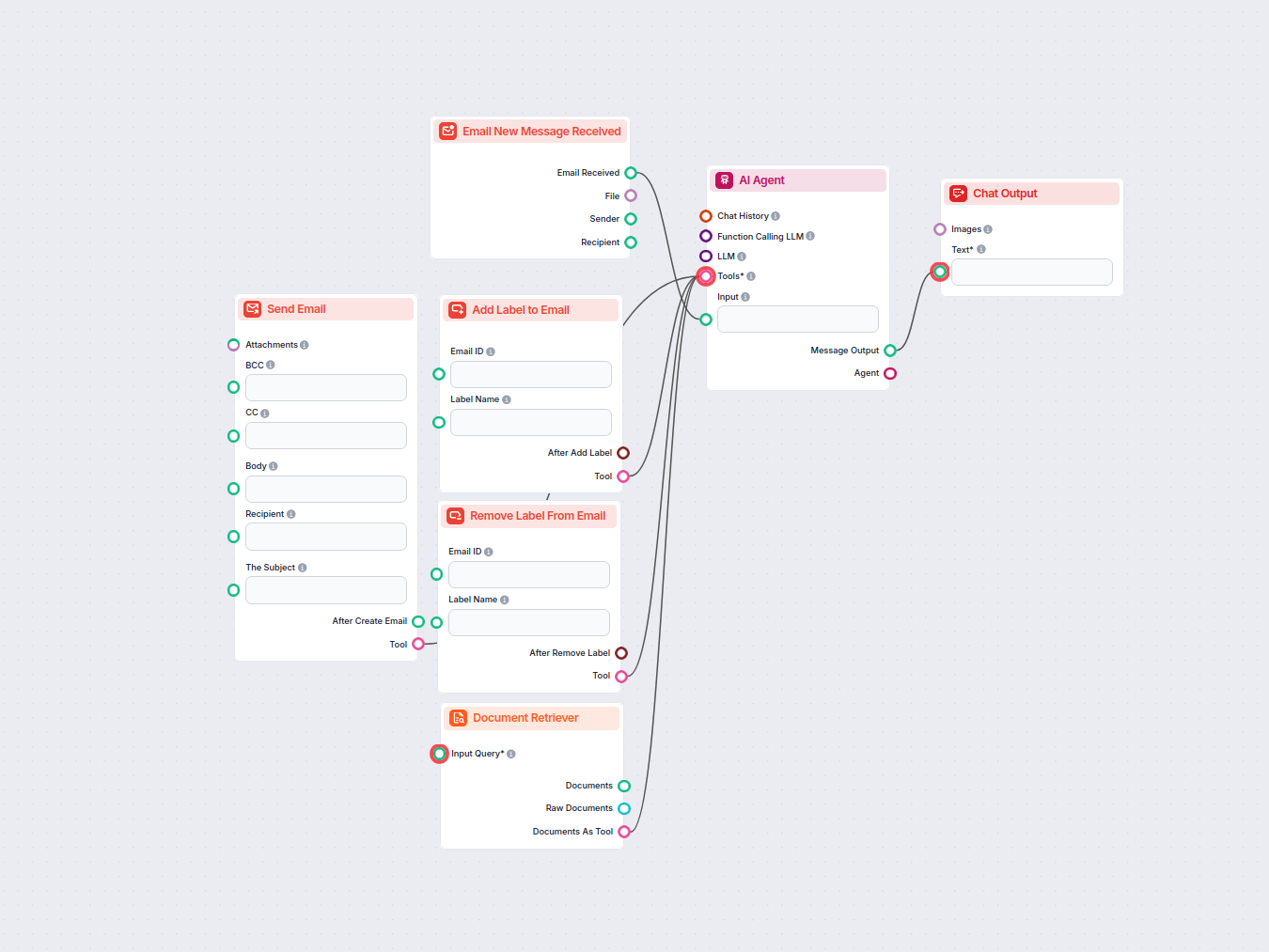
