Générateur de Code Python IA
Transformez vos idées de code en code Python propre et fonctionnel grâce à notre générateur alimenté par l’IA. Exploitant l’intégration à Google Search et la co...
2 min de lecture
AI
Programming
+4
Transformez vos idées de code en code Python propre et fonctionnel grâce à notre générateur alimenté par l’IA. Exploitant l’intégration à Google Search et la co...
Exemple rapide pour développer votre propre serveur MCP avec Python.
py-mcp-line est un serveur MCP basé sur Python qui permet aux assistants IA d'accéder et d'interagir avec les messages LINE Bot. Il expose des ressources, prend...
Le serveur MCP AWS Resources permet aux assistants IA de gérer et d'interroger les ressources AWS de manière conversationnelle en utilisant Python et boto3. Int...
Video Still Capture MCP est un serveur basé sur Python qui offre aux assistants IA un accès en temps réel à la webcam et aux sources vidéo via OpenCV, permettan...
Intégrez des assistants IA à l’API Terraform Cloud grâce au serveur MCP Terraform Cloud. Gérez l’infrastructure en langage naturel, automatisez les tâches de wo...
Le serveur MetaTrader MCP connecte les grands modèles de langage IA à MetaTrader 5, permettant le trading automatisé, la gestion de portefeuille et l'analyse in...
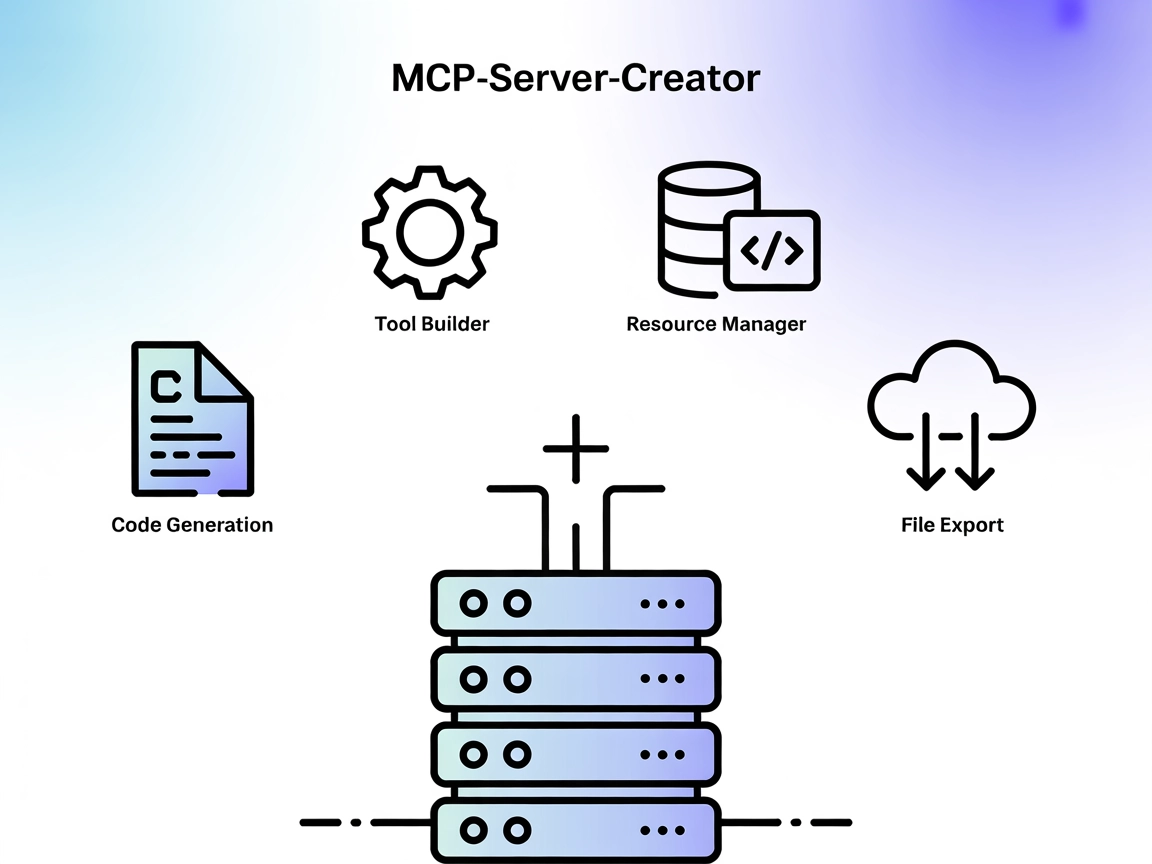
Le MCP-Server-Creator est un méta-serveur qui permet la création et la configuration rapides de nouveaux serveurs Model Context Protocol (MCP). Grâce à la génér...
Le serveur MCP QGIS fait le lien entre QGIS Desktop et les LLM pour une automatisation IA : contrôle des projets, des couches, des algorithmes et exécution de c...
Le serveur MCP Code Executor permet à FlowHunt et à d'autres outils pilotés par des LLM d'exécuter en toute sécurité du code Python dans des environnements isol...
Le serveur MCP pydanticpydantic-aimcp-run-python fait le lien entre les assistants IA et des environnements d’exécution Python sécurisés et contrôlés. Il permet...
Anaconda est une distribution complète et open source de Python et R, conçue pour simplifier la gestion des paquets et le déploiement pour le calcul scientifiqu...
Chainer est un framework open source de deep learning offrant une plateforme flexible, intuitive et performante pour les réseaux de neurones, avec des graphes d...
Dash est un framework Python open-source développé par Plotly pour créer des applications interactives de visualisation de données et des tableaux de bord, comb...
Découvrez une solution Python évolutive pour l'extraction de données de factures à l'aide de l'OCR basé sur l'IA. Apprenez à convertir des PDF, à téléverser des...
Gensim est une bibliothèque Python open source populaire pour le traitement du langage naturel (NLP), spécialisée dans la modélisation de sujets non supervisée,...
Google Colaboratory (Google Colab) est une plateforme de notebooks Jupyter basée sur le cloud proposée par Google, permettant aux utilisateurs d’écrire et d’exé...
Jupyter Notebook est une application web open-source permettant aux utilisateurs de créer et de partager des documents avec du code en direct, des équations, de...
Keras est une API open source de réseaux de neurones de haut niveau, puissante et conviviale, écrite en Python et capable de s’exécuter sur TensorFlow, CNTK ou ...
Une matrice de confusion est un outil d'apprentissage automatique permettant d'évaluer les performances des modèles de classification, détaillant les vrais/faux...
Natural Language Toolkit (NLTK) est une suite complète de bibliothèques et de programmes Python pour le traitement du langage naturel (NLP) symbolique et statis...
NumPy est une bibliothèque Python open-source essentielle pour le calcul numérique, offrant des opérations sur les tableaux et des fonctions mathématiques effic...
Pandas est une bibliothèque open source de manipulation et d'analyse de données pour Python, réputée pour sa polyvalence, ses structures de données robustes et ...
Plotly est une bibliothèque de graphiques open source avancée permettant de créer des graphiques interactifs et de qualité publication en ligne. Compatible avec...
Scikit-learn est une puissante bibliothèque open-source de machine learning pour Python, offrant des outils simples et efficaces pour l'analyse prédictive de do...
SciPy est une bibliothèque Python open-source robuste pour le calcul scientifique et technique. S'appuyant sur NumPy, elle propose des algorithmes mathématiques...
spaCy est une bibliothèque Python open-source robuste pour le traitement avancé du langage naturel (NLP), reconnue pour sa rapidité, son efficacité et ses fonct...