, jotka hyödyntävät transformer-arkkitehtuuria ymmärtääkseen ja tuottaakseen ihmismäistä tekstiä, asettaen uusia standardeja NLP:lle.
Konekäännöksessä transformerit loistavat ymmärtämällä sanojen kontekstin lauseessa, mahdollistaen tarkemmat käännökset verrattuna aiempiin menetelmiin. Kokonaisen lauseen kerralla käsittely mahdollistaa johdonmukaiset ja kontekstuaalisesti oikeat käännökset.
Transformerit voivat mallintaa aminohapposekvenssejä proteiineissa, auttaen proteiinirakenteiden ennustamisessa. Tämä on tärkeää lääkekehityksessä ja biologisten prosessien ymmärtämisessä. Tämä sovellus korostaa transformerien potentiaalia tieteellisessä tutkimuksessa.
Soveltamalla transformer-arkkitehtuuria voidaan ennustaa tulevia arvoja aikasarjadatassa, kuten sähkönkulutuksen ennustamisessa, analysoimalla aiempia sekvenssejä. Tämä avaa uusia mahdollisuuksia esimerkiksi finanssi- ja resurssienhallinnan aloille.
BERT-mallit on suunniteltu ymmärtämään sanan kontekstia tarkastelemalla sitä ympäröiviä sanoja, mikä tekee niistä erittäin tehokkaita tehtävissä, joissa vaaditaan sanojen suhteiden ymmärrystä lauseessa. Tämä kaksisuuntainen lähestymistapa mahdollistaa tehokkaamman kontekstin käsittelyn kuin yksisuuntaisissa malleissa.
GPT-mallit ovat autoregressiivisia, tuottaen tekstiä ennustamalla seuraavaa sanaa sekvenssissä edellisten perusteella. Niitä käytetään laajasti esimerkiksi tekstin täydentämiseen ja keskustelujen tuottamiseen, osoittaen niiden kyvyn tuottaa ihmismäistä tekstiä.
Alun perin NLP-tehtäviin kehitetyt transformerit on sovellettu myös tietokonenäköön. Vision transformerit käsittelevät kuvadataa sekvenssinä, mahdollistaen transformeritekniikoiden hyödyntämisen visuaalisiin syötteisiin. Tämä on johtanut kehitykseen kuvantunnistuksessa ja käsittelyssä.
Suurten transformeri-mallien koulutus vaatii merkittäviä laskentaresursseja, usein laajoja datamassoja ja tehokkaita laitteistoja, kuten GPU-yksiköitä. Tämä aiheuttaa haasteita kustannusten ja saavutettavuuden suhteen monille organisaatioille.
Transformereiden yleistyessä esiin nousevat kysymykset, kuten AI-mallien mahdolliset vinoumat ja tekoälyn tuottaman sisällön eettinen käyttö. Tutkijat kehittävät keinoja näiden haasteiden ratkaisemiseksi ja vastuullisen tekoälyn kehittämiseksi, mikä korostaa eettisten periaatteiden tarvetta AI-tutkimuksessa.
Transformereiden monipuolisuus avaa jatkuvasti uusia tutkimus- ja sovellusmahdollisuuksia, aina AI-pohjaisten chatbotien kehittämisestä datan analysoinnin parantamiseen terveydenhuollossa ja taloudessa. Transformereiden tulevaisuus lupaa mielenkiintoisia innovaatioita monilla toimialoilla.
Yhteenvetona transformerit ovat merkittävä edistysaskel tekoälyteknologiassa, mahdollistaen ennennäkemättömän tehokkaan sekventiaalisen datan käsittelyn. Niiden innovatiivinen arkkitehtuuri ja tehokkuus ovat asettaneet uuden standardin alalle, vieden tekoälysovellukset uudelle tasolle. Olipa kyseessä kielen ymmärtäminen, tieteellinen tutkimus tai visuaalisen datan käsittely, transformerit määrittävät jatkuvasti uudelleen, mikä tekoälyssä on mahdollista.
