Intégration du serveur MCP Replicate
Le connecteur Replicate MCP Server de FlowHunt permet un accès fluide au vaste hub de modèles d’IA de Replicate, permettant aux développeurs de rechercher, expl...
5 min de lecture
AI
MCP Server
+5
Le connecteur Replicate MCP Server de FlowHunt permet un accès fluide au vaste hub de modèles d’IA de Replicate, permettant aux développeurs de rechercher, expl...
Intégrez des assistants IA avec Label Studio grâce au serveur MCP Label Studio. Gérez facilement vos projets de labellisation, tâches et prédictions via des out...
L'abandon est une technique de régularisation en IA, en particulier dans les réseaux de neurones, qui lutte contre le surapprentissage en désactivant aléatoirem...
L'IA agentique est une branche avancée de l'intelligence artificielle qui permet aux systèmes d'agir de façon autonome, de prendre des décisions et d'accomplir ...
Un agent intelligent est une entité autonome conçue pour percevoir son environnement via des capteurs et agir sur cet environnement à l'aide d'actionneurs, doté...
L'Aire Sous la Courbe (AUC) est une métrique fondamentale en apprentissage automatique utilisée pour évaluer la performance des modèles de classification binair...
L'ajustement fin du modèle adapte les modèles pré-entraînés à de nouvelles tâches en effectuant de légères modifications, réduisant ainsi les besoins en données...
L'Ajustement Fin Efficace en Paramètres (PEFT) est une approche innovante en IA et en traitement du langage naturel (NLP) qui permet d'adapter de grands modèles...
L'ajustement par instructions est une technique en IA qui affine les grands modèles de langage (LLM) sur des paires instruction-réponse, améliorant leur capacit...
Amazon SageMaker est un service d'apprentissage automatique (ML) entièrement géré par AWS qui permet aux data scientists et aux développeurs de créer, entraîner...
Boostez la précision de l’IA avec RIG ! Découvrez comment créer des chatbots qui vérifient leurs réponses en utilisant à la fois des sources de données personna...
L'analyse de dépendances est une méthode d'analyse syntaxique en TAL qui identifie les relations grammaticales entre les mots, formant des structures arborescen...
L'analyse de sentiment, également appelée extraction d'opinion, est une tâche essentielle en IA et en TAL visant à classifier et interpréter le ton émotionnel d...
Découvrez la technologie de l'analyse prédictive en IA, son fonctionnement et les avantages qu'elle apporte à divers secteurs.
L’analyse sémantique est une technique essentielle du Traitement Automatique du Langage Naturel (TALN) qui interprète et extrait le sens d’un texte, permettant ...
Un Analyste de Données IA associe les compétences d’analyse de données traditionnelles à l’intelligence artificielle (IA) et au machine learning (ML) afin d’ext...
L'apprentissage adaptatif est une méthode éducative transformative qui exploite la technologie pour créer une expérience d'apprentissage personnalisée pour chaq...
L'apprentissage automatique (ML) est un sous-ensemble de l'intelligence artificielle (IA) qui permet aux machines d'apprendre à partir de données, d'identifier ...
L'apprentissage en Few-Shot est une approche d'apprentissage automatique qui permet aux modèles de faire des prédictions précises en utilisant seulement un peti...
L'apprentissage fédéré est une technique collaborative d'apprentissage automatique où plusieurs appareils entraînent un modèle partagé tout en gardant les donné...
L'apprentissage non supervisé est une branche de l'apprentissage automatique axée sur la découverte de motifs, de structures et de relations dans des données no...
L'apprentissage non supervisé est une technique d'apprentissage automatique qui entraîne des algorithmes sur des données non étiquetées afin de découvrir des mo...
L'apprentissage par renforcement (RL) est un sous-ensemble de l'apprentissage automatique axé sur l'entraînement d'agents à prendre des séquences de décisions d...
L'apprentissage par renforcement (RL) est une méthode d'entraînement des modèles d'apprentissage automatique où un agent apprend à prendre des décisions en effe...
L'apprentissage par renforcement à partir du retour humain (RLHF) est une technique d'apprentissage automatique qui intègre l'avis humain pour guider le process...
L'apprentissage par transfert est une technique sophistiquée d'apprentissage automatique qui permet de réutiliser des modèles entraînés sur une tâche pour une t...
