Description du flux
Objectif et avantages
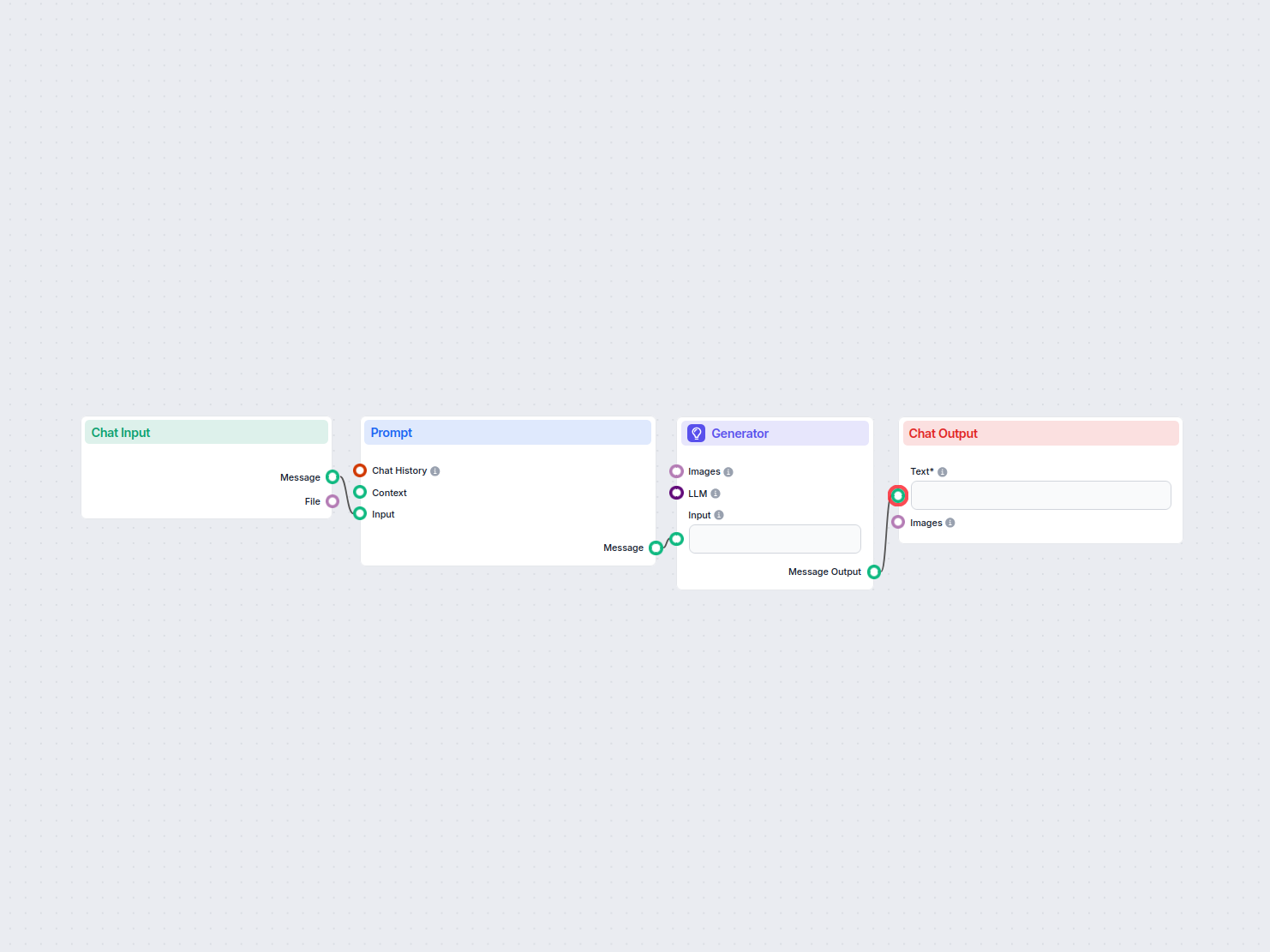
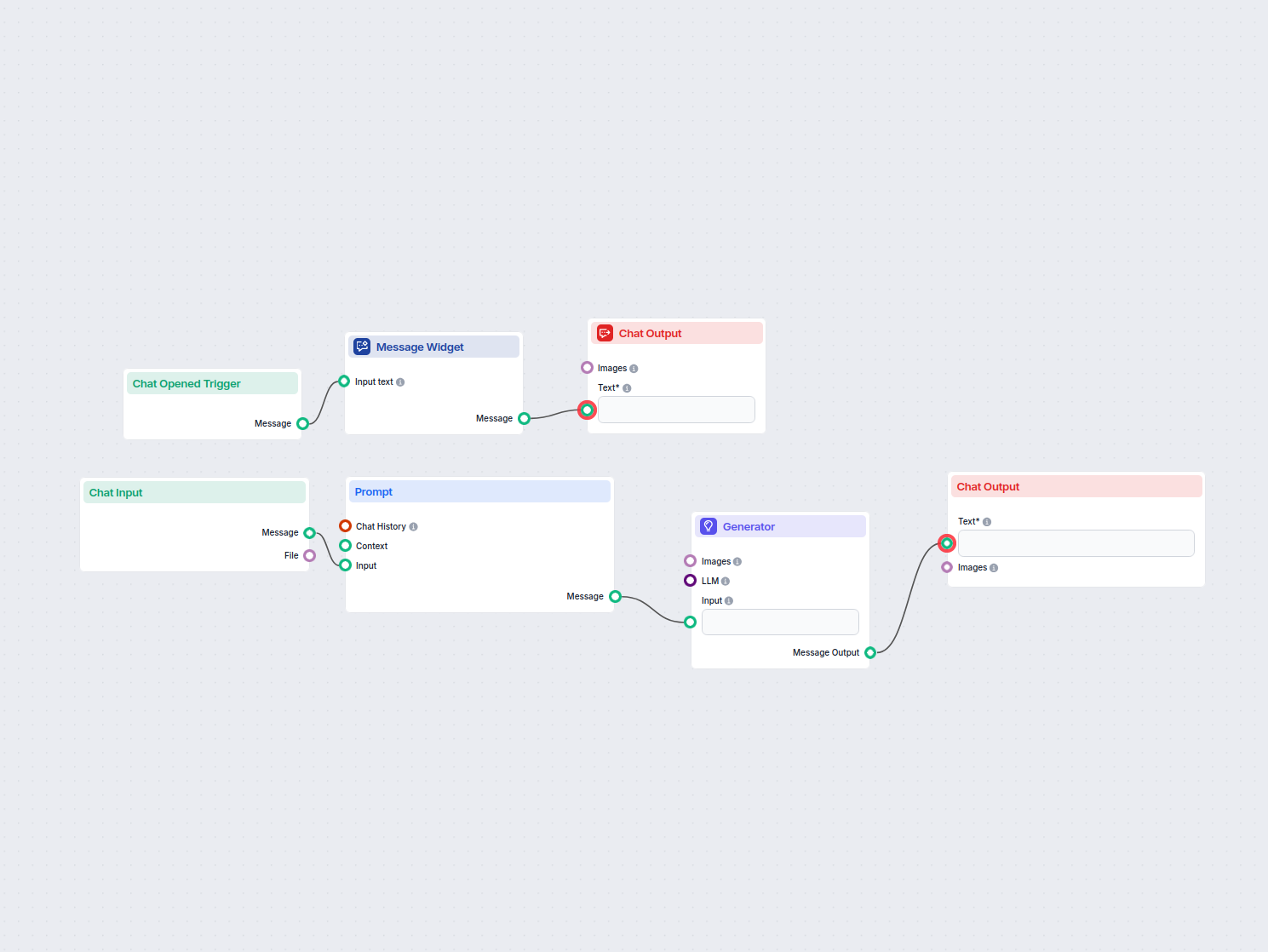
Vue d’ensemble du workflow : Traductions pour les projets HUGO
Ce workflow est conçu pour automatiser la traduction des fichiers markdown utilisés dans les projets HUGO, avec une attention particulière à la préservation de la structure et du formatage des fichiers. Le flux garantit que seuls les contenus textuels pertinents sont traduits, tandis que les éléments techniques comme le front matter, la structure markdown et les caractères de contrôle restent intacts. Ceci est particulièrement utile pour les équipes qui gèrent des sites statiques multilingues construits avec HUGO et qui souhaitent scaler la localisation du contenu tout en maintenant une haute qualité et une cohérence optimale.
