
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is an advanced AI framework that combines traditional information retrieval systems with generative large language models (...
3 min read
RAG
AI
+4

Question Answering (QA) is a core natural language processing task in which an AI system returns a precise answer to a user’s question stated in natural language. QA systems span extractive, abstractive, open-domain, and closed-domain approaches and are evaluated on benchmarks such as SQuAD, Natural Questions, and TriviaQA.
Question Answering (QA) is the natural language processing task of returning a precise, natural-language answer to a question — not a ranked list of documents. It is one of the oldest and most studied tasks in NLP and underpins answer boxes in search, voice assistants, customer-support copilots, and modern LLM-powered applications.
Search and QA solve different problems. Search returns what to read; QA returns the answer. As users move from typing keywords into search engines to asking questions of voice assistants and chatbots, the QA task has become the default user expectation. Mature QA systems combine retrieval, reading comprehension, reasoning, and generation to produce answers that are correct, well-attributed, and concise.
QA systems are typically classified along two axes:
Modern QA stacks often combine these: an open-domain extractive reader for short factual answers, an abstractive generator for explanatory answers, and routing logic to pick the right approach per query.
Start your free trial today and see results within days.
Question answering is the task; Retrieval-Augmented Generation (RAG) is one technique commonly used to implement it. A RAG-based QA system retrieves supporting passages from a knowledge base and conditions an LLM on them so it can produce grounded answers. QA, however, is broader than RAG — it also includes:
Choosing the right approach depends on whether grounding to up-to-date sources is required, how broad the question scope is, and whether answers must be auditable.
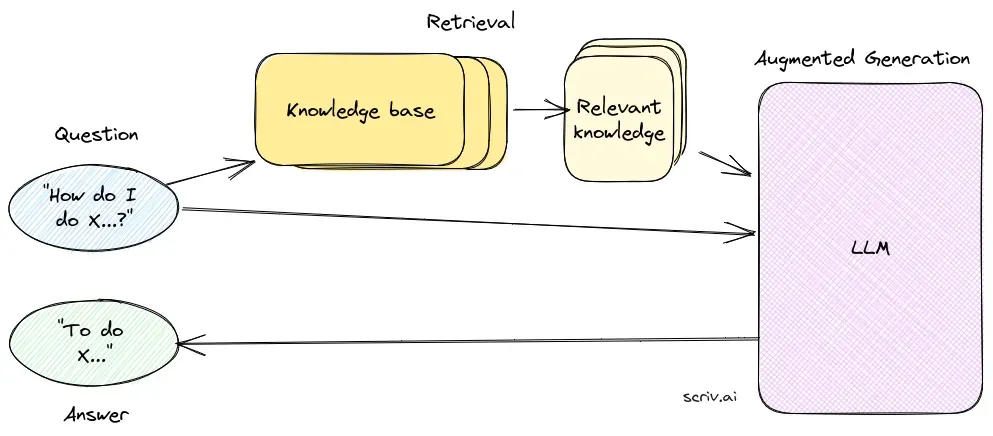
A production QA system, regardless of whether it’s RAG-backed or closed-book, has the same task-shaped components:
When QA is implemented with retrieval, the retrieval and generation specifics — vector databases, semantic search, embeddings, prompt templates — belong to the technique, not the task. For the full architecture and trade-offs, see Retrieval-Augmented Generation (RAG) .
Get latest tips, trends, and deals for free.
QA systems are typically evaluated on benchmark datasets and standard metrics:
Common metrics include exact match (EM), F1 (token overlap), ROUGE/BLEU for long-form generation, and faithfulness/citation-accuracy metrics for RAG-style systems.
QA is the visible answer-shaped layer in many products: search-engine answer boxes, voice assistants (Siri, Alexa, Google Assistant), customer-support copilots, internal knowledge bots over enterprise wikis, educational tutors, and any chatbot that needs to deliver a direct response rather than a list of links. The choice of QA approach (extractive reader, abstractive LLM, RAG, knowledge-graph) is mostly driven by whether the answer must be auditable, whether the knowledge changes, and how broad the question scope is.
For implementation patterns when retrieval is required — chunking, vector storage, semantic search, generator integration — refer to the Retrieval-Augmented Generation (RAG) entry; this glossary page intentionally stays at the task level.
