Apprentissage profond
L'apprentissage profond est un sous-ensemble de l'apprentissage automatique en intelligence artificielle (IA) qui imite le fonctionnement du cerveau humain dans...
4 min de lecture
Deep Learning
AI
+5
L'apprentissage profond est un sous-ensemble de l'apprentissage automatique en intelligence artificielle (IA) qui imite le fonctionnement du cerveau humain dans...
La Compréhension du Langage Naturel (NLU) est un sous-domaine de l'IA axé sur la capacité des machines à comprendre et à interpréter le langage humain dans son ...
L'expansion de requête dans FlowHunt améliore la compréhension du chatbot en trouvant des synonymes, en corrigeant les fautes d'orthographe et en assurant des r...
Qu'est-ce qu'un hétéroonyme ? Un hétéroonyme est un phénomène linguistique unique où deux mots ou plus partagent la même orthographe mais ont des prononciations...
L’indice de facilité de lecture de Flesch est une formule qui évalue la facilité de compréhension d’un texte. Développée par Rudolf Flesch dans les années 1940,...
Un jeton, dans le contexte des grands modèles de langage (LLM), est une séquence de caractères que le modèle convertit en représentations numériques pour un tra...
Un métaprompt en intelligence artificielle est une instruction de haut niveau conçue pour générer ou améliorer d'autres prompts pour les grands modèles de langa...
Découvrez Mistral AI et les modèles LLM qu'ils proposent. Découvrez comment ces modèles sont utilisés et ce qui les distingue.
Une ontologie en intelligence artificielle est une spécification formelle d'une conceptualisation partagée, définissant des classes, des propriétés et des relat...
Découvrez comment l’Optimisation pour les moteurs de questions (AEO) déplace l’accent du SEO traditionnel vers la fourniture de réponses directes aux utilisateu...
La Reconnaissance d'Entités Nommées (NER) est un sous-domaine clé du Traitement Automatique du Langage Naturel (NLP) en IA, qui se concentre sur l'identificatio...
Le retour d'information aux étudiants basé sur l'IA exploite l'intelligence artificielle pour fournir des analyses évaluatives personnalisées, en temps réel, ai...
Le traitement automatique du langage naturel (TALN) permet aux ordinateurs de comprendre, d’interpréter et de générer le langage humain à l’aide de la linguisti...
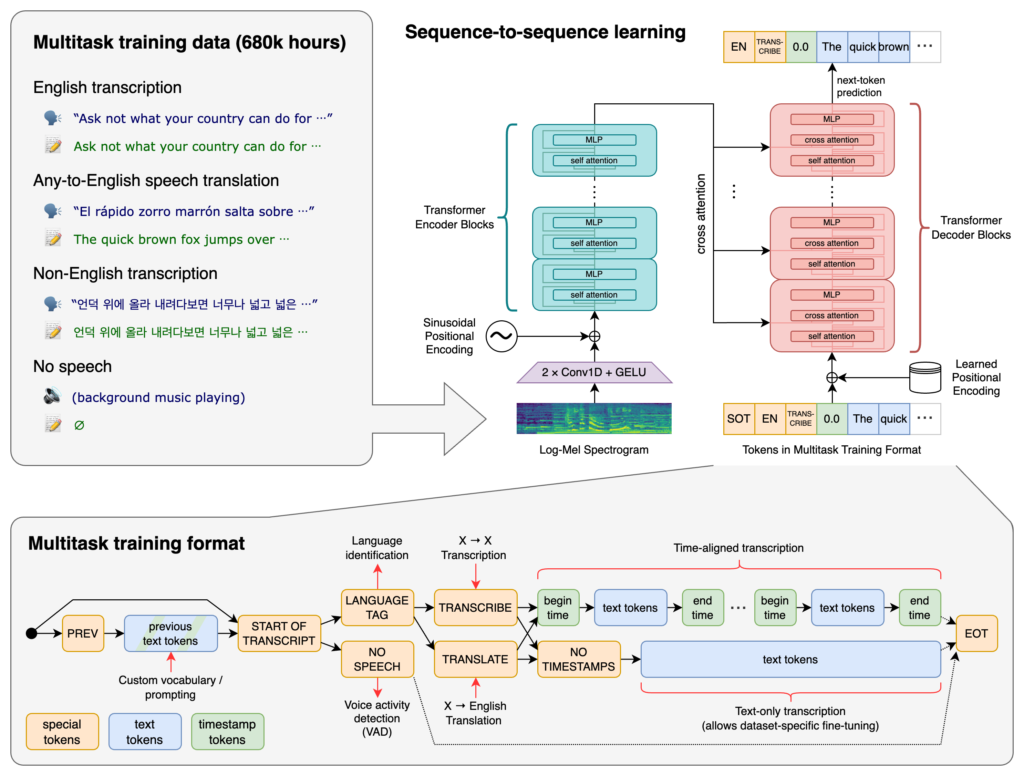
OpenAI Whisper est un système avancé de reconnaissance automatique de la parole (ASR) qui transcrit la langue parlée en texte, prenant en charge 99 langues, rés...