Transformers
Transformers are a revolutionary neural network architecture that has transformed artificial intelligence, especially in natural language processing. Introduced...
8 min read
AI
Transformers
+4
Discover BERT (Bidirectional Encoder Representations from Transformers), an open-source machine learning framework developed by Google for natural language processing. Learn how BERT’s bidirectional Transformer architecture revolutionizes AI language understanding, its applications in NLP, chatbots, automation, and key research advancements.
BERT, which stands for Bidirectional Encoder Representations from Transformers, is an open-source machine learning framework for natural language processing (NLP). Developed by researchers at Google AI Language and introduced in 2018, BERT has significantly advanced NLP by enabling machines to understand language more like humans do.
At its core, BERT helps computers interpret the meaning of ambiguous or context-dependent language in text by considering surrounding words in a sentence—both before and after the target word. This bidirectional approach allows BERT to grasp the full nuance of language, making it highly effective for a wide variety of NLP tasks.
Before BERT, most language models processed text in a unidirectional manner (either left-to-right or right-to-left), which limited their ability to capture context.
Earlier models like Word2Vec and GloVe generated context-free word embeddings, assigning a single vector to each word regardless of context. This approach struggled with polysemous words (e.g., “bank” as a financial institution vs. riverbank).
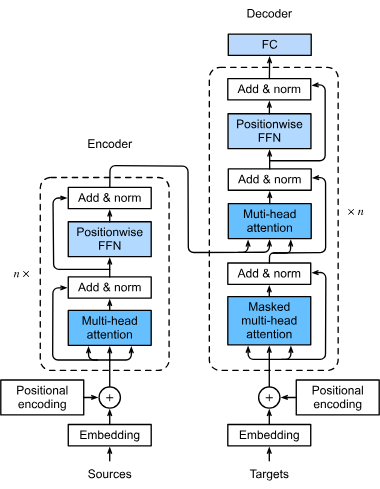
In 2017, the Transformer architecture was introduced in the paper “Attention Is All You Need.” Transformers are deep learning models that use self-attention, allowing them to weigh the significance of each part of the input dynamically.
Transformers revolutionized NLP by processing all words in a sentence simultaneously, enabling larger-scale training.
Google researchers built on the Transformer architecture to develop BERT, introduced in the 2018 paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” BERT’s innovation was applying bidirectional training, considering both left and right context.
BERT was pretrained on the entire English Wikipedia (2.5 billion words) and BookCorpus (800 million words), giving it a deep understanding of patterns, syntax, and semantics.
Start your free trial today and see results within days.
BERT is an encoder stack of the Transformer architecture (uses only the encoder, not the decoder). It consists of multiple layers (12 or 24 Transformer blocks), each with self-attention and feed-forward neural networks.
BERT uses WordPiece tokenization, breaking words into subword units to handle rare/out-of-vocabulary words.
Each input token is represented by the sum of three embeddings:
These help BERT understand both structure and semantics.
Self-attention lets BERT weigh the importance of each token relative to all others in the sequence, capturing dependencies regardless of their distance.
For example, in “The bank raised its interest rates,” self-attention helps BERT link “bank” to “interest rates,” understanding “bank” as a financial institution.
BERT’s bidirectional training enables it to capture context from both directions. This is achieved through two training objectives:
In MLM, BERT randomly selects 15% of tokens for possible replacement:
[MASK]This strategy encourages deeper language understanding.
Example:
[MASK] jumps over the lazy [MASK].”NSP helps BERT understand relationships between sentences.
Examples:
After pretraining, BERT is fine-tuned for specific NLP tasks by adding output layers. Fine-tuning requires less data and compute than training from scratch.
Get latest tips, trends, and deals for free.
BERT powers many NLP tasks, often achieving state-of-the-art results.
BERT can classify sentiment (e.g., positive/negative reviews) with subtlety.
BERT understands questions and provides answers from context.
NER identifies and classifies key entities (names, organizations, dates).
While not designed for translation, BERT’s deep language understanding aids translation when combined with other models.
BERT can generate concise summaries by identifying key concepts.
BERT predicts masked words or sequences, aiding text generation.
In 2019, Google began using BERT to improve search algorithms, understanding context and intent behind queries.
Example:
BERT powers chatbots, improving understanding of user input.
Specialized BERT models like BioBERT process biomedical texts.
Legal professionals use BERT to analyze and summarize legal texts.
Several BERT adaptations exist for efficiency or specific domains:
BERT’s contextual understanding powers numerous AI applications:
BERT has greatly improved chatbot and AI automation quality.
Examples:
BERT enables AI automation for processing large text volumes without human intervention.
Use Cases:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Authors: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Introduces BERT’s architecture and effectiveness on multiple benchmarks, enabling joint conditioning on both left and right context.
Read more
Multi-Task Bidirectional Transformer Representations for Irony Detection
Authors: Chiyu Zhang, Muhammad Abdul-Mageed
Applies BERT to irony detection, leveraging multi-task learning and pretraining for domain adaptation. Achieves 82.4 macro F1 score.
Read more
Sketch-BERT: Learning Sketch Bidirectional Encoder Representation from Transformers by Self-supervised Learning of Sketch Gestalt
Authors: Hangyu Lin, Yanwei Fu, Yu-Gang Jiang, Xiangyang Xue
Introduces Sketch-BERT for sketch recognition and retrieval, applying self-supervised learning and novel embedding networks.
Read more
Transferring BERT Capabilities from High-Resource to Low-Resource Languages Using Vocabulary Matching
Author: Piotr Rybak
Proposes vocabulary matching to adapt BERT for low-resource languages, democratizing NLP technology.
Read more
Smart Chatbots and AI tools under one roof. Connect intuitive blocks to turn your ideas into automated Flows.
Transformers are a revolutionary neural network architecture that has transformed artificial intelligence, especially in natural language processing. Introduced...

A Large Language Model (LLM) is a type of AI trained on vast textual data to understand, generate, and manipulate human language. LLMs use deep learning and tra...
Learn what AI chatbot GPT is, how it works, and why ChatGPT is the leading generative AI solution. Discover transformer architecture, training methods, and real...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.