Research on Question Answering with Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a method that enhances question-answering systems by combining retrieval mechanisms with generative models. Recent research has explored the efficacy and optimization of RAG in various contexts.
Discover how Retrieval-Augmented Generation can boost your chatbot and support solutions with real-time, accurate responses.
Retrieval Augmented Generation (RAG) is an advanced AI framework that combines traditional information retrieval systems with generative large language models (...
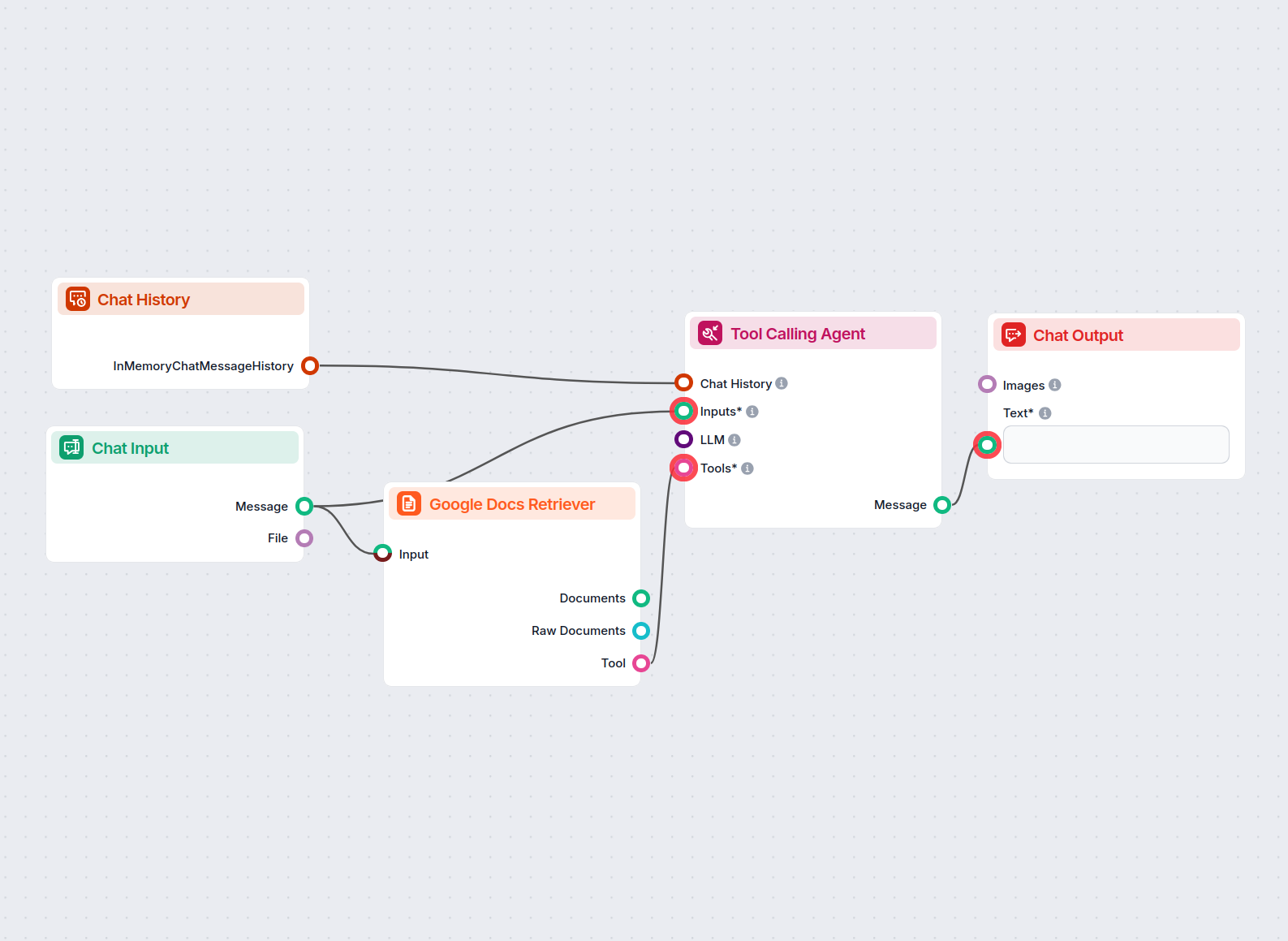
An AI-powered chatbot that provides precise answers to user questions based strictly on the content from a supplied Google Document. Ideal for research, content...
