Optimiseur de titres d'articles SEO
Optimisez automatiquement les titres et en-têtes de vos articles pour un mot-clé ou un cluster de mots-clés spécifique afin d'améliorer la performance SEO. Ce w...
4 min de lecture
Le Récupérateur d’URL vous permet de récupérer et de traiter du contenu à partir de liens web, en prenant en charge l’OCR, l’extraction de métadonnées et une sortie flexible pour alimenter vos flux de travail IA.
Description du composant
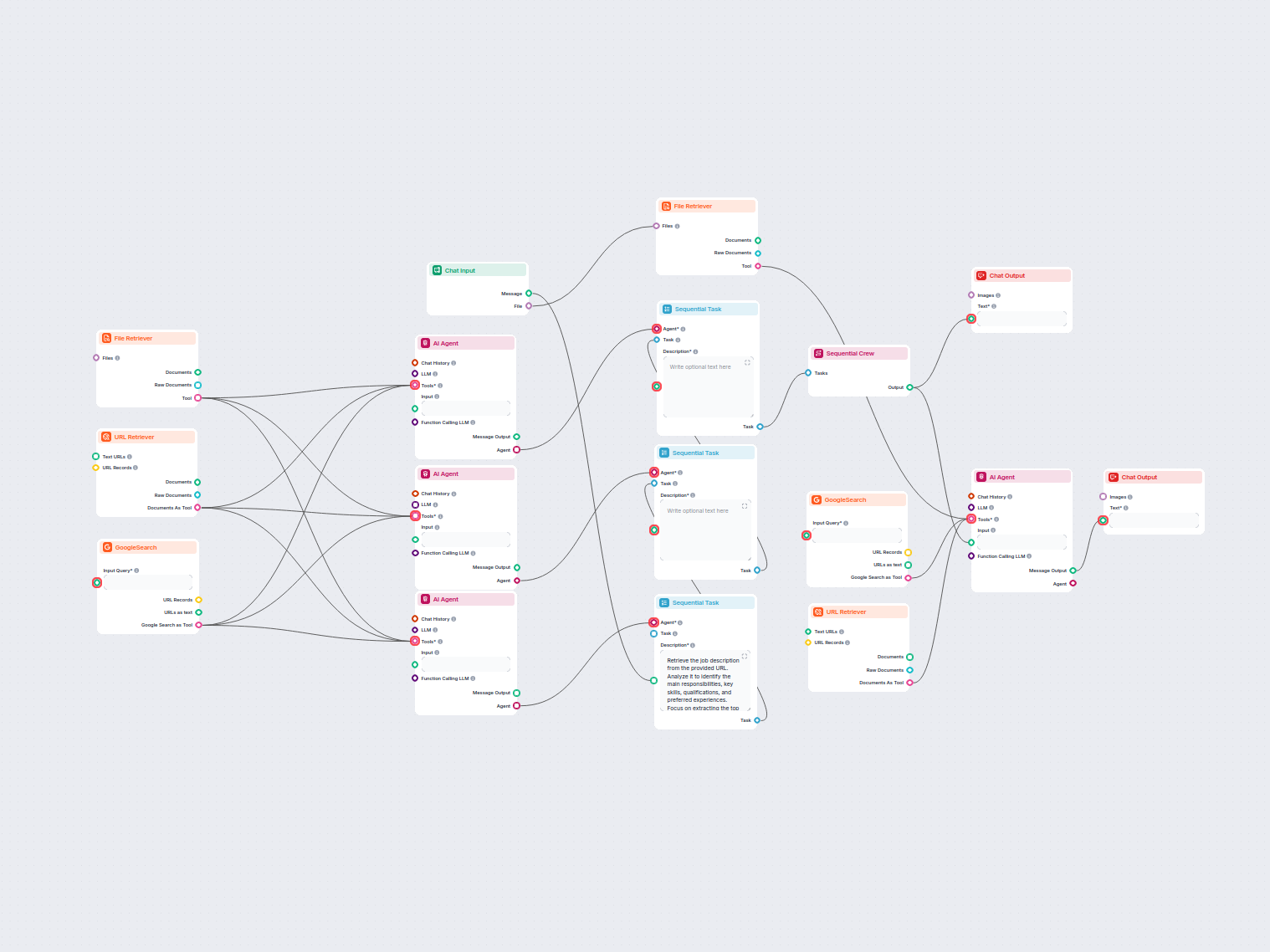
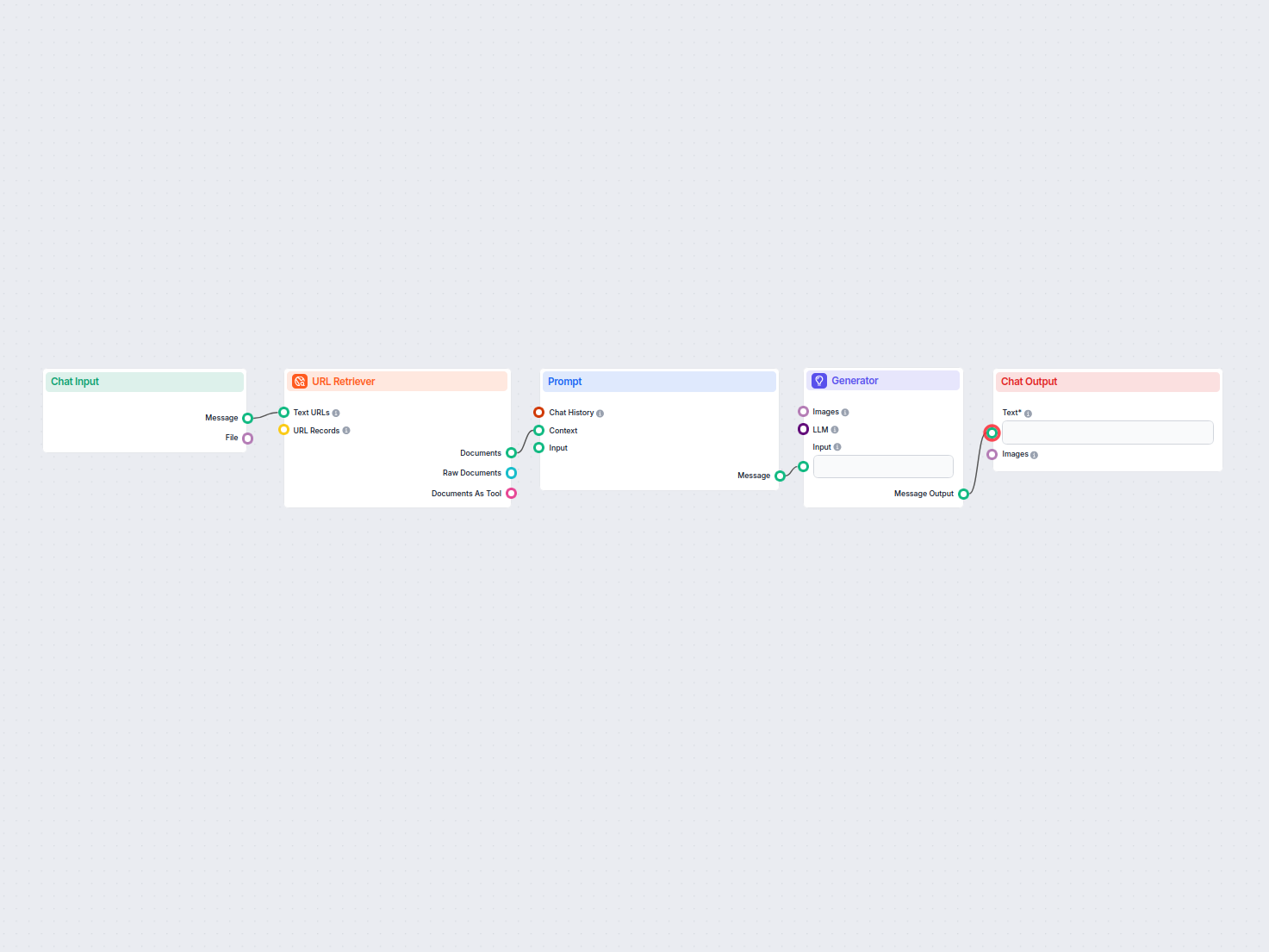
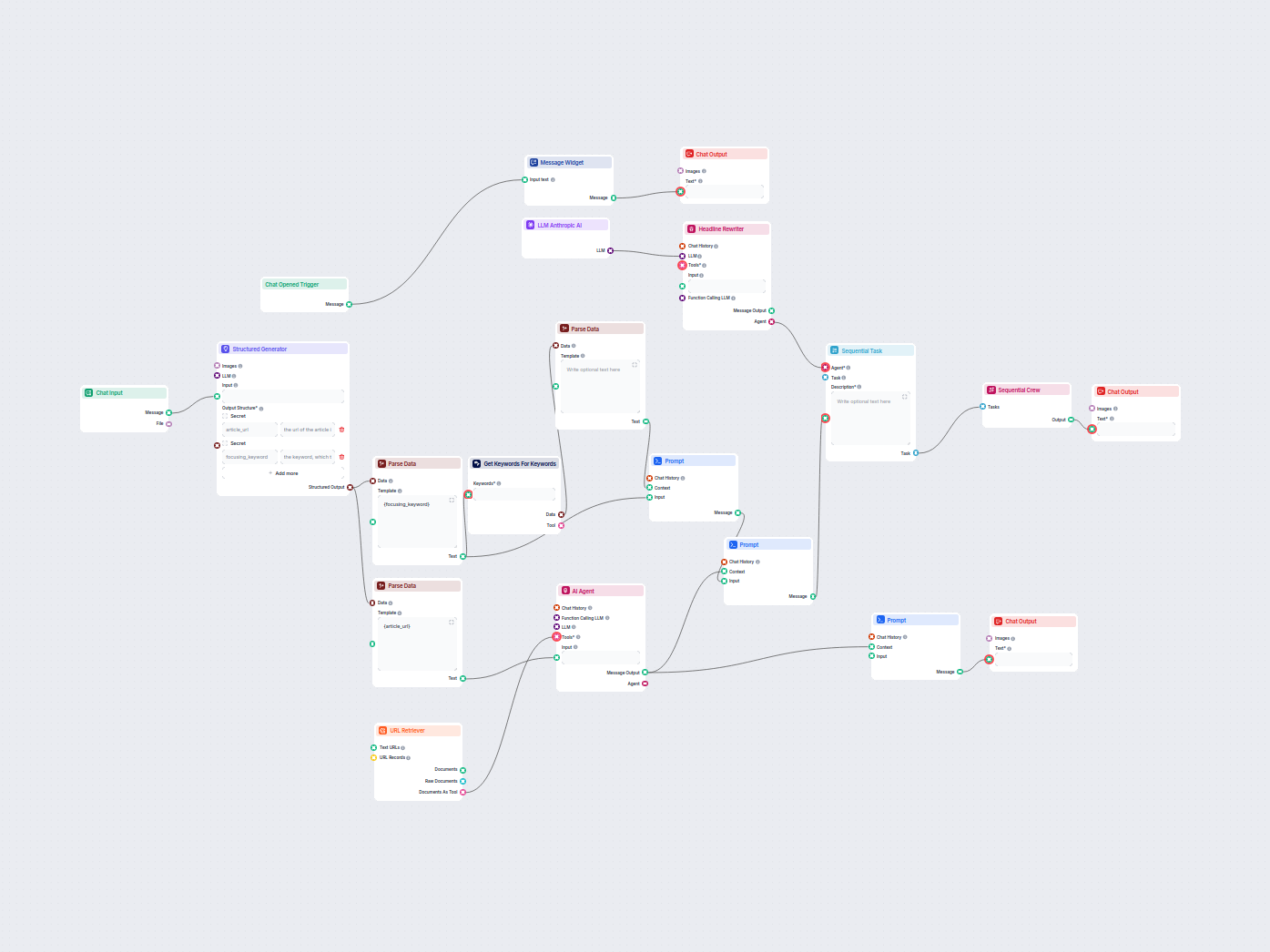
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
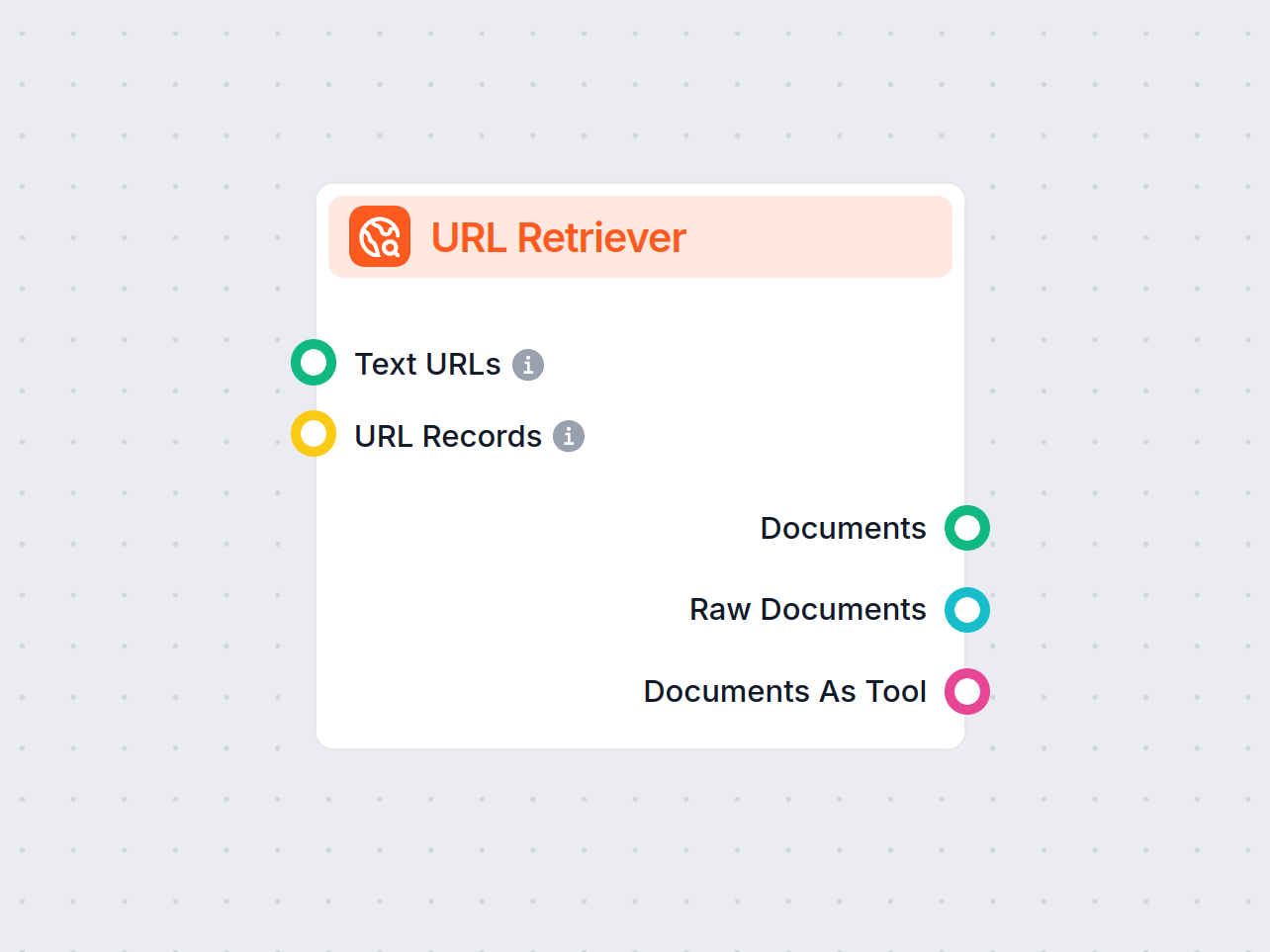