Objectif et utilité
- Traduction automatisée : Le workflow utilise des modèles linguistiques de pointe (variantes GPT-4 d’OpenAI) pour fournir des traductions de haute qualité pour les fichiers markdown.
- Préservation de la structure : Il maintient soigneusement la structure des fichiers markdown HUGO, y compris le front matter au format TOML, les titres markdown et le formatage spécifique.
- Traduction sélective : Le flux est conçu pour éviter de traduire les noms de champs dans le front matter ou le texte à l’intérieur des balises HTML, en se concentrant uniquement sur les valeurs de champ et le contenu markdown.
- Localisation à grande échelle : En automatisant le processus de traduction, ce workflow permet de scaler rapidement vers plusieurs langues avec un minimum d’effort manuel.
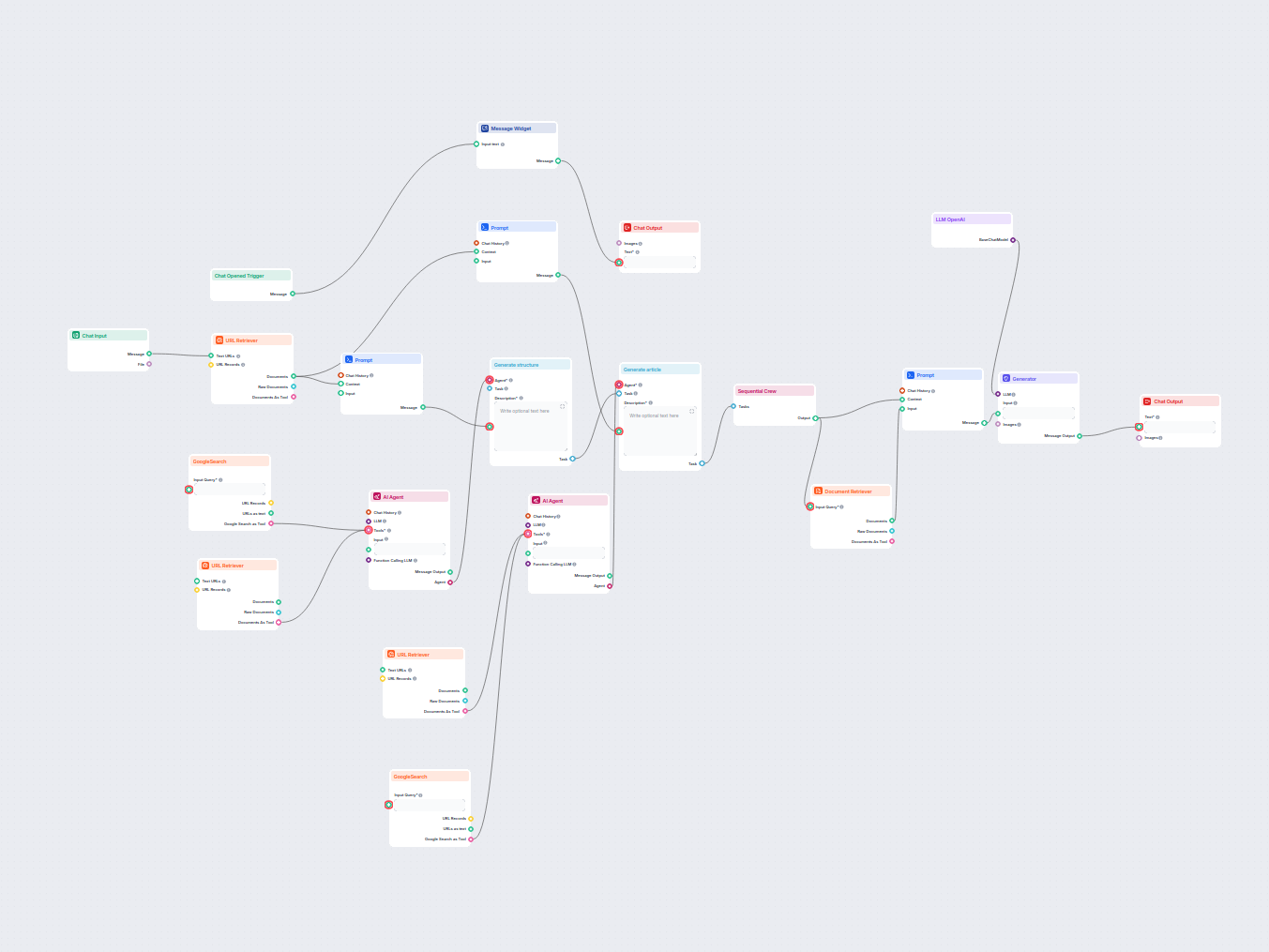
Étapes clés du workflow
Le workflow se compose de plusieurs composants interconnectés. Voici un aperçu étape par étape :
| Étape | Composant | Fonction |
|---|
| 1 | Chat Input | Accepte le fichier markdown à traduire ainsi que les variables requises (ex : langue cible). |
| 2 | Prompt Template (input var) | Extrait le nom de la langue de destination à partir des variables d’entrée pour un usage ultérieur. |
| 3 | LLM OpenAI (nano) | Utilise un modèle GPT-4 léger pour traiter les prompts. |
| 4 | Generator (get language name) | Génère le nom de la langue de destination à partir des variables fournies. |
| 5 | Document Retriever (GetBestTranslation) | Recherche les meilleures traductions existantes ou du contexte dans des sources internes/documentaires. |
| 6 | Prompt Template (Prompt) | Crée un prompt détaillé indiquant au LLM comment traduire, avec restrictions et exemples. |
| 7 | LLM OpenAI (full) | Utilise un modèle GPT-4 complet (avec large contexte) pour effectuer la traduction. |
| 8 | Generator | Exécute la traduction à l’aide du prompt et du modèle ci-dessus. |
| 9 | Chat Output | Affiche le fichier markdown traduit dans l’interface de sortie. |
Logique détaillée du workflow
- Gestion des entrées : L’utilisateur soumet un fichier markdown et spécifie la langue cible. Le workflow extrait les variables pertinentes pour les utiliser dans les prompts.
- Extraction de la langue : La première partie du workflow détermine le nom de la langue cible à partir des entrées grâce à un LLM léger et un prompt personnalisé.
