Intégration du serveur Neo4j MCP
Le serveur Neo4j MCP fait le lien entre les assistants IA et la base de données graphique Neo4j, permettant des opérations sur le graphe, des requêtes Cypher et...
5 min de lecture
AI
Graph Database
+5
Le serveur Neo4j MCP fait le lien entre les assistants IA et la base de données graphique Neo4j, permettant des opérations sur le graphe, des requêtes Cypher et...
Le serveur MCP de la NASA offre une interface unifiée pour les modèles d'IA et les développeurs afin d'accéder à plus de 20 sources de données de la NASA. Il st...
Reexpress MCP Server apporte la vérification statistique aux flux de travail LLM. Utilisant l’estimateur Similarity-Distance-Magnitude (SDM), il délivre des est...
Le serveur MCP Code Executor permet à FlowHunt et à d'autres outils pilotés par des LLM d'exécuter en toute sécurité du code Python dans des environnements isol...
Le serveur MCP d’Exploration de Données connecte les assistants IA à des jeux de données externes pour une analyse interactive. Il permet aux utilisateurs d’exp...
JupyterMCP permet une intégration transparente de Jupyter Notebook (6.x) avec des assistants IA via le Model Context Protocol. Automatisez l'exécution du code, ...
Le serveur MCP Databricks Genie permet aux grands modèles de langage d'interagir avec les environnements Databricks via l'API Genie, prenant en charge l'explora...
L'Aire Sous la Courbe (AUC) est une métrique fondamentale en apprentissage automatique utilisée pour évaluer la performance des modèles de classification binair...
Un Analyste de Données IA associe les compétences d’analyse de données traditionnelles à l’intelligence artificielle (IA) et au machine learning (ML) afin d’ext...
L'apprentissage semi-supervisé (SSL) est une technique d'apprentissage automatique qui exploite à la fois des données étiquetées et non étiquetées pour entraîne...
Un arbre de décision est un outil puissant et intuitif pour la prise de décision et l'analyse prédictive, utilisé à la fois pour les tâches de classification et...
Explorez le biais en IA : comprenez ses sources, son impact sur l'apprentissage automatique, des exemples concrets et des stratégies d'atténuation pour créer de...
Anaconda est une distribution complète et open source de Python et R, conçue pour simplifier la gestion des paquets et le déploiement pour le calcul scientifiqu...
BigML est une plateforme de machine learning conçue pour simplifier la création et le déploiement de modèles prédictifs. Fondée en 2011, sa mission est de rendr...
Le chaînage de modèles est une technique d'apprentissage automatique où plusieurs modèles sont liés de manière séquentielle, la sortie de chaque modèle servant ...
Un classificateur IA est un algorithme d'apprentissage automatique qui attribue des étiquettes de classe aux données d'entrée, en catégorisant les informations ...
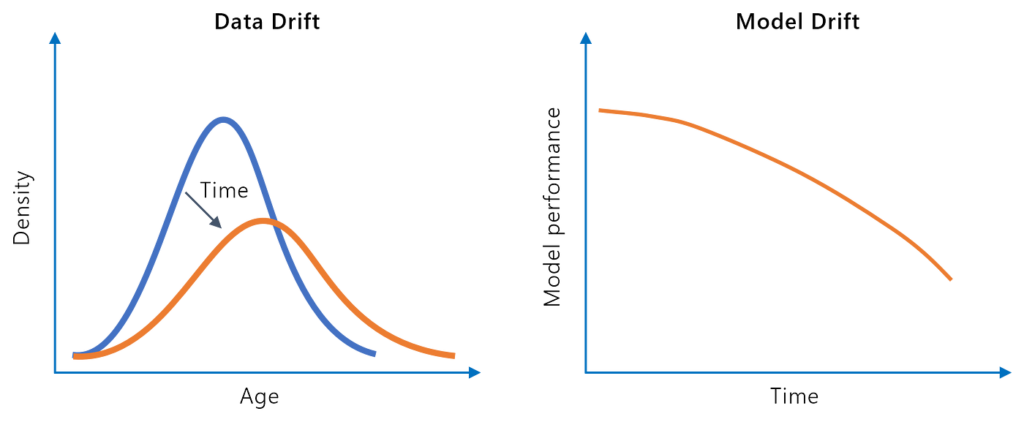
La dérive du modèle, ou dégradation du modèle, fait référence à la baisse des performances prédictives d’un modèle d’apprentissage automatique au fil du temps e...
