Serveur MCP Pinecone Assistant
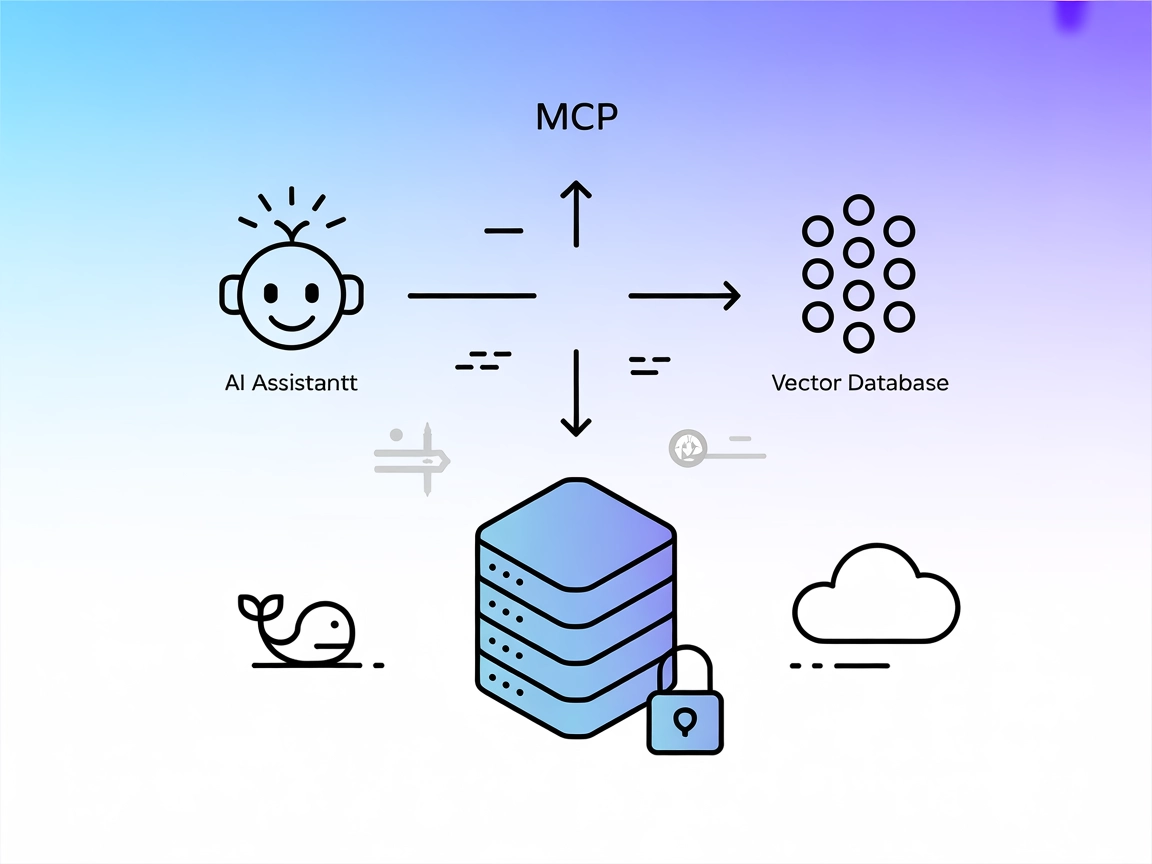
Le serveur MCP Pinecone Assistant fait le lien entre les assistants IA et la base de données vectorielle de Pinecone, permettant la recherche sémantique, la réc...
4 min de lecture
AI
MCP Server
+5