Transformerit ovat mullistaneet tekoälytutkimuksen erityisesti luonnollisen kielen käsittelyssä ja ymmärtämisessä. Denis Newman-Griffisin (julkaistu 2024) artikkeli ”AI Thinking: A framework for rethinking artificial intelligence in practice” esittelee uudenlaisen konseptuaalisen kehyksen nimeltä AI Thinking. Tämä kehys mallintaa tekoälyn käyttöön liittyviä keskeisiä päätöksiä ja näkökulmia eri tieteenalojen välillä, huomioiden AI:n motivaation, menetelmien muotoilun ja sijoittumisen sosioteknisiin konteksteihin. Tavoitteena on kaventaa tieteenalojen välisiä kuiluja ja muokata tekoälyn tulevaisuutta käytännössä. Lue lisää.
Toinen merkittävä panos on Evangelos Katsamakasin ym. (julkaistu 2024) artikkeli ”Artificial intelligence and the transformation of higher education institutions”, jossa käytetään kompleksisten järjestelmien lähestymistapaa tekoälymuutoksen syy-seurausmekanismien kartoittamiseen korkeakouluissa. Tutkimuksessa käsitellään tekoälyyn liittyviä ajureita ja sen vaikutuksia arvonluontiin, korostaen korkeakoulujen tarvetta sopeutua tekoälyteknologian kehitykseen samalla kun ylläpidetään akateemista rehellisyyttä ja hallitaan työllisyysmuutoksia. Lue lisää.
Ohjelmistokehityksen saralla Mamdouh Alenezin ja kollegoiden (julkaistu 2022) artikkeli ”Can Artificial Intelligence Transform DevOps?” tarkastelee AI:n ja DevOpsin leikkauspistettä. Tutkimuksessa korostetaan, miten tekoäly voi parantaa DevOps-prosessien toiminnallisuutta ja tehostaa ohjelmistojen toimitusta. Artikkelissa painotetaan tekoälyn käytännön merkitystä ohjelmistokehittäjille ja yrityksille DevOpsin kehittämisessä. Lue lisää
Transformerit ovat vuonna 2017 esitelty neuroverkkorakenne, joka käyttää self-attention-mekanismeja sekventiaalisen datan rinnakkaiseen käsittelyyn. Ne ovat mullistaneet tekoälyn erityisesti luonnollisen kielen käsittelyssä ja tietokonenäössä.
Toisin kuin RNN- ja CNN-mallit, transformerit käsittelevät kaikki sekvenssin osat samanaikaisesti self-attentionin avulla, mikä mahdollistaa suuremman tehokkuuden, skaalautuvuuden ja kyvyn huomioida pitkän kantaman riippuvuuksia.
Transformereita käytetään laajasti NLP-tehtäviin, kuten käännökseen, tiivistämiseen ja sentimenttianalyysiin sekä tietokonenäköön, proteiinirakenteiden ennustamiseen ja aikasarjaennustamiseen.
Tunnettuja transformeri-malleja ovat muun muassa BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) sekä Vision Transformers kuvankäsittelyyn.
Transformereiden kouluttaminen ja käyttöönotto vaatii merkittäviä laskentaresursseja. Lisäksi niihin liittyy eettisiä kysymyksiä, kuten mahdolliset vinoumat AI-malleissa ja generatiivisen AI-sisällön vastuullinen käyttö.
Älykkäät chatbotit ja AI-työkalut saman katon alla. Yhdistä intuitiivisia lohkoja ja muuta ideasi automatisoiduiksi Floweiksi.
Transformer-malli on eräänlainen neuroverkko, joka on erityisesti suunniteltu käsittelemään sekventiaalista dataa, kuten tekstiä, puhetta tai aikasarjatietoa. T...
Tekstintuotanto suurilla kielimalleilla (LLM) tarkoittaa koneoppimismallien kehittynyttä käyttöä ihmismäisen tekstin tuottamiseen annetuista kehotteista. Tutust...
Bidirektionaalinen pitkän aikavälin muisti (BiLSTM) on edistynyt toistuvien neuroverkkojen (RNN) arkkitehtuuri, joka käsittelee sekventiaalista dataa sekä eteen...