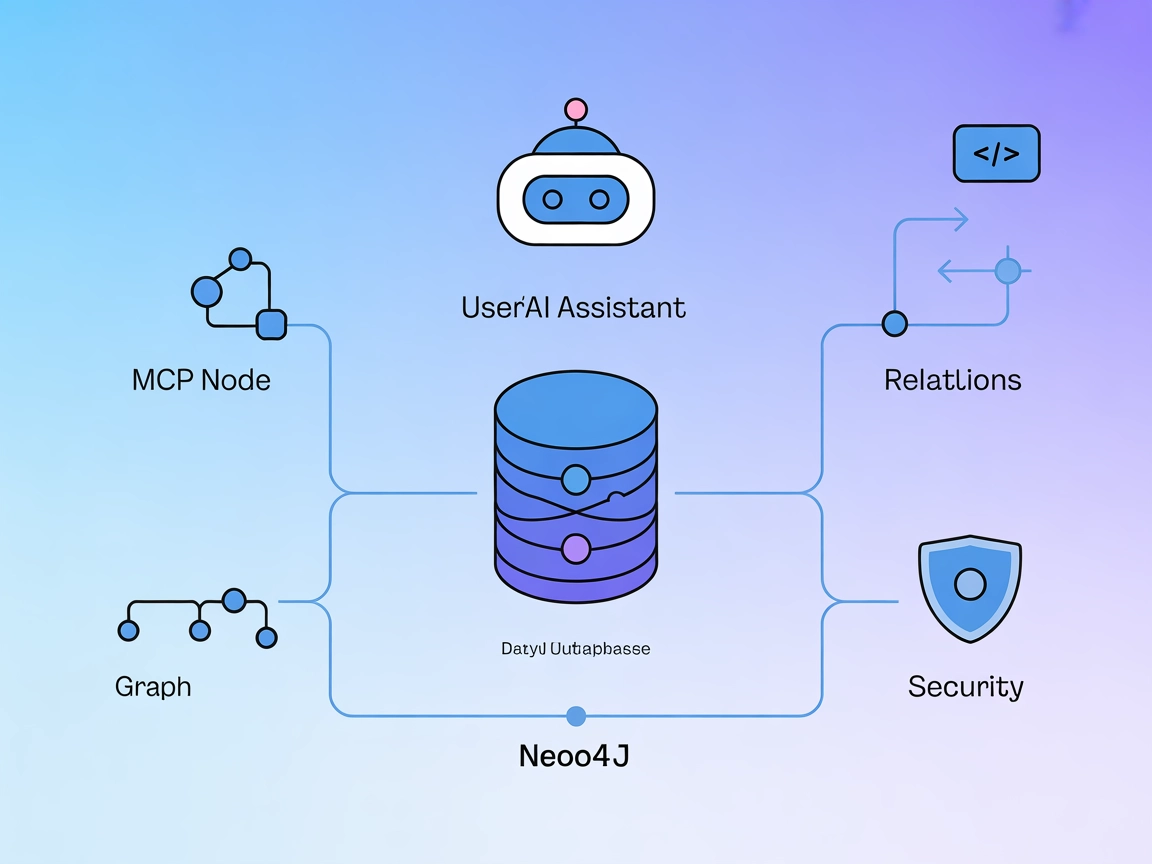
Neo4j MCP Server -integraatio
Neo4j MCP Server yhdistää tekoälyavustajat Neo4j-graafitietokantaan mahdollistaen turvalliset, luonnolliseen kieleen perustuvat graafitoiminnot, Cypher-kyselyt ...
3 min lukuaika
AI
Graph Database
+5
Neo4j MCP Server yhdistää tekoälyavustajat Neo4j-graafitietokantaan mahdollistaen turvalliset, luonnolliseen kieleen perustuvat graafitoiminnot, Cypher-kyselyt ...
NASA MCP -palvelin tarjoaa yhtenäisen rajapinnan tekoälymalleille ja kehittäjille yli 20 NASA:n tietolähteen hyödyntämiseen. Se yhdenmukaistaa NASA:n tieteellis...
Data Exploration MCP Server yhdistää AI-assistentit ulkoisiin tietoaineistoihin interaktiivista analysointia varten. Se mahdollistaa käyttäjille CSV- ja Kaggle-...
MCP Code Executor MCP Serveri mahdollistaa FlowHuntin ja muiden LLM-pohjaisten työkalujen turvallisen Python-koodin suorittamisen eristetyissä ympäristöissä, ri...
Reexpress MCP -palvelin tuo tilastollisen varmistuksen LLM-työnkulkuihin. Similarity-Distance-Magnitude (SDM) -estimaattorin avulla se tarjoaa vankat luottamusa...
