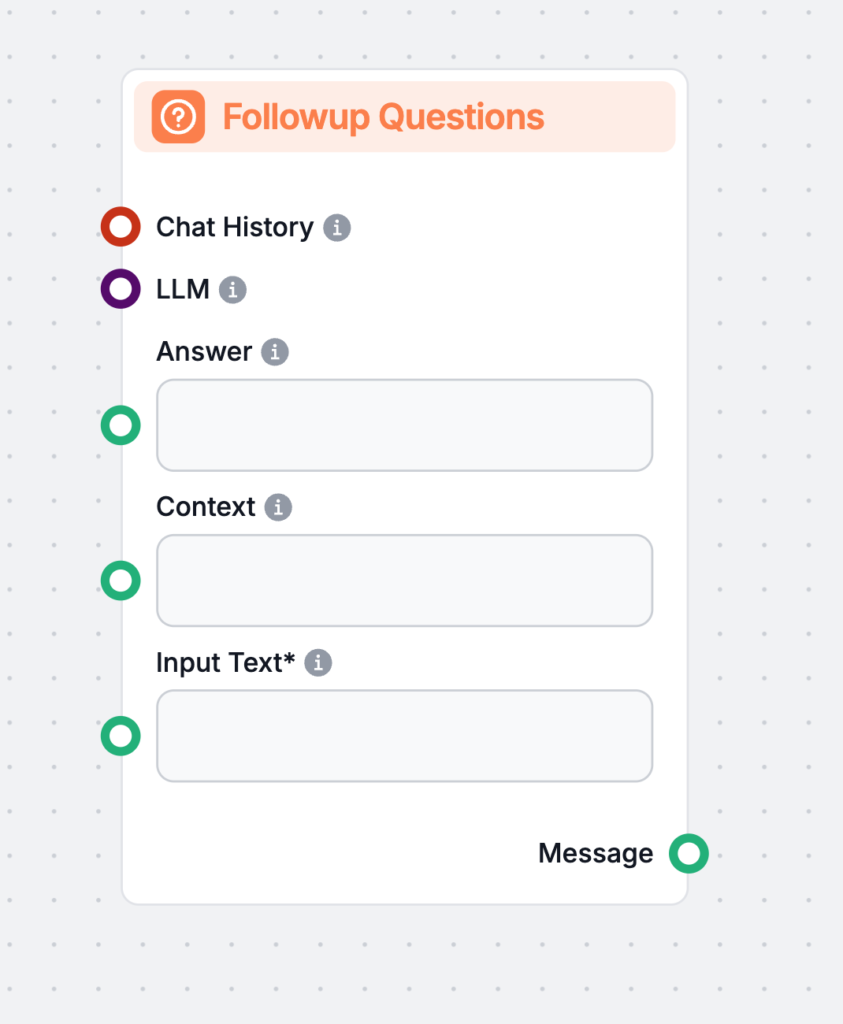
Ajustement Fin
L'ajustement fin du modèle adapte les modèles pré-entraînés à de nouvelles tâches en effectuant de légères modifications, réduisant ainsi les besoins en données...
10 min de lecture
Fine-Tuning
Transfer Learning
+6
L'ajustement fin du modèle adapte les modèles pré-entraînés à de nouvelles tâches en effectuant de légères modifications, réduisant ainsi les besoins en données...
L'Ajustement Fin Efficace en Paramètres (PEFT) est une approche innovante en IA et en traitement du langage naturel (NLP) qui permet d'adapter de grands modèles...
AllenNLP est une bibliothèque open-source robuste pour la recherche en traitement du langage naturel (NLP), construite sur PyTorch par AI2. Elle propose des out...
L'analyse de dépendances est une méthode d'analyse syntaxique en TAL qui identifie les relations grammaticales entre les mots, formant des structures arborescen...
L'analyse de sentiment, également appelée extraction d'opinion, est une tâche essentielle en IA et en TAL visant à classifier et interpréter le ton émotionnel d...
L’analyse sémantique est une technique essentielle du Traitement Automatique du Langage Naturel (TALN) qui interprète et extrait le sens d’un texte, permettant ...
L'apprentissage par transfert est une technique puissante d'IA/ML qui adapte des modèles pré-entraînés à de nouvelles tâches, améliorant les performances avec p...
L'auto-classification automatise la catégorisation du contenu en analysant ses propriétés et en attribuant des tags à l'aide de technologies telles que l'appren...
Découvrez comment 'Avez-vous voulu dire' (DYM) en TALN identifie et corrige les erreurs dans les saisies utilisateur, telles que les fautes de frappe ou d’ortho...
Découvrez BERT (Bidirectional Encoder Representations from Transformers), un cadre d'apprentissage automatique open source développé par Google pour le traiteme...
Les chatbots sont des outils numériques qui simulent la conversation humaine grâce à l’IA et au traitement du langage naturel (NLP), offrant une assistance 24h/...
ChatGPT est un chatbot IA de pointe développé par OpenAI, utilisant le traitement du langage naturel avancé (NLP) pour permettre des conversations semblables à ...
La classification de texte, également appelée catégorisation ou étiquetage de texte, est une tâche fondamentale du TAL qui assigne des catégories prédéfinies au...
Découvrez les bases de la classification d’intention par l’IA, ses techniques, ses applications concrètes, ses défis et les tendances futures pour améliorer les...
Un corpus (pluriel : corpus) en IA désigne un ensemble volumineux et structuré de textes ou de données audio utilisé pour l’entraînement et l’évaluation des mod...
Découvrez les frameworks multi-agents Crew.ai et Langchain. Crew.ai excelle dans la collaboration et la division des tâches, idéal pour les simulations complexe...
La détection de la langue dans les grands modèles de langage (LLM) est le processus par lequel ces modèles identifient la langue d'un texte d'entrée, permettant...
L'enrichissement de contenu avec l’IA valorise un contenu brut et non structuré en appliquant des techniques d’intelligence artificielle pour en extraire des in...
L'étiquetage des parties du discours (POS tagging) est une tâche essentielle en linguistique computationnelle et en traitement automatique du langage naturel (T...
L'intelligence artificielle (IA) dans l'examen des documents juridiques représente un changement significatif dans la manière dont les professionnels du droit g...
Découvrez une solution Python évolutive pour l'extraction de données de factures à l'aide de l'OCR basé sur l'IA. Apprenez à convertir des PDF, à téléverser des...
Le F-Score, également appelé F-Mesure ou Score F1, est une métrique statistique utilisée pour évaluer la précision d’un test ou d’un modèle, en particulier en c...
Le fenêtrage en intelligence artificielle consiste à traiter les données par segments ou « fenêtres » afin d’analyser efficacement des informations séquentielle...
Découvrez le générateur de légendes d’images alimenté par l’IA de FlowHunt. Créez instantanément des légendes engageantes et pertinentes pour vos images avec de...
Découvrez comment les générateurs de scripts de vente IA utilisent le NLP et le NLG pour créer des scripts de vente personnalisés et persuasifs pour les appels,...
La génération de texte avec les grands modèles de langage (LLM) fait référence à l'utilisation avancée de modèles d'apprentissage automatique pour produire un t...
La génération du langage naturel (NLG) est un sous-domaine de l’IA qui consiste à convertir des données structurées en texte ressemblant à celui des humains. La...
Gensim est une bibliothèque Python open source populaire pour le traitement du langage naturel (NLP), spécialisée dans la modélisation de sujets non supervisée,...
Un grand modèle de langage (LLM) est un type d’IA entraîné sur d’immenses volumes de textes afin de comprendre, générer et manipuler le langage humain. Les LLM ...
Hugging Face Transformers est une bibliothèque Python open-source de premier plan qui facilite la mise en œuvre de modèles Transformer pour des tâches d'apprent...
L’IA conversationnelle désigne les technologies permettant aux ordinateurs de simuler des conversations humaines grâce au traitement du langage naturel (NLP), à...
L'intelligence artificielle (IA) dans le secteur de la santé exploite des algorithmes avancés et des technologies comme l'apprentissage automatique, le traiteme...
L’intelligence artificielle (IA) en cybersécurité exploite des technologies telles que l’apprentissage automatique et le traitement du langage naturel (NLP) pou...
L’IA extractive est une branche spécialisée de l’intelligence artificielle axée sur l’identification et la récupération d’informations spécifiques à partir de s...
L’informatique cognitive représente un modèle technologique transformateur qui simule les processus de pensée humaine dans des scénarios complexes. Elle intègre...
Découvrez le rôle essentiel de la classification d'intentions par l'IA pour améliorer les interactions utilisateurs avec la technologie, optimiser le support cl...
La reformulation dans la communication est l'art de réexprimer le message d'une autre personne avec ses propres mots tout en préservant le sens initial. Elle as...
LangChain est un framework open source pour développer des applications alimentées par des Large Language Models (LLM), facilitant l'intégration de puissants LL...
Le Large Language Model Meta AI (LLaMA) est un modèle de traitement du langage naturel de pointe développé par Meta. Avec jusqu'à 65 milliards de paramètres, LL...
LazyGraphRAG est une approche innovante de la génération augmentée par la récupération (RAG), optimisant l'efficacité et réduisant les coûts de la récupération ...
La mémoire à long terme bidirectionnelle (BiLSTM) est un type avancé d'architecture de réseau de neurones récurrents (RNN) qui traite les données séquentielles ...
Le marketing alimenté par l'IA exploite des technologies d'intelligence artificielle telles que l'apprentissage automatique, le traitement du langage naturel et...
La mémoire à long court terme (LSTM) est un type spécialisé d'architecture de réseau de neurones récurrents (RNN) conçu pour apprendre les dépendances à long te...
Un modèle d’IA fondamental est un modèle d’apprentissage automatique à grande échelle, entraîné sur d’énormes quantités de données et adaptable à un large évent...
Découvrez les modèles d’IA discriminants—des modèles de machine learning axés sur la classification et la régression en modélisant la frontière de décision entr...
Découvrez la modélisation de séquences en IA et en apprentissage automatique : prédisez et générez des séquences de données comme le texte, l'audio ou l'ADN grâ...
Découvrez ce qu'est un moteur d'Insight — une plateforme avancée, pilotée par l'IA, qui améliore la recherche et l'analyse de données en comprenant le contexte ...
Natural Language Toolkit (NLTK) est une suite complète de bibliothèques et de programmes Python pour le traitement du langage naturel (NLP) symbolique et statis...
Perplexity AI est un moteur de recherche avancé alimenté par l'IA et un outil conversationnel qui exploite le traitement du langage naturel et l'apprentissage a...
PyTorch est un framework open-source d'apprentissage automatique développé par Meta AI, réputé pour sa flexibilité, ses graphes de calcul dynamiques, son accélé...
Le raisonnement multi-saut est un processus d’IA, notamment en traitement du langage naturel (NLP) et dans les graphes de connaissances, où les systèmes relient...
La rareté des données fait référence à une quantité insuffisante de données pour entraîner des modèles d'apprentissage automatique ou réaliser une analyse appro...
La recherche d'information exploite l'IA, le traitement du langage naturel (NLP) et l'apprentissage automatique pour récupérer efficacement et précisément les d...
La Recherche de documents améliorée avec le NLP intègre des techniques avancées de Traitement du Langage Naturel dans les systèmes de recherche documentaire, am...
Découvrez ce qu'est un réécrivain de paragraphes, comment il fonctionne, ses principales fonctionnalités et comment il peut améliorer la qualité de l'écriture, ...
Découvrez ce qu'est un Réécrivain de phrases IA, comment il fonctionne, ses cas d'utilisation, et comment il aide les rédacteurs, étudiants et marketeurs à refo...
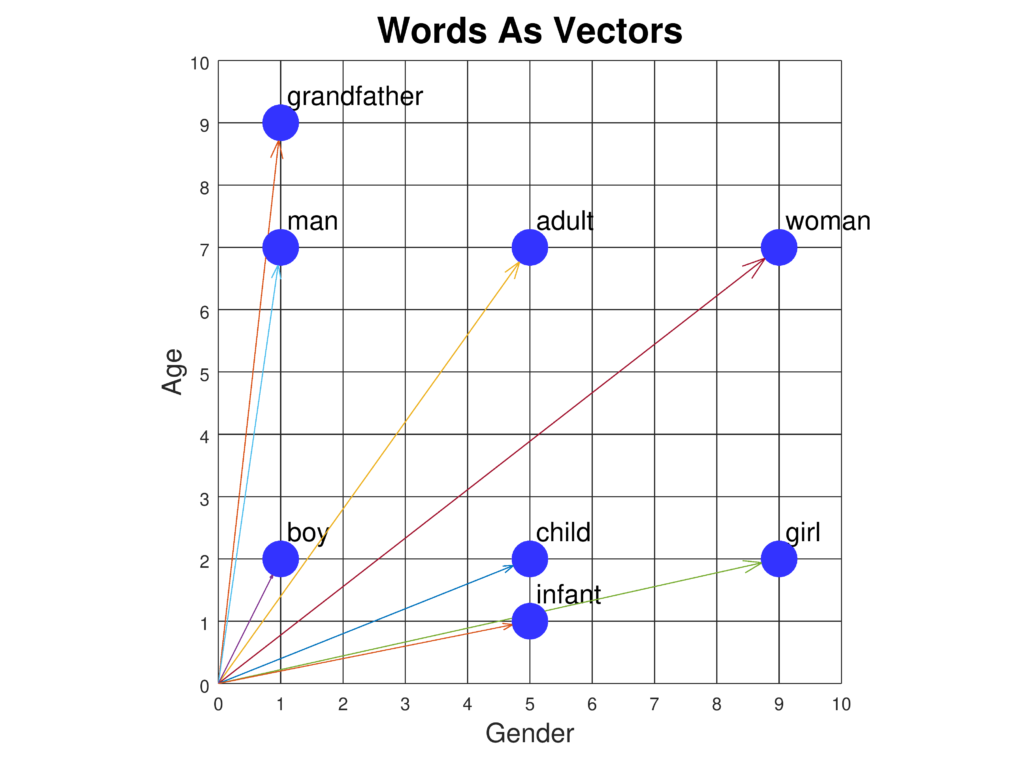
Les représentations vectorielles de mots sont des représentations sophistiquées des mots dans un espace vectoriel continu, capturant les relations sémantiques e...
Les réseaux de neurones récurrents (RNN) sont une classe sophistiquée de réseaux de neurones artificiels conçus pour traiter des données séquentielles en utilis...
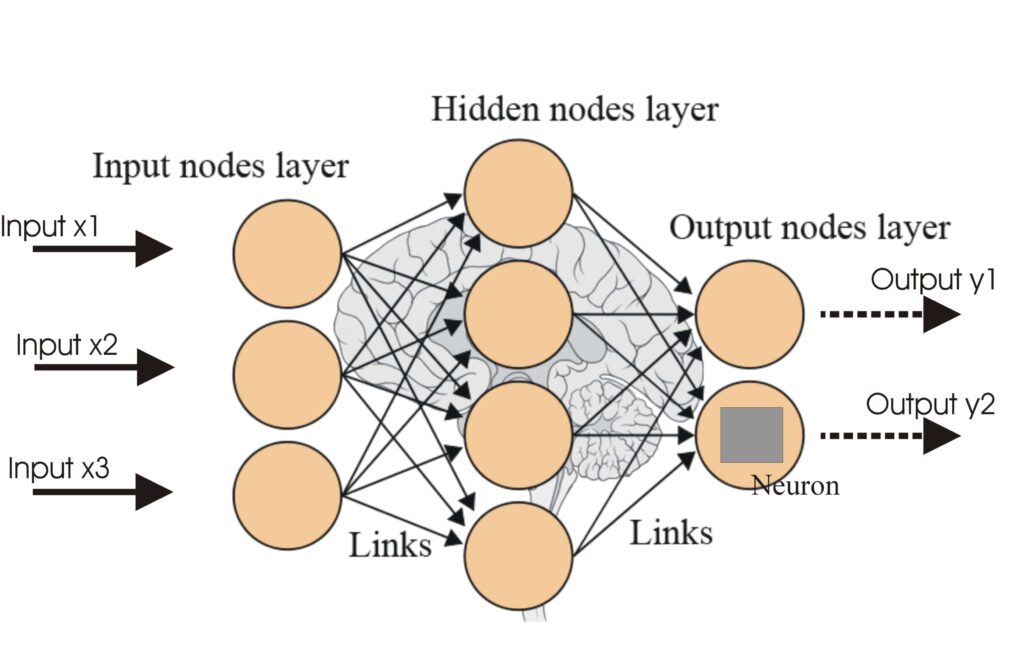
Un réseau de neurones, ou réseau de neurones artificiel (ANN), est un modèle computationnel inspiré du cerveau humain, essentiel en IA et en apprentissage autom...
La résolution de la coréférence est une tâche fondamentale du TALN qui identifie et relie les expressions dans un texte faisant référence à la même entité, esse...
Cet outil est idéal pour les professionnels, les étudiants et toute personne confrontée à de grandes quantités d'informations. Il vous aide à transformer un lon...
Le résumé de texte est un processus essentiel de l'IA qui condense de longs documents en résumés concis, tout en préservant les informations et le sens clés. En...
Le score BLEU, ou Bilingual Evaluation Understudy, est une métrique essentielle pour évaluer la qualité des textes produits par les systèmes de traduction autom...
Le score ROUGE est un ensemble de métriques utilisées pour évaluer la qualité des résumés et traductions générés par des machines en les comparant à des référen...
Découvrez ce qu'est un SDR IA et comment les représentants du développement commercial utilisant l'intelligence artificielle automatisent la prospection, la qua...
spaCy est une bibliothèque Python open-source robuste pour le traitement avancé du langage naturel (NLP), reconnue pour sa rapidité, son efficacité et ses fonct...
Un système d'automatisation par IA intègre des technologies d'intelligence artificielle aux processus d'automatisation, enrichissant l'automatisation traditionn...
Le traitement automatique du langage naturel (TALN) permet aux ordinateurs de comprendre, d’interpréter et de générer le langage humain à l’aide de la linguisti...
Le traitement automatique du langage naturel (TALN) est un sous-domaine de l'intelligence artificielle (IA) qui permet aux ordinateurs de comprendre, d'interpré...
Le Traitement Intelligent des Documents (IDP) est une technologie avancée exploitant l'IA pour automatiser l'extraction, le traitement et l'analyse des données ...
Un transformateur génératif pré-entraîné (GPT) est un modèle d'IA qui exploite des techniques d'apprentissage profond pour produire des textes imitant de près l...
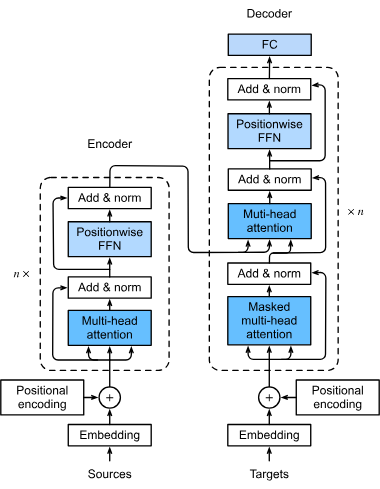
Les transformers sont une architecture de réseau neuronal révolutionnaire qui a transformé l'intelligence artificielle, notamment dans le traitement du langage ...
Un modèle de transformeur est un type de réseau de neurones spécifiquement conçu pour traiter des données séquentielles, telles que du texte, de la parole ou de...
Un vecteur d'intégration est une représentation numérique dense de données dans un espace multidimensionnel, capturant les relations sémantiques et contextuelle...