Aussi puissante soit-elle, l’IA reste une machine qui relaie les informations qu’elle apprend. Elle ne comprend pas les blagues, les hypothèses ou le sarcasme, qui sont souvent à l’origine des réponses les plus hilarantes (et parfois sérieusement problématiques). Pour éviter que votre chatbot ne crée le prochain scandale de l’IA et pour l’aider à mieux comprendre votre contenu, vous pouvez lui indiquer quel contenu ignorer.
La fiabilité de l’IA repose sur la surveillance des informations dont elle s’inspire. Tout votre contenu ne sera pas adapté à l’utilisation par le chatbot. La classe flowhunt-skip vous permet de marquer le contenu que FlowHunt ne doit pas indexer. Tout élément HTML portant cette classe sera ignoré lors du traitement du contenu.
Quand utiliser le paramètre d’ignorance
Il y a deux principales raisons d’utiliser cette classe, mais n’hésitez pas à l’appliquer à tout contenu que vous jugez inutile ou inadapté à l’usage du bot.
Ignorer le contenu répétitif : Si un contenu similaire est constamment indexé, cela complique la tâche de l’IA pour distinguer et catégoriser le sujet traité. Ignorer les informations en double vous fait également économiser sur le traitement du texte à long terme.
Ignorer les informations risquées ou inappropriées : Vous devriez ignorer toute information susceptible d’amener l’IA à fournir des réponses fausses, nuisibles ou hors contexte. Soyez particulièrement vigilant si le ton de votre marque utilise souvent l’humour ou un langage fort. Même si cela fonctionne pour d’autres contenus, les utilisateurs risquent de ne pas apprécier un bot sarcastique.
Comment utiliser le paramètre flowhunt-skip
FlowHunt explore et indexe votre site web afin de fournir du contexte au chatbot. Tout ce que FlowHunt indexe pourra éventuellement être utilisé par votre chatbot.
En ajoutant la classe flowhunt-skip aux éléments HTML, vous marquez le contenu que vous ne souhaitez pas indexer. Tout élément portant cette classe sera ignoré et n’atteindra jamais le chatbot.
Voici un exemple d’utilisation de la classe :
<div class="flowhunt-skip">
<h2>Duplicit content</h2>
<p>This content is duplicate. I don’t want FlowHunt to index it again.</p>
</div>
Vous pouvez aussi ignorer un seul paragraphe ou une partie d’un élément :
<div>
<h2>My content</h2>
<p>This paragraph should be indexed.</p>
<p class="flowhunt-skip">I don't want the Chatbot to use this information.</p>
<p>This paragraph should be indexed.</p>
</div>
Prêt à développer votre entreprise?
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Comment fonctionne l’indexation
Le processus d’exploration s’exécute en arrière-plan selon les horaires que vous définissez. Il télécharge uniquement la page HTML. Toutes les images ou médias sont simplement stockés sous forme de liens. Les redirections sont suivies, et les URLs canoniques sont évaluées.
Une fois le crawl effectué, le contenu HTML est converti en texte markdown brut. Certaines informations peuvent être supprimées durant ce processus. Le texte markdown final est proposé au chatbot comme contexte. Le bot peut ensuite récupérer cette information à tout moment si nécessaire.
Comment l’IA choisit-elle les informations à utiliser
Le texte markdown est divisé en segments, vectorisé et stocké dans une base de données vectorielle. Ce type de base de données attribue des valeurs aux significations des mots. Ainsi, l’IA peut comprendre les mots liés sans avoir besoin d’une correspondance exacte.
Les mots sont répartis sur une grille selon leur valeur attribuée. Cela permet à l’ordinateur de comprendre quels mots sont proches par leur sens :
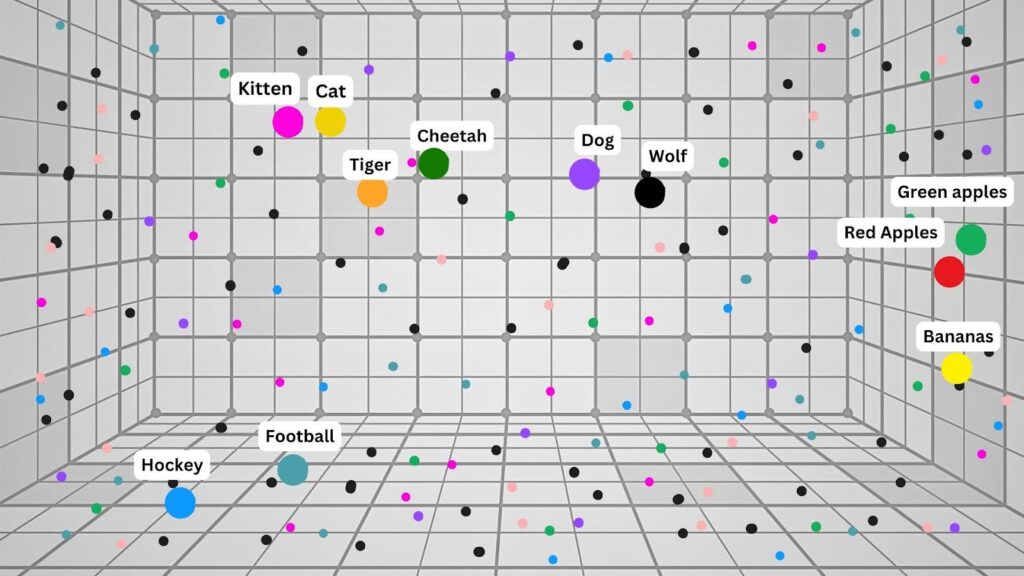
Remarque : Il s’agit d’un modèle très simplifié. En pratique, l’IA effectue ce travail avec des milliers de mots, d’expressions et de phrases entières.
La récupération d’informations depuis les bases de données vectorielles s’appelle la recherche sémantique. C’est la capacité de l’IA à rechercher et évaluer le sens des mots dans la base de données vectorielle afin de fournir des réponses.
Lorsqu’un utilisateur soumet une requête, le bot convertit les mots en vecteurs. Il recherche ensuite dans la base de données toutes les correspondances proches issues de votre contenu. En trouvant des correspondances ou du contenu similaire, il utilise alors ces informations pour formuler une réponse.
Rejoignez notre newsletter
Recevez gratuitement les derniers conseils, tendances et offres.
Pourquoi la recherche sémantique est-elle si importante
Imaginez que vous possédiez une animalerie en ligne. Un client pose la question suivante :
« Vendez-vous de la nourriture pour chatons ? »
Vous en vendez, mais le nom du produit comprend le mot “junior” au lieu de “chaton”. Le bot sera capable de comprendre que “nourriture pour chats junior” est la même chose (ou très similaire) que “nourriture pour chatons” et orientera avec succès le client vers le bon produit.
Sans recherche sémantique dans la base de données vectorielle, le chatbot se contenterait de répondre que vous ne proposez pas de “nourriture pour chatons”, vous faisant ainsi perdre un client potentiel. Avec FlowHunt, vous n’avez pas à vous soucier de ce genre de situation.