Abandon
L'abandon est une technique de régularisation en IA, en particulier dans les réseaux de neurones, qui lutte contre le surapprentissage en désactivant aléatoirem...
5 min de lecture
AI
Neural Networks
+3
L'abandon est une technique de régularisation en IA, en particulier dans les réseaux de neurones, qui lutte contre le surapprentissage en désactivant aléatoirem...
L'apprentissage profond est un sous-ensemble de l'apprentissage automatique en intelligence artificielle (IA) qui imite le fonctionnement du cerveau humain dans...
Découvrez les capacités avancées de l'agent IA Claude 3. Cette analyse approfondie révèle comment Claude 3 va bien au-delà de la génération de texte, mettant en...
Découvrez comment le système Blackwell de NVIDIA inaugure une nouvelle ère de l’informatique accélérée, révolutionnant les industries grâce à des technologies G...
Chainer est un framework open source de deep learning offrant une plateforme flexible, intuitive et performante pour les réseaux de neurones, avec des graphes d...
Explorez les bases du raisonnement de l’IA, notamment ses types, son importance et ses applications concrètes. Découvrez comment l’IA imite la pensée humaine, a...
La descente de gradient est un algorithme d’optimisation fondamental largement utilisé en apprentissage automatique et en apprentissage profond pour minimiser l...
Les fonctions d’activation sont fondamentales pour les réseaux de neurones artificiels, introduisant la non-linéarité et permettant l’apprentissage de motifs co...
Découvrez le générateur de légendes d’images alimenté par l’IA de FlowHunt. Créez instantanément des légendes engageantes et pertinentes pour vos images avec de...
Keras est une API open source de réseaux de neurones de haut niveau, puissante et conviviale, écrite en Python et capable de s’exécuter sur TensorFlow, CNTK ou ...
La mémoire à long terme bidirectionnelle (BiLSTM) est un type avancé d'architecture de réseau de neurones récurrents (RNN) qui traite les données séquentielles ...
La mémoire à long court terme (LSTM) est un type spécialisé d'architecture de réseau de neurones récurrents (RNN) conçu pour apprendre les dépendances à long te...
La mémoire associative en intelligence artificielle (IA) permet aux systèmes de se souvenir d’informations en se basant sur des schémas et des associations, imi...
Apache MXNet est un framework open source d’apprentissage profond conçu pour l'entraînement et le déploiement efficaces et flexibles de réseaux de neurones prof...
La normalisation par lot est une technique transformatrice en apprentissage profond qui améliore considérablement le processus d'entraînement des réseaux de neu...
La reconnaissance de formes est un processus informatique visant à identifier des motifs et des régularités dans les données, essentiel dans des domaines comme ...
La régularisation en intelligence artificielle (IA) désigne un ensemble de techniques utilisées pour éviter le surapprentissage dans les modèles d'apprentissage...
Un réseau antagoniste génératif (GAN) est un cadre d'apprentissage automatique composé de deux réseaux neuronaux — un générateur et un discriminateur — qui s'af...
Les réseaux de neurones récurrents (RNN) sont une classe sophistiquée de réseaux de neurones artificiels conçus pour traiter des données séquentielles en utilis...
Un réseau de croyance profonde (DBN) est un modèle génératif sophistiqué utilisant des architectures profondes et des machines de Boltzmann restreintes (RBM) po...
Un réseau de neurones, ou réseau de neurones artificiel (ANN), est un modèle computationnel inspiré du cerveau humain, essentiel en IA et en apprentissage autom...
Les réseaux de neurones artificiels (ANNs) sont un sous-ensemble des algorithmes d'apprentissage automatique inspirés du cerveau humain. Ces modèles computation...
La rétropropagation est un algorithme d'entraînement des réseaux de neurones artificiels qui ajuste les poids pour minimiser l'erreur de prédiction. Découvrez s...
Torch est une bibliothèque open-source d'apprentissage automatique et un cadre de calcul scientifique basé sur Lua, optimisé pour les tâches d'apprentissage pro...
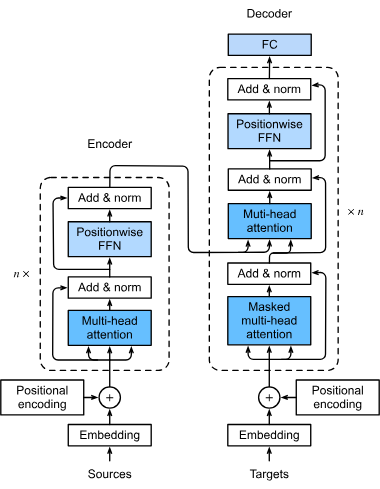
Les transformers sont une architecture de réseau neuronal révolutionnaire qui a transformé l'intelligence artificielle, notamment dans le traitement du langage ...
Un modèle de transformeur est un type de réseau de neurones spécifiquement conçu pour traiter des données séquentielles, telles que du texte, de la parole ou de...