La fouille de données est un processus sophistiqué d'analyse de vastes ensembles de données brutes afin de révéler des motifs, des relations et des informations...
Google Colaboratory (Google Colab) est une plateforme de notebooks Jupyter basée sur le cloud proposée par Google, permettant aux utilisateurs d’écrire et d’exé...
Le Gradient Boosting est une puissante technique d'ensemble en apprentissage automatique pour la régression et la classification. Il construit des modèles de ma...
L'inférence causale est une approche méthodologique utilisée pour déterminer les relations de cause à effet entre les variables, cruciale dans les sciences pour...
Découvrez comment l’ingénierie et l’extraction de caractéristiques améliorent la performance des modèles d’IA en transformant des données brutes en informations...
Jupyter Notebook est une application web open-source permettant aux utilisateurs de créer et de partager des documents avec du code en direct, des équations, de...
L’algorithme des k-plus proches voisins (KNN) est un algorithme d’apprentissage supervisé non paramétrique utilisé pour les tâches de classification et de régre...
Kaggle est une communauté en ligne et une plateforme destinée aux data scientists et ingénieurs en machine learning pour collaborer, apprendre, concourir et par...
La modélisation prédictive est un processus sophistiqué en science des données et en statistiques qui prévoit les résultats futurs en analysant les tendances de...
Le nettoyage des données est le processus crucial de détection et de correction des erreurs ou des incohérences dans les données afin d'améliorer leur qualité, ...
NumPy est une bibliothèque Python open-source essentielle pour le calcul numérique, offrant des opérations sur les tableaux et des fonctions mathématiques effic...
Pandas est une bibliothèque open source de manipulation et d'analyse de données pour Python, réputée pour sa polyvalence, ses structures de données robustes et ...
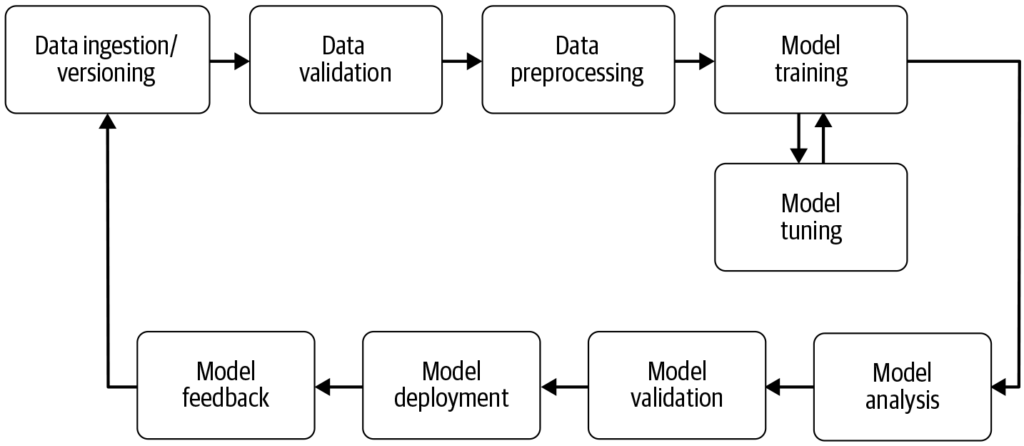
Un pipeline d'apprentissage automatique est un flux de travail automatisé qui rationalise et standardise le développement, l'entraînement, l'évaluation et le dé...
Le R-carré ajusté est une mesure statistique utilisée pour évaluer la qualité d'ajustement d'un modèle de régression, en tenant compte du nombre de prédicteurs ...
La réduction de la dimensionnalité est une technique essentielle en traitement de données et en apprentissage automatique, qui réduit le nombre de variables d'e...
La régression linéaire est une technique analytique fondamentale en statistiques et en apprentissage automatique, modélisant la relation entre les variables dép...
Le regroupement par K-Means est un algorithme populaire d'apprentissage automatique non supervisé qui permet de partitionner des ensembles de données en un nomb...
Scikit-learn est une puissante bibliothèque open-source de machine learning pour Python, offrant des outils simples et efficaces pour l'analyse prédictive de do...