- Récupération contextuelle : Il récupère éventuellement des traductions existantes ou de la documentation pertinente afin d’apporter du contexte supplémentaire et d’assurer la cohérence de la traduction.
- Construction du prompt de traduction : Un prompt complet est construit, détaillant les règles de formatage, les restrictions de traduction et les attentes concernant la structure du fichier. Un exemple de structure de fichier est fourni au modèle, avec des instructions strictes sur ce qu’il faut traduire et préserver.
- Génération de la traduction : La traduction principale est réalisée à l’aide d’un LLM performant, garantissant une sortie de haute qualité tout en respectant rigoureusement les exigences de formatage et de structure.
- Sortie : Le fichier markdown traduit est présenté pour relecture utilisateur ou un traitement automatisé complémentaire.
Pourquoi ce workflow est utile
- Cohérence : Garantit que tous les fichiers traduits suivent les directives strictes de formatage et de structure requises par les projets HUGO.
- Efficacité : Réduit considérablement l’effort manuel lié à la traduction et à la mise en forme des fichiers markdown pour les générateurs de sites statiques.
- Scalabilité : Permet un passage facile à de multiples langues et à de gros volumes de contenu.
- Contrôle qualité : En utilisant à la fois une récupération contextuelle et des instructions de traduction explicites, il minimise les erreurs typiques des approches naïves de traduction automatique.
Considérations particulières
- Règles spécifiques aux champs : Le workflow prend soin de ne traduire que les valeurs des champs dans le front matter, jamais les noms de champs ni les éléments structurants.
- Intégrité du formatage : Les caractères de contrôle comme
+ + + ainsi que les éléments markdown/HTML sont préservés selon les spécifications HUGO et TOML. - Extensibilité : L’approche modulaire (avec récupérateurs, modèles de prompts et générateurs) permet une adaptation facile à l’évolution des besoins.
En résumé, ce workflow fournit une solution complète, fiable et scalable pour la traduction de fichiers markdown HUGO, ce qui le rend particulièrement précieux pour les organisations gérant des sites statiques multilingues ou des projets de documentation.