Vahvistusoppiminen (RL)
Vahvistusoppiminen (RL) on koneoppimisen menetelmä, jossa agentti oppii tekemään päätöksiä suorittamalla toimintoja ja saamalla palautetta. Palaute, joka voi ol...
2 min lukuaika
Reinforcement Learning
Machine Learning
+3
Vahvistusoppiminen (RL) on koneoppimisen menetelmä, jossa agentti oppii tekemään päätöksiä suorittamalla toimintoja ja saamalla palautetta. Palaute, joka voi ol...
Reinforcement Learning from Human Feedback (RLHF) eli vahvistusoppiminen ihmisen palautteella on koneoppimistekniikka, jossa ihmisen antamaa palautetta hyödynne...
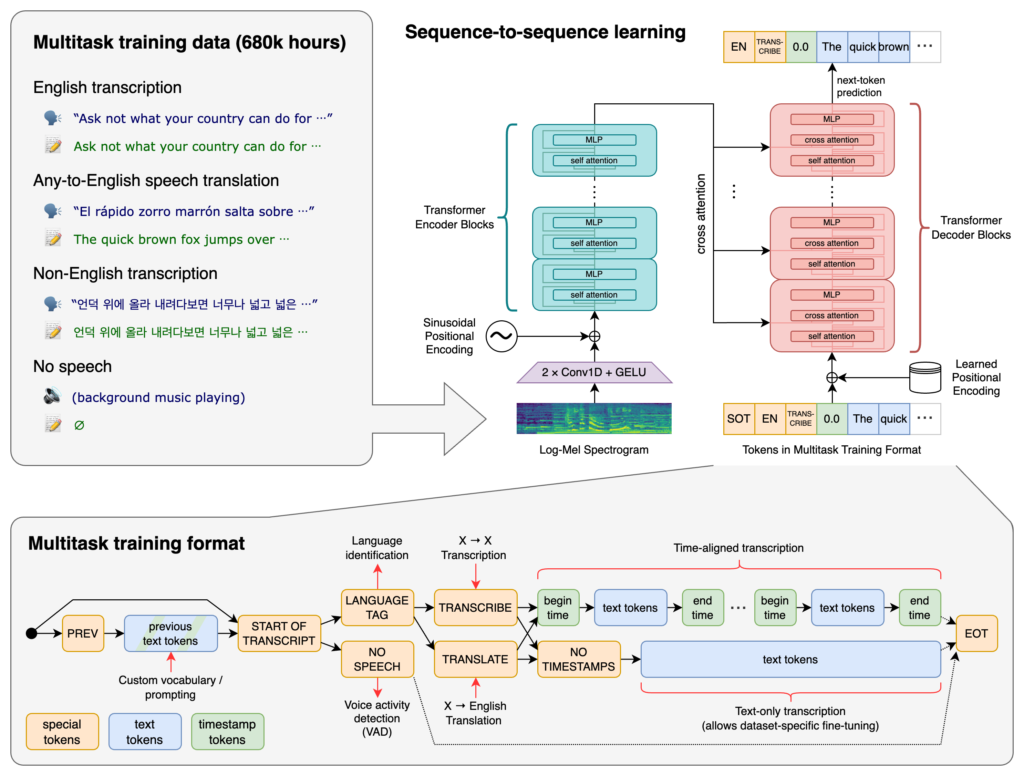
OpenAI Whisper on kehittynyt automaattinen puheentunnistusjärjestelmä (ASR), joka muuntaa puhutun kielen tekstiksi. Se tukee 99 kieltä, on kestävä aksenteille j...
Selitettävä tekoäly (XAI) on joukko menetelmiä ja prosesseja, joiden tavoitteena on tehdä tekoälymallien tuottamista tuloksista ymmärrettäviä ihmisille, edistäe...
XGBoost tarkoittaa Extreme Gradient Boostingia. Se on optimoitu, hajautettu gradient boosting -kirjasto, joka on suunniteltu koneoppimismallien tehokkaaseen ja ...
Yleistysvirhe mittaa, kuinka hyvin koneoppimismalli ennustaa ennennäkemätöntä dataa tasapainottaen harhaa ja varianssia, jotta tekoälysovellukset olisivat vahvo...
Ylisopeutus on keskeinen käsite tekoälyssä (AI) ja koneoppimisessa (ML), ja se tapahtuu, kun malli oppii harjoitusaineiston liian hyvin, mukaan lukien kohinan, ...
Opi tekoälyn intenttiluokittelun perusteet, sen tekniikat, käytännön sovellukset, haasteet ja tulevat trendit ihmisen ja koneen vuorovaikutuksen parantamisessa....
Tutustu tekoälyn päättelyn perusteisiin, mukaan lukien sen tyypit, merkitys ja todelliset sovellukset. Opi, miten tekoäly jäljittelee ihmisen ajattelua, paranta...
Zero-Shot Learning on tekoälymenetelmä, jossa malli tunnistaa objekteja tai tietoluokkia ilman, että sitä on erikseen opetettu näille luokille, hyödyntäen seman...
Älykäs agentti on autonominen olio, joka on suunniteltu havaitsemaan ympäristönsä sensoreiden avulla ja vaikuttamaan siihen toimilaitteiden kautta, varustettuna...
Näytetään 201 – 211 / 211 tulosta