Databricks Genie MCP -palvelin mahdollistaa suurten kielimallien vuorovaikutuksen Databricks-ympäristöjen kanssa Genie API:n kautta, tukien keskustelevaa tiedon...
JupyterMCP mahdollistaa Jupyter Notebookin (6.x) saumattoman integroinnin tekoälyavustajiin Model Context Protocolin kautta. Automatisoi koodin suoritus, hallit...
AI-dataanalyytikko yhdistää perinteiset data-analyysin taidot tekoälyn (AI) ja koneoppimisen (ML) kanssa tuottaakseen oivalluksia, ennustaakseen trendejä ja par...
Anaconda on kattava, avoimen lähdekoodin Pythonin ja R:n jakelupaketti, joka on suunniteltu helpottamaan pakettien hallintaa ja käyttöönottoa tieteellisessä las...
BigML on koneoppimisalusta, joka on suunniteltu helpottamaan ennustemallien luomista ja käyttöönottoa. Vuonna 2011 perustetun alustan tavoitteena on tehdä koneo...
Datan puhdistus on keskeinen prosessi, jossa havaitaan ja korjataan virheet tai epäjohdonmukaisuudet datassa sen laadun parantamiseksi, varmistaen analytiikan j...
Ennustava mallinnus on edistynyt prosessi data-analytiikassa ja tilastotieteessä, jossa ennustetaan tulevia tapahtumia analysoimalla historiallisten tietojen ma...
Google Colaboratory (Google Colab) on Googlen tarjoama pilvipohjainen Jupyter-muistioalusta, jonka avulla käyttäjät voivat kirjoittaa ja suorittaa Python-koodia...
Gradient Boosting on tehokas koneoppimisen yhdistelmämenetelmä regressioon ja luokitukseen. Se rakentaa malleja peräkkäin, tyypillisesti päätöspuilla, optimoida...
Tutustu tekoälyn harhaan: ymmärrä sen lähteet, vaikutus koneoppimiseen, esimerkit tosielämästä sekä keinoja harhan vähentämiseen oikeudenmukaisten ja luotettavi...
Jupyter Notebook on avoimen lähdekoodin verkkosovellus, jonka avulla käyttäjät voivat luoda ja jakaa asiakirjoja, joissa on elävää koodia, yhtälöitä, visualisoi...
K-Means-klusterointi on suosittu valvomaton koneoppimisalgoritmi, jolla jaetaan aineisto ennalta määrättyyn määrään erillisiä, päällekkäisiä klustereita minimoi...
Kaggle on verkossa toimiva yhteisö ja alusta data-analyytikoille ja koneoppimisen insinööreille yhteistyöhön, oppimiseen, kilpailuihin osallistumiseen ja oivall...
Kausaalipäättely on menetelmällinen lähestymistapa, jonka avulla pyritään selvittämään syy-seuraussuhteita muuttujien välillä. Se on keskeinen tieteissä, kun ha...
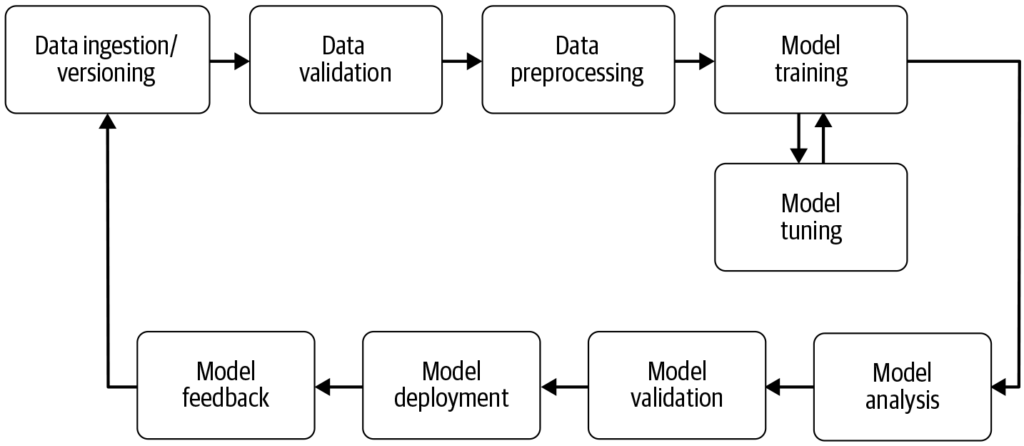
Koneoppimisen putki on automatisoitu työnkulku, joka virtaviivaistaa ja standardoi koneoppimismallien kehityksen, koulutuksen, arvioinnin ja käyttöönoton, muunt...