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Pour vous aider à démarrer rapidement, nous avons préparé plusieurs exemples de modèles de flux qui démontrent comment utiliser efficacement le composant Récupérateur d'URL. Ces modèles présentent différents cas d'utilisation et meilleures pratiques, facilitant votre compréhension et l'implémentation du composant dans vos propres projets.
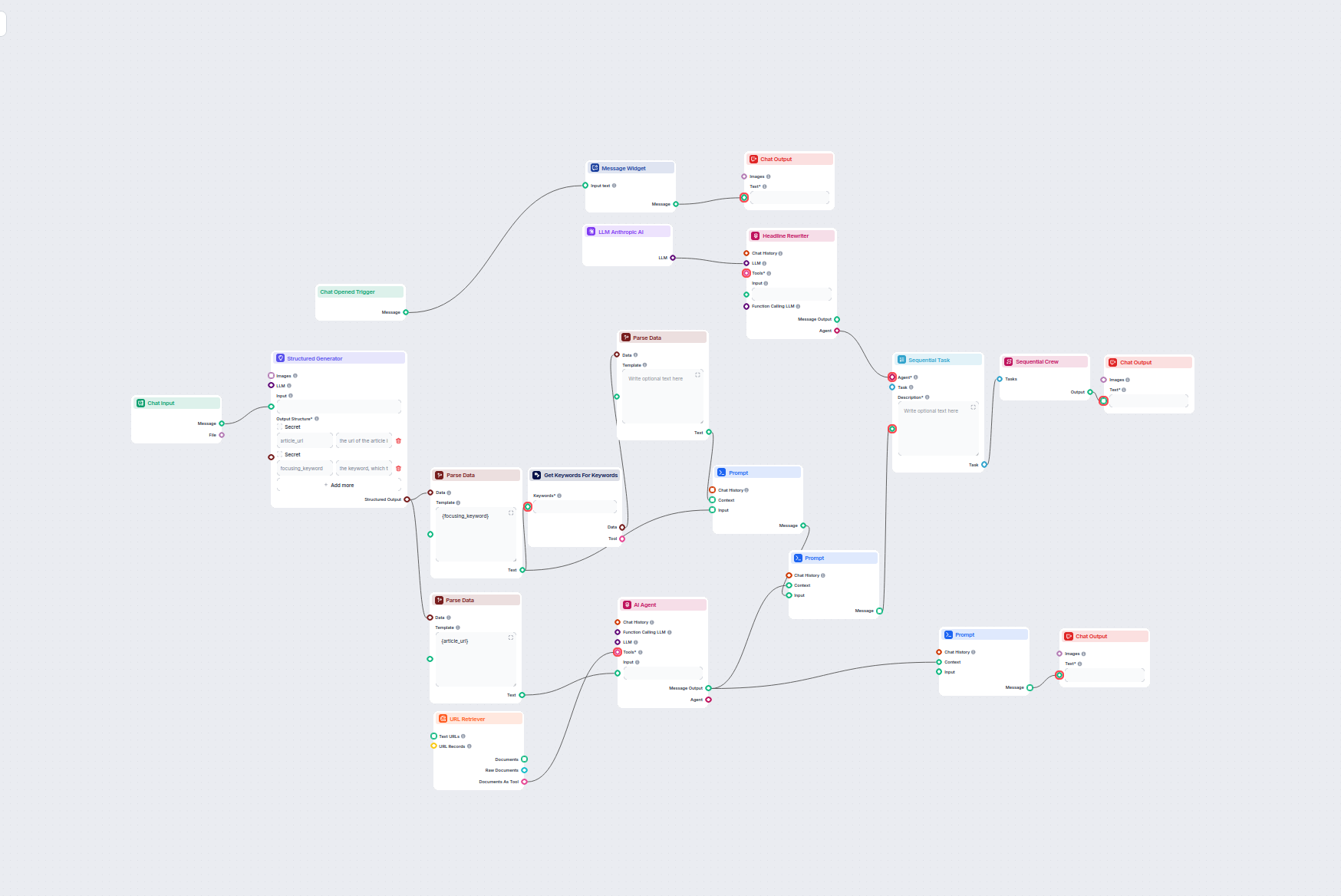
Optimisez automatiquement les titres et en-têtes de vos articles pour un mot-clé ou un cluster de mots-clés spécifique afin d'améliorer la performance SEO. Ce w...