Connectez FlowHunt à Pinecone pour une recherche sémantique avancée, la gestion de données vectorielles et des applications IA propulsées par RAG.
FlowHunt fournit une couche de sécurité supplémentaire entre vos systèmes internes et les outils d'IA, vous donnant un contrôle granulaire sur les outils accessibles depuis vos serveurs MCP. Les serveurs MCP hébergés dans notre infrastructure peuvent être intégrés de manière transparente avec le chatbot de FlowHunt ainsi qu'avec les plateformes d'IA populaires comme ChatGPT, Claude et divers éditeurs d'IA.
Le serveur MCP (Model Context Protocol) Pinecone est un outil spécialisé qui connecte les assistants IA aux bases de données vectorielles Pinecone, permettant une lecture et une écriture de données sans friction pour des flux de développement avancés. Servant d’intermédiaire, le serveur MCP Pinecone permet aux clients IA d’exécuter des tâches telles que la recherche sémantique, la récupération de documents et la gestion de base de données à l’intérieur d’un index Pinecone. Il prend en charge des opérations comme la requête pour des enregistrements similaires, la gestion de documents et l’insertion de nouveaux embeddings. Cette capacité est particulièrement précieuse pour les applications de génération augmentée par la récupération (RAG), car elle fluidifie l’intégration de données contextuelles dans les flux IA et automatise des interactions complexes avec les données.
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Recevez gratuitement les derniers conseils, tendances et offres.
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
Sécurisation des clés API avec des variables d’environnement :
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"env": {
"PINECONE_API_KEY": "votre_clé_api"
},
"inputs": {
"index_name": "votre_index"
}
}
}
}
pip install mcp-pinecone).{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
Remarque : Sécurisez toujours vos clés API et valeurs sensibles via les variables d’environnement comme ci-dessus.
Utilisation du MCP dans FlowHunt
Pour intégrer des serveurs MCP dans votre flux de travail FlowHunt, commencez par ajouter le composant MCP à votre flux et reliez-le à votre agent IA :

Cliquez sur le composant MCP pour ouvrir le panneau de configuration. Dans la section de configuration système MCP, insérez les détails de votre serveur MCP au format JSON suivant :
{
"pinecone-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Une fois configuré, l’agent IA peut désormais utiliser ce MCP comme outil avec accès à toutes ses fonctions et capacités. Pensez à remplacer “pinecone-mcp” par le nom réel de votre serveur MCP et à renseigner l’URL de votre propre serveur MCP.
| Section | Disponibilité | Détails/Notes |
|---|---|---|
| Vue d’ensemble | ✅ | Décrit l’intégration de la base vectorielle Pinecone MCP |
| Liste des prompts | ⛔ | Aucun modèle de prompt explicite trouvé |
| Liste des ressources | ✅ | Index Pinecone, documents, enregistrements, statistiques |
| Liste des outils | ✅ | semantic-search, read-document, list-documents, pinecone-stats, process-document |
| Sécurisation des clés API | ✅ | Exemple fourni avec variables d’environnement dans la configuration |
| Prise en charge de l’échantillonnage | ⛔ | Aucun mention ou preuve trouvée |
Le serveur MCP Pinecone est bien documenté, expose clairement ses ressources et outils, et inclut des instructions solides pour l’intégration et la sécurité des clés API. Cependant, il manque de modèles de prompt explicites et de documentation sur l’échantillonnage ou la prise en charge des racines. Globalement, c’est un serveur pratique et précieux pour les flux RAG et Pinecone, bien qu’il pourrait être amélioré par plus d’exemples de workflow et de fonctionnalités avancées.
Note : 8/10
| Dispose d’une LICENCE | ✅ (MIT) |
|---|---|
| Dispose d’au moins un outil | ✅ |
| Nombre de forks | 25 |
| Nombre d’étoiles | 124 |
Le serveur MCP Pinecone connecte les assistants IA aux bases de données vectorielles Pinecone, permettant la recherche sémantique, la gestion documentaire et l'intégration des embeddings dans les applications IA comme FlowHunt.
Il propose des outils pour la recherche sémantique, la lecture et la liste des documents, la récupération des statistiques de l'index et le traitement de documents en embeddings pour les insérer dans l'index Pinecone.
Le serveur permet aux agents IA de récupérer le contexte pertinent depuis Pinecone, permettant aux LLM de générer des réponses ancrées dans des sources de connaissances externes.
Stockez votre clé API Pinecone et le nom de l'index sous forme de variables d'environnement dans votre fichier de configuration, comme indiqué dans les instructions d'intégration, afin de garder vos identifiants en sécurité.
Les cas d'utilisation courants incluent la recherche sémantique sur de grandes collections de documents, les pipelines RAG, le découpage et l'embedding automatique de documents, et la surveillance des statistiques d'index Pinecone.
Activez la recherche sémantique et la génération augmentée par la récupération dans FlowHunt en connectant vos agents IA aux bases de données vectorielles Pinecone.
Le serveur MCP Pinecone Assistant fait le lien entre les assistants IA et la base de données vectorielle de Pinecone, permettant la recherche sémantique, la réc...

Intégrez FlowHunt avec le serveur Pinecone Model Context Protocol (MCP) pour une recherche vectorielle pilotée par l’IA, un traitement documentaire et une gesti...

Le serveur Teradata MCP intègre des assistants IA aux bases de données Teradata, permettant des analyses avancées, l’exécution transparente de requêtes SQL et d...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.