L'apprentissage par transfert est une technique puissante d'IA/ML qui adapte des modèles pré-entraînés à de nouvelles tâches, améliorant les performances avec p...
L'apprentissage profond est un sous-ensemble de l'apprentissage automatique en intelligence artificielle (IA) qui imite le fonctionnement du cerveau humain dans...
L'apprentissage semi-supervisé (SSL) est une technique d'apprentissage automatique qui exploite à la fois des données étiquetées et non étiquetées pour entraîne...
L'apprentissage supervisé est une approche fondamentale de l'apprentissage automatique et de l'intelligence artificielle où les algorithmes apprennent à partir ...
L'apprentissage supervisé est un concept fondamental de l'IA et de l'apprentissage automatique où les algorithmes sont entraînés sur des données étiquetées afin...
L'apprentissage Zero-Shot est une méthode en IA où un modèle reconnaît des objets ou des catégories de données sans avoir été explicitement entraîné sur ces cat...
Un arbre de décision est un outil puissant et intuitif pour la prise de décision et l'analyse prédictive, utilisé à la fois pour les tâches de classification et...
Un arbre de décision est un algorithme d'apprentissage supervisé utilisé pour prendre des décisions ou faire des prédictions à partir de données d'entrée. Il se...
L'auto-classification automatise la catégorisation du contenu en analysant ses propriétés et en attribuant des tags à l'aide de technologies telles que l'appren...
Découvrez comment 'Avez-vous voulu dire' (DYM) en TALN identifie et corrige les erreurs dans les saisies utilisateur, telles que les fautes de frappe ou d’ortho...
Le bagging, abréviation de Bootstrap Aggregating, est une technique fondamentale d'apprentissage ensembliste en IA et en apprentissage automatique qui améliore ...
Découvrez BERT (Bidirectional Encoder Representations from Transformers), un cadre d'apprentissage automatique open source développé par Google pour le traiteme...
Explorez le biais en IA : comprenez ses sources, son impact sur l'apprentissage automatique, des exemples concrets et des stratégies d'atténuation pour créer de...
Anaconda est une distribution complète et open source de Python et R, conçue pour simplifier la gestion des paquets et le déploiement pour le calcul scientifiqu...
BigML est une plateforme de machine learning conçue pour simplifier la création et le déploiement de modèles prédictifs. Fondée en 2011, sa mission est de rendr...
Découvrez comment le système Blackwell de NVIDIA inaugure une nouvelle ère de l’informatique accélérée, révolutionnant les industries grâce à des technologies G...
Le boosting est une technique d'apprentissage automatique qui combine les prédictions de plusieurs apprenants faibles pour créer un apprenant fort, améliorant l...
Caffe est un framework open source de deep learning développé par le BVLC, optimisé pour la rapidité et la modularité dans la construction de réseaux de neurone...
Le chaînage de modèles est une technique d'apprentissage automatique où plusieurs modèles sont liés de manière séquentielle, la sortie de chaque modèle servant ...
Chainer est un framework open source de deep learning offrant une plateforme flexible, intuitive et performante pour les réseaux de neurones, avec des graphes d...
Découvrez les principales différences entre les chatbots scriptés et les chatbots IA, leurs usages pratiques et comment ils transforment les interactions client...
ChatGPT est un chatbot IA de pointe développé par OpenAI, utilisant le traitement du langage naturel avancé (NLP) pour permettre des conversations semblables à ...
Un classificateur IA est un algorithme d'apprentissage automatique qui attribue des étiquettes de classe aux données d'entrée, en catégorisant les informations ...
La classification de texte, également appelée catégorisation ou étiquetage de texte, est une tâche fondamentale du TAL qui assigne des catégories prédéfinies au...
Découvrez-en plus sur le Claude 3.5 Sonnet d'Anthropic : comment il se compare à d'autres modèles, ses points forts, ses faiblesses et ses applications dans des...
Clearbit est une puissante plateforme d’activation de données qui aide les entreprises, en particulier les équipes commerciales et marketing, à enrichir les don...
Découvrez l’importance et les applications de l’Humain dans la Boucle (HITL) dans les chatbots IA, où l’expertise humaine améliore les systèmes d’IA pour une me...
Découvrez les bases de la classification d’intention par l’IA, ses techniques, ses applications concrètes, ses défis et les tendances futures pour améliorer les...