Ce flux de travail alimenté par l'IA identifie les meilleurs mots-clés SEO pour votre article de blog et réécrit automatiquement les titres afin de cibler ces m...
Ce flux de travail propulsé par l'IA simplifie le processus d'adaptation du CV d'un utilisateur à une offre d'emploi spécifique. En analysant à la fois le CV or...
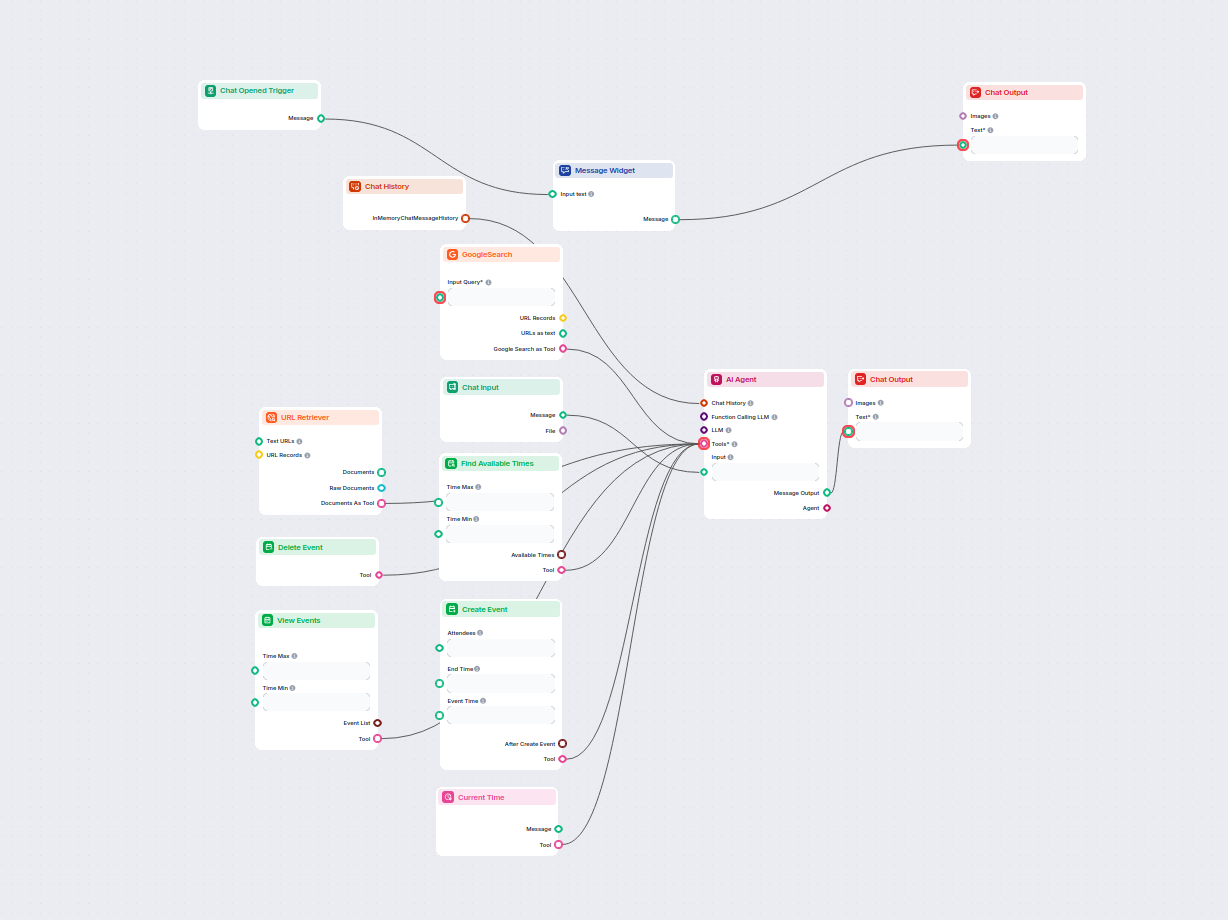
Ce flux de travail alimenté par l'IA automatise la planification des réunions via Google Agenda. Les utilisateurs interagissent avec un chatbot qui trouve des c...
Crée automatiquement une méta description engageante et optimisée pour le SEO pour toute page web, PDF, vidéo YouTube ou lien de document en analysant son conte...