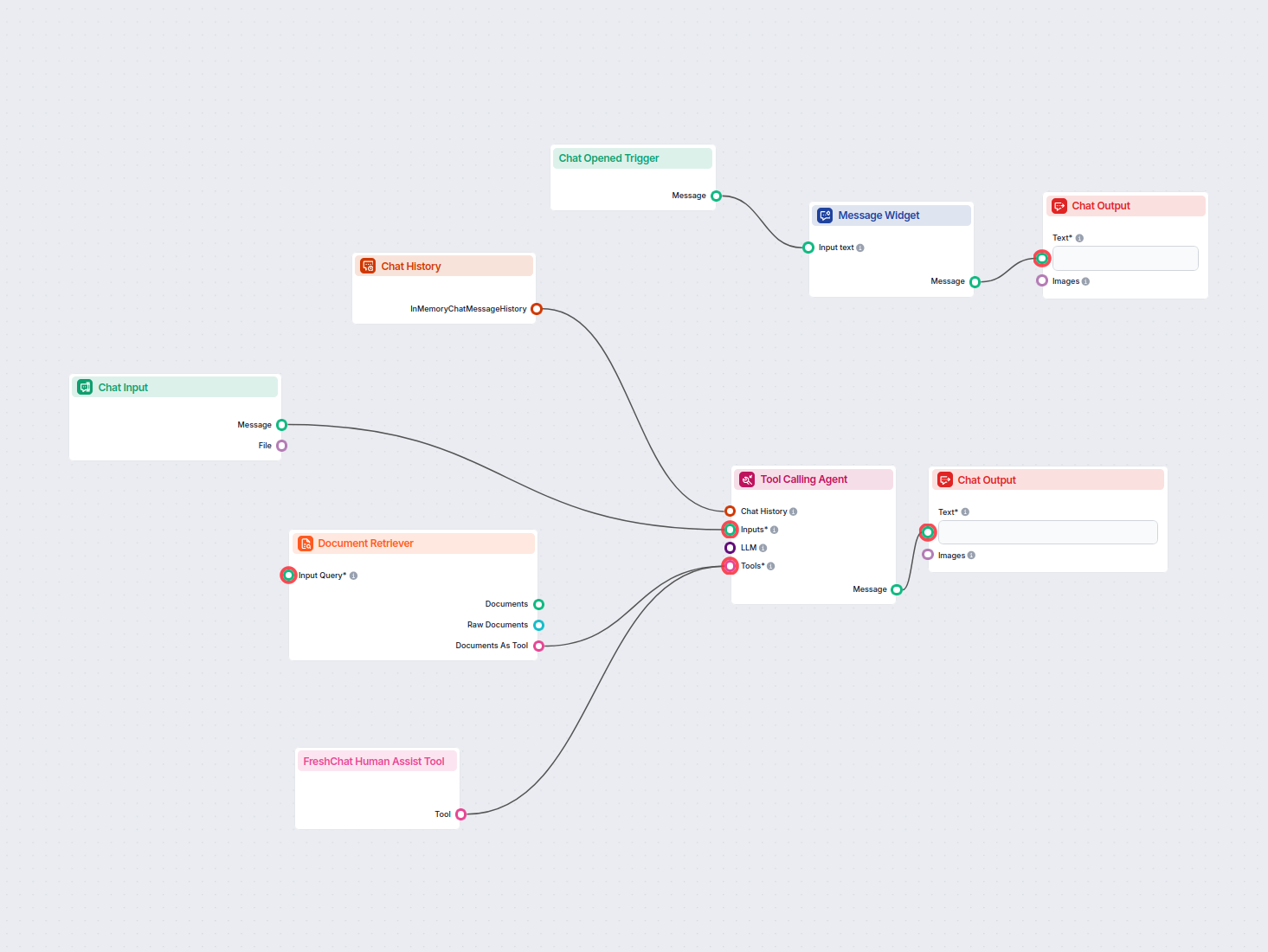