Käyrän alle jäävä pinta-ala (AUC) on koneoppimisessa keskeinen mittari, jolla arvioidaan binääriluokittelumallien suorituskykyä. Se mittaa mallin kokonaiskykyä ...
Lineaarinen regressio on tilastotieteen ja koneoppimisen keskeinen analyysimenetelmä, joka mallintaa riippuvien ja riippumattomien muuttujien välistä suhdetta. ...
Tekoälyluokittelija on koneoppimisalgoritmi, joka antaa syötteelle luokkia, eli jakaa tiedon ennalta määriteltyihin luokkiin opittujen mallien perusteella aiemm...
K-lähimmän naapurin (KNN) algoritmi on ei-parametrinen, valvotun oppimisen algoritmi, jota käytetään luokittelu- ja regressiotehtäviin koneoppimisessa. Se ennus...
Malliketjutus on koneoppimistekniikka, jossa useita malleja yhdistetään peräkkäin siten, että jokaisen mallin tuotos toimii seuraavan mallin syötteenä. Tämä läh...
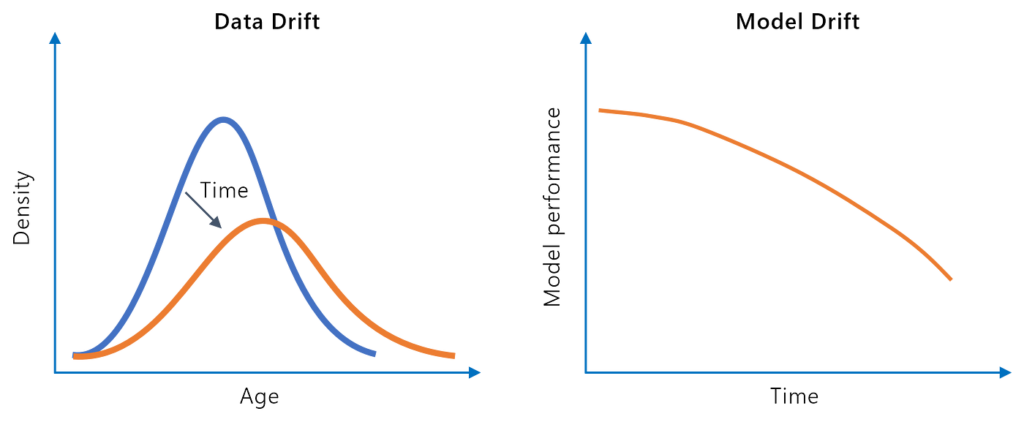
Mallin ajautuminen eli mallin rappeutuminen tarkoittaa koneoppimismallin ennustustarkkuuden heikkenemistä ajan myötä johtuen todellisen maailman ympäristön muut...
NumPy on avoimen lähdekoodin Python-kirjasto, joka on keskeinen numeerisessa laskennassa ja tarjoaa tehokkaat taulukko-operaatiot ja matemaattiset funktiot. Se ...
Oikaistu R-neliö on tilastollinen mittari, jota käytetään regressiomallin selitysasteen arviointiin. Se ottaa huomioon selittävien muuttujien määrän, jotta ylis...
Tutustu siihen, kuinka ominaisuusmuokkaus ja -poiminta parantavat tekoälymallien suorituskykyä muuttamalla raakadataa arvokkaiksi oivalluksiksi. Löydä keskeiset...
Pandas on avoimen lähdekoodin Python-kirjasto datan käsittelyyn ja analysointiin. Se tunnetaan monipuolisuudestaan, vahvoista tietorakenteistaan ja helppokäyttö...
Puolivalvottu oppiminen (SSL) on koneoppimistekniikka, joka hyödyntää sekä merkittyä että merkitsemätöntä dataa mallien kouluttamiseen. Tämä tekee siitä ihantee...
Päätöspuu on tehokas ja intuitiivinen työkalu päätöksenteon ja ennustavan analyysin tueksi, jota käytetään sekä luokittelu- että regressiotehtävissä. Sen puumai...
Scikit-learn on tehokas avoimen lähdekoodin koneoppimiskirjasto Pythonille, joka tarjoaa yksinkertaisia ja tehokkaita työkaluja ennakoivaan data-analyysiin. Laa...
Tietojen louhinta on kehittynyt prosessi, jossa analysoidaan laajoja raakadatan joukkoja tunnistaakseen kaavoja, suhteita ja oivalluksia, jotka voivat ohjata li...
Ulottuvuuden vähentäminen on keskeinen tekniikka datan käsittelyssä ja koneoppimisessa: se vähentää muuttujien määrää aineistossa säilyttäen olennaisen tiedon, ...