Générez rapidement des résumés concis de n'importe quelle page web en fournissant simplement une URL. Ce workflow alimenté par l'IA récupère le contenu du lien ...
Automatisez le support client dans LiveAgent avec un chatbot IA qui répond aux questions en utilisant votre base de connaissances interne, récupère les document...
Transforme automatiquement le contenu de toute URL fournie en une publication concise et engageante adaptée à X (Twitter), aidant les marketeurs et créateurs à ...
Affichage 61 à 68 de 68 résultats
Le Récupérateur d'URL récupère et traite le contenu de liens web spécifiés, rendant le texte et les métadonnées de documents en ligne disponibles pour votre flux de travail ou agent IA.
Oui, en activant l'option OCR, le composant peut extraire le texte de documents basés sur des images ou des PDF scannés.
Il fournit les documents traités sous forme de messages texte, d'objets document bruts ou comme outil pour des flux de travail d'agent, selon votre configuration.
Vous pouvez définir la durée de mise en cache du contenu récupéré, réduisant ainsi les téléchargements répétés et accélérant vos flux.
Oui, vous pouvez spécifier quels titres, paragraphes ou champs de métadonnées inclure dans la sortie, permettant une extraction ciblée.
Absolument. Le Récupérateur d'URL est essentiel pour toute automatisation ou chatbot ayant besoin de lire, traiter ou résumer du contenu web en direct.
Boostez vos flux de travail en intégrant du contenu web en direct. Extrayez, traitez et exploitez des données depuis des URL en toute simplicité.
Intégrez vos flux de travail avec Google Docs grâce au composant Récupérateur Google Docs—récupérez sans effort le contenu de vos documents pour l'utiliser dans...
Le composant Récupérateur de fichiers dans FlowHunt vous permet d'intégrer des fichiers dans votre flux de travail et de les convertir en documents pour un trai...
Capturez instantanément des instantanés de sites web avec le composant Outil de capture d'écran. Automatisez facilement la prise de captures d'écran de n'import...