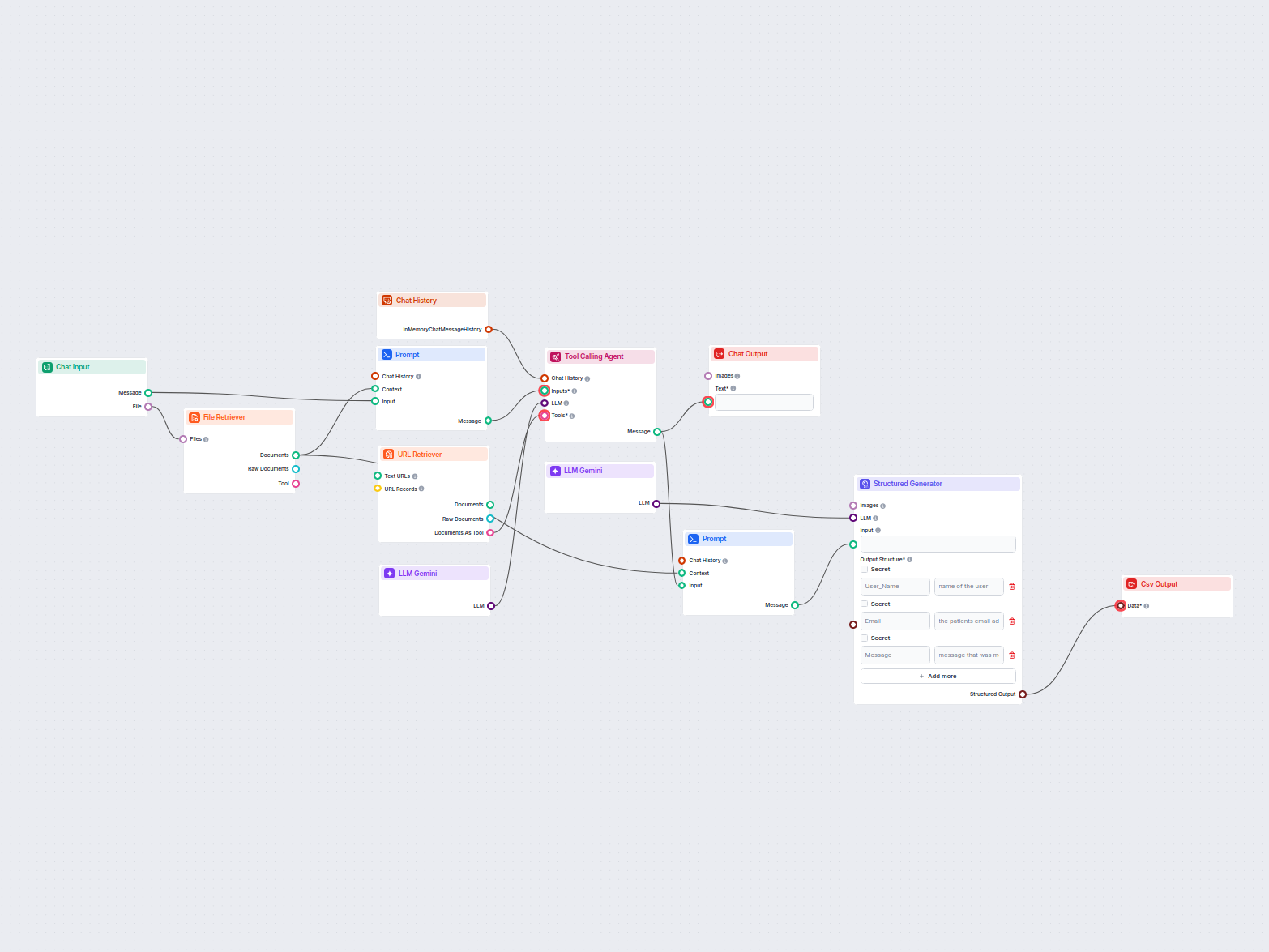
Extraction des données d'e-mails & fichiers vers CSV
Ce workflow extrait et organise les informations clés provenant d'e-mails et de fichiers joints, utilise l'IA pour traiter et structurer les données, puis expor...
4 min de lecture
Pour vous aider à démarrer rapidement, nous avons préparé plusieurs exemples de modèles de flux qui démontrent comment utiliser efficacement le composant Urlcontent. Ces modèles présentent différents cas d'utilisation et meilleures pratiques, facilitant votre compréhension et l'implémentation du composant dans vos propres projets.
Ce workflow extrait et organise les informations clés provenant d'e-mails et de fichiers joints, utilise l'IA pour traiter et structurer les données, puis expor...
Nous aidons les entreprises comme la vôtre à développer des chatbots intelligents, des serveurs MCP, des outils d'IA ou d'autres types d'automatisation par IA pour remplacer l'humain dans les tâches répétitives de votre organisation.