Abandon
L'abandon est une technique de régularisation en IA, en particulier dans les réseaux de neurones, qui lutte contre le surapprentissage en désactivant aléatoirem...
5 min de lecture
AI
Neural Networks
+3
L'abandon est une technique de régularisation en IA, en particulier dans les réseaux de neurones, qui lutte contre le surapprentissage en désactivant aléatoirem...
L'ajustement fin du modèle adapte les modèles pré-entraînés à de nouvelles tâches en effectuant de légères modifications, réduisant ainsi les besoins en données...
AllenNLP est une bibliothèque open-source robuste pour la recherche en traitement du langage naturel (NLP), construite sur PyTorch par AI2. Elle propose des out...
L'apprentissage par renforcement (RL) est un sous-ensemble de l'apprentissage automatique axé sur l'entraînement d'agents à prendre des séquences de décisions d...
L'apprentissage par transfert est une technique sophistiquée d'apprentissage automatique qui permet de réutiliser des modèles entraînés sur une tâche pour une t...
L'apprentissage par transfert est une technique puissante d'IA/ML qui adapte des modèles pré-entraînés à de nouvelles tâches, améliorant les performances avec p...
L'apprentissage profond est un sous-ensemble de l'apprentissage automatique en intelligence artificielle (IA) qui imite le fonctionnement du cerveau humain dans...
Découvrez BERT (Bidirectional Encoder Representations from Transformers), un cadre d'apprentissage automatique open source développé par Google pour le traiteme...
BMXNet est une implémentation open-source des réseaux de neurones binaires (BNNs) basée sur Apache MXNet, permettant un déploiement efficace de l'IA avec des po...
Caffe est un framework open source de deep learning développé par le BVLC, optimisé pour la rapidité et la modularité dans la construction de réseaux de neurone...
Chainer est un framework open source de deep learning offrant une plateforme flexible, intuitive et performante pour les réseaux de neurones, avec des graphes d...
La convergence en IA désigne le processus par lequel les modèles d'apprentissage automatique et d'apprentissage profond atteignent un état stable grâce à un app...
DALL-E est une série de modèles de génération d’images à partir de texte développés par OpenAI, utilisant l’apprentissage profond pour créer des images numériqu...
La descente de gradient est un algorithme d’optimisation fondamental largement utilisé en apprentissage automatique et en apprentissage profond pour minimiser l...
La détection d'anomalies dans les images identifie les motifs qui s'écartent de la norme, essentielle pour des applications telles que l'inspection industrielle...
Stable Diffusion est un modèle avancé de génération d’images à partir de texte qui utilise l’apprentissage profond pour produire des images photoréalistes de ha...
La Distance Fréchet Inception (FID) est une métrique utilisée pour évaluer la qualité des images produites par des modèles génératifs, en particulier les GANs. ...
DL4J, ou DeepLearning4J, est une bibliothèque de deep learning open-source et distribuée pour la machine virtuelle Java (JVM). Faisant partie de l'écosystème Ec...
L’estimation de la pose est une technique de vision par ordinateur qui prédit la position et l’orientation d’une personne ou d’un objet dans des images ou des v...
Les fonctions d’activation sont fondamentales pour les réseaux de neurones artificiels, introduisant la non-linéarité et permettant l’apprentissage de motifs co...
Un grand modèle de langage (LLM) est un type d’IA entraîné sur d’immenses volumes de textes afin de comprendre, générer et manipuler le langage humain. Les LLM ...
Horovod est un cadre robuste et open-source pour l'entraînement distribué en deep learning, conçu pour faciliter une mise à l'échelle efficace sur plusieurs GPU...
L'intelligence artificielle (IA) dans le secteur de la santé exploite des algorithmes avancés et des technologies comme l'apprentissage automatique, le traiteme...
L'IA générative désigne une catégorie d'algorithmes d'intelligence artificielle capables de générer de nouveaux contenus, tels que du texte, des images, de la m...
Ideogram IA est une plateforme innovante de génération d’images qui utilise l’intelligence artificielle pour transformer des instructions textuelles en images d...
L'informatique neuromorphique est une approche de pointe de l'ingénierie informatique qui modélise les éléments matériels et logiciels sur le cerveau humain et ...
Keras est une API open source de réseaux de neurones de haut niveau, puissante et conviviale, écrite en Python et capable de s’exécuter sur TensorFlow, CNTK ou ...
La mémoire à long terme bidirectionnelle (BiLSTM) est un type avancé d'architecture de réseau de neurones récurrents (RNN) qui traite les données séquentielles ...
La mémoire à long court terme (LSTM) est un type spécialisé d'architecture de réseau de neurones récurrents (RNN) conçu pour apprendre les dépendances à long te...
Découvrez la modélisation de séquences en IA et en apprentissage automatique : prédisez et générez des séquences de données comme le texte, l'audio ou l'ADN grâ...
Apache MXNet est un framework open source d’apprentissage profond conçu pour l'entraînement et le déploiement efficaces et flexibles de réseaux de neurones prof...
La normalisation par lot est une technique transformatrice en apprentissage profond qui améliore considérablement le processus d'entraînement des réseaux de neu...
PyTorch est un framework open-source d'apprentissage automatique développé par Meta AI, réputé pour sa flexibilité, ses graphes de calcul dynamiques, son accélé...
Fastai est une bibliothèque de deep learning basée sur PyTorch, offrant des API de haut niveau, l'apprentissage par transfert et une architecture en couches pou...
Découvrez ce qu'est la reconnaissance d'image en IA. À quoi sert-elle, quelles sont les tendances et en quoi diffère-t-elle des technologies similaires.
La Reconnaissance de texte en scène (STR) est une branche spécialisée de la Reconnaissance Optique de Caractères (OCR) axée sur l'identification et l'interpréta...
La Reconnaissance Optique de Caractères (OCR) est une technologie transformatrice qui convertit des documents tels que des papiers numérisés, des PDF ou des ima...
Un Réseau de Neurones Convolutifs (CNN) est un type spécialisé de réseau de neurones artificiels conçu pour traiter des données structurées en grille, telles qu...
Les réseaux de neurones récurrents (RNN) sont une classe sophistiquée de réseaux de neurones artificiels conçus pour traiter des données séquentielles en utilis...
Un réseau de croyance profonde (DBN) est un modèle génératif sophistiqué utilisant des architectures profondes et des machines de Boltzmann restreintes (RBM) po...
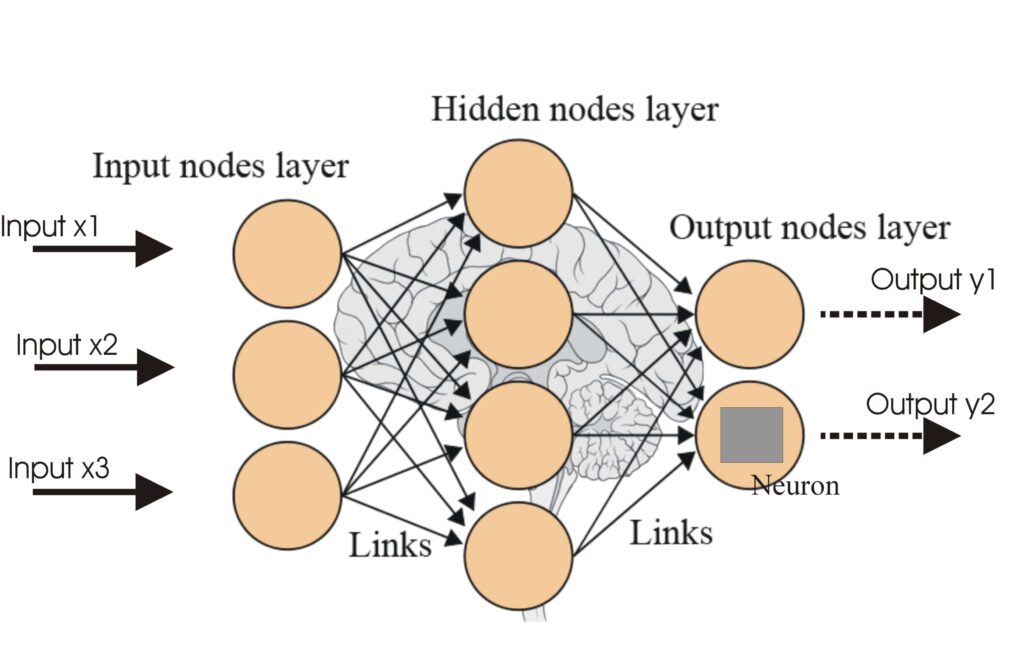
Un réseau de neurones, ou réseau de neurones artificiel (ANN), est un modèle computationnel inspiré du cerveau humain, essentiel en IA et en apprentissage autom...
Les réseaux de neurones artificiels (ANNs) sont un sous-ensemble des algorithmes d'apprentissage automatique inspirés du cerveau humain. Ces modèles computation...
La rétropropagation est un algorithme d'entraînement des réseaux de neurones artificiels qui ajuste les poids pour minimiser l'erreur de prédiction. Découvrez s...
La segmentation d’instances est une tâche de vision par ordinateur qui détecte et délimite chaque objet distinct dans une image avec une précision au niveau du ...
La segmentation sémantique est une technique de vision par ordinateur qui partitionne les images en plusieurs segments, en attribuant à chaque pixel une étiquet...
TensorFlow est une bibliothèque open source développée par l'équipe Google Brain, conçue pour le calcul numérique et l'apprentissage automatique à grande échell...
Torch est une bibliothèque open-source d'apprentissage automatique et un cadre de calcul scientifique basé sur Lua, optimisé pour les tâches d'apprentissage pro...
Le traitement automatique du langage naturel (TALN) permet aux ordinateurs de comprendre, d’interpréter et de générer le langage humain à l’aide de la linguisti...
Un transformateur génératif pré-entraîné (GPT) est un modèle d'IA qui exploite des techniques d'apprentissage profond pour produire des textes imitant de près l...
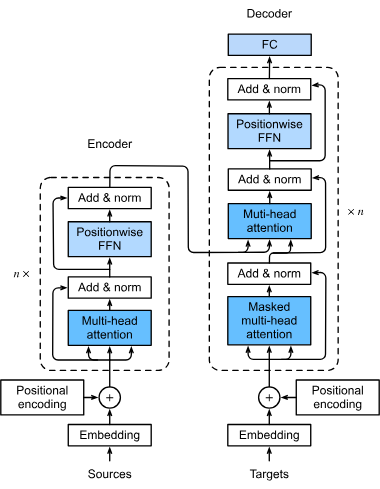
Les transformers sont une architecture de réseau neuronal révolutionnaire qui a transformé l'intelligence artificielle, notamment dans le traitement du langage ...
Un vecteur d'intégration est une représentation numérique dense de données dans un espace multidimensionnel, capturant les relations sémantiques et contextuelle...
La vision par ordinateur est un domaine de l'intelligence artificielle (IA) qui vise à permettre aux ordinateurs d'interpréter et de comprendre le monde visuel....