Explorez les bases du raisonnement de l’IA, notamment ses types, son importance et ses applications concrètes. Découvrez comment l’IA imite la pensée humaine, a...
Un consultant en IA fait le lien entre la technologie de l'intelligence artificielle et la stratégie d'entreprise, guidant les sociétés dans l'intégration de l'...
La convergence en IA désigne le processus par lequel les modèles d'apprentissage automatique et d'apprentissage profond atteignent un état stable grâce à un app...
Un corpus (pluriel : corpus) en IA désigne un ensemble volumineux et structuré de textes ou de données audio utilisé pour l’entraînement et l’évaluation des mod...
Une courbe d'apprentissage en intelligence artificielle est une représentation graphique illustrant la relation entre la performance d'apprentissage d’un modèle...
Une courbe ROC (Receiver Operating Characteristic) est une représentation graphique utilisée pour évaluer la performance d'un système de classification binaire ...
Découvrez les coûts associés à l'entraînement et au déploiement des grands modèles de langage (LLM) comme GPT-3 et GPT-4, incluant les dépenses en calcul, énerg...
Ideogram.ai est un outil puissant qui démocratise la création d’images par IA, la rendant accessible à un large éventail d’utilisateurs. Découvrez son interface...
La création de contenu par IA exploite l’intelligence artificielle pour automatiser et améliorer la génération, la curation et la personnalisation de contenus n...
DataRobot est une plateforme d’IA complète qui simplifie la création, le déploiement et la gestion des modèles d’apprentissage automatique, rendant l’IA prédict...
Une date de coupure de connaissances est le moment précis après lequel un modèle d'IA ne dispose plus d'informations mises à jour. Découvrez pourquoi ces dates ...
Explorez le monde des modèles d'agents IA grâce à une analyse approfondie de 20 systèmes de pointe. Découvrez comment ils réfléchissent, raisonnent et performen...
Les deepfakes sont une forme de média synthétique où l'IA est utilisée pour générer des images, vidéos ou enregistrements audio très réalistes mais faux. Le ter...
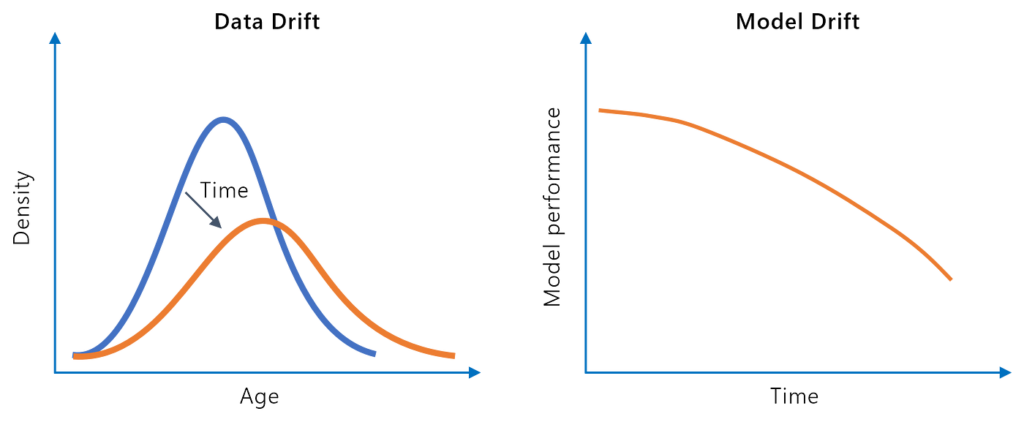
La dérive du modèle, ou dégradation du modèle, fait référence à la baisse des performances prédictives d’un modèle d’apprentissage automatique au fil du temps e...
La descente de gradient est un algorithme d’optimisation fondamental largement utilisé en apprentissage automatique et en apprentissage profond pour minimiser l...
La détection d'anomalies est le processus d'identification de points de données, d'événements ou de motifs qui s'écartent de la norme attendue au sein d'un ense...
La détection de fraude par l'IA utilise l'apprentissage automatique pour identifier et limiter les activités frauduleuses en temps réel. Elle améliore la précis...
L’IA dans la détection de la fraude financière désigne l’application des technologies d’intelligence artificielle pour identifier et prévenir les activités frau...
Le développement de prototype IA est le processus itératif de conception et de création de versions préliminaires de systèmes d’IA, permettant l’expérimentation...
Stable Diffusion est un modèle avancé de génération d’images à partir de texte qui utilise l’apprentissage profond pour produire des images photoréalistes de ha...
DL4J, ou DeepLearning4J, est une bibliothèque de deep learning open-source et distribuée pour la machine virtuelle Java (JVM). Faisant partie de l'écosystème Ec...
Les données d'entraînement désignent l'ensemble de données utilisé pour instruire les algorithmes d'IA, leur permettant de reconnaître des motifs, de prendre de...
Découvrez ce que sont les données non structurées et comment elles se comparent aux données structurées. Apprenez-en plus sur les défis et les outils utilisés p...
Les données synthétiques désignent des informations générées artificiellement qui imitent les données réelles. Elles sont créées à l'aide d'algorithmes et de si...
L'effondrement du modèle est un phénomène en intelligence artificielle où un modèle entraîné se dégrade au fil du temps, particulièrement lorsqu'il dépend de do...
L'entropie croisée est un concept clé à la fois en théorie de l'information et en apprentissage automatique, servant de métrique pour mesurer la divergence entr...
L'Erreur Absolue Moyenne (MAE) est une métrique fondamentale en apprentissage automatique pour évaluer les modèles de régression. Elle mesure l'amplitude moyenn...
L’erreur d'entraînement en IA et en apprentissage automatique est l’écart entre les prédictions d’un modèle et les résultats réels pendant l’entraînement. C’est...
L’erreur de généralisation mesure la capacité d’un modèle d’apprentissage automatique à prédire des données inédites, en équilibrant biais et variance pour gara...
L’estimation de la pose est une technique de vision par ordinateur qui prédit la position et l’orientation d’une personne ou d’un objet dans des images ou des v...
L'intelligence artificielle (IA) dans l'examen des documents juridiques représente un changement significatif dans la manière dont les professionnels du droit g...
L’explicabilité de l’IA fait référence à la capacité de comprendre et d’interpréter les décisions et prédictions prises par les systèmes d’intelligence artifici...
L'extraction de caractéristiques transforme des données brutes en un ensemble réduit de caractéristiques informatives, améliorant l'apprentissage automatique en...
Découvrez une solution Python évolutive pour l'extraction de données de factures à l'aide de l'OCR basé sur l'IA. Apprenez à convertir des PDF, à téléverser des...
Le F-Score, également appelé F-Mesure ou Score F1, est une métrique statistique utilisée pour évaluer la précision d’un test ou d’un modèle, en particulier en c...
Les fonctions d’activation sont fondamentales pour les réseaux de neurones artificiels, introduisant la non-linéarité et permettant l’apprentissage de motifs co...
La fouille de données est un processus sophistiqué d'analyse de vastes ensembles de données brutes afin de révéler des motifs, des relations et des informations...
Garbage In, Garbage Out (GIGO) souligne comment la qualité de la sortie d'une IA et d'autres systèmes dépend directement de la qualité des données d'entrée. Déc...
Découvrez les principales différences entre la génération augmentée par récupération (RAG) et la génération augmentée par cache (CAG) en IA. Apprenez comment RA...
Découvrez comment automatiser la création de textes descriptifs à partir d’images grâce à l’API et au générateur de workflows de FlowHunt.io, afin d’améliorer l...
Gensim est une bibliothèque Python open source populaire pour le traitement du langage naturel (NLP), spécialisée dans la modélisation de sujets non supervisée,...
La gestion de projets IA en R&D fait référence à l'application stratégique de l'intelligence artificielle (IA) et des technologies d'apprentissage automatique (...
Google Colaboratory (Google Colab) est une plateforme de notebooks Jupyter basée sur le cloud proposée par Google, permettant aux utilisateurs d’écrire et d’exé...
Le Gradient Boosting est une puissante technique d'ensemble en apprentissage automatique pour la régression et la classification. Il construit des modèles de ma...
Les heuristiques offrent des solutions rapides et satisfaisantes en IA en s'appuyant sur l'expérience et des règles empiriques, simplifiant les problèmes de rec...
Horovod est un cadre robuste et open-source pour l'entraînement distribué en deep learning, conçu pour faciliter une mise à l'échelle efficace sur plusieurs GPU...
Affichage 1 à 100 de 211 résultats