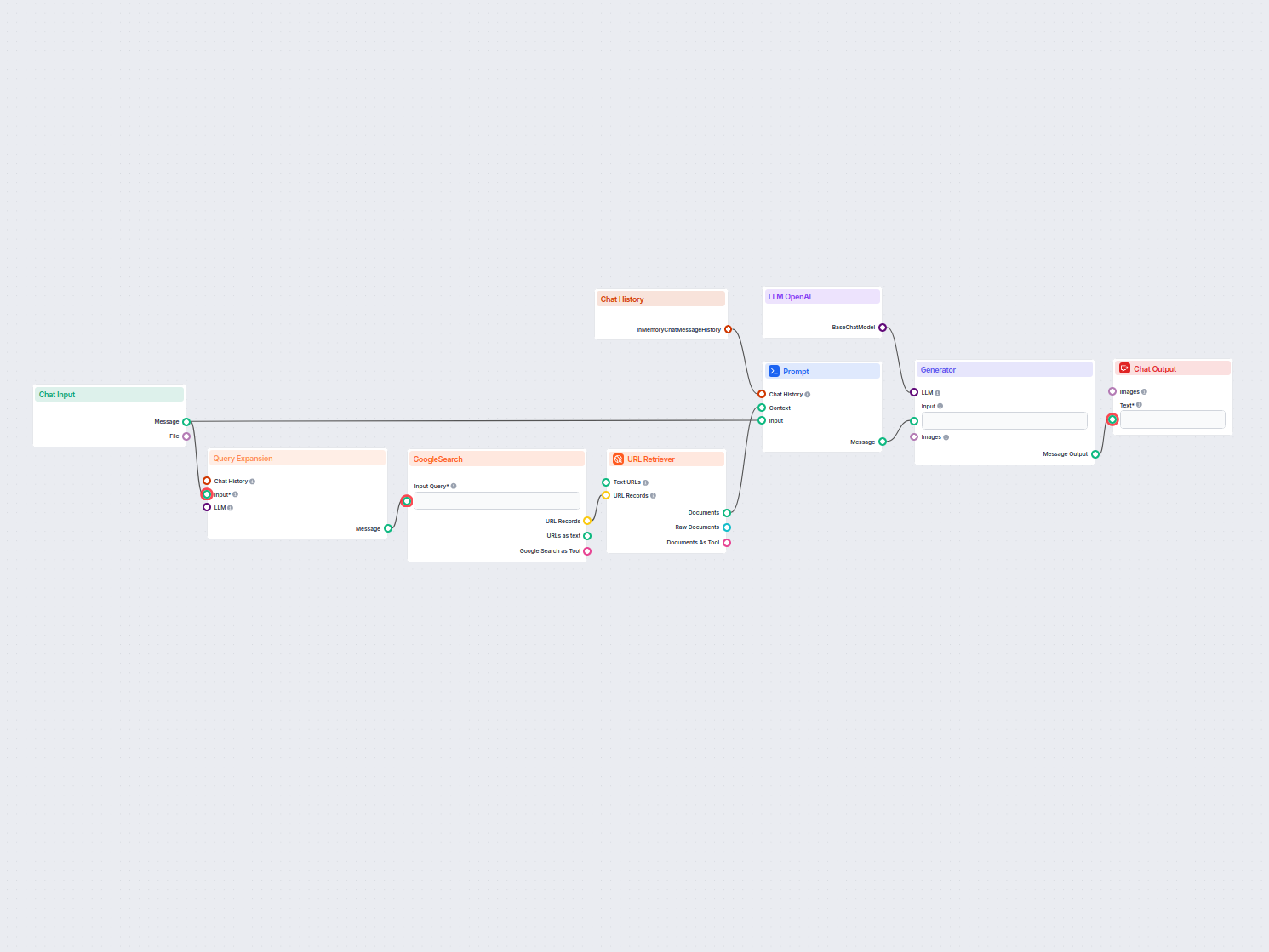
A real-time chatbot that uses Google Search restricted to your own domain, retrieves relevant web content, and leverages OpenAI LLM to answer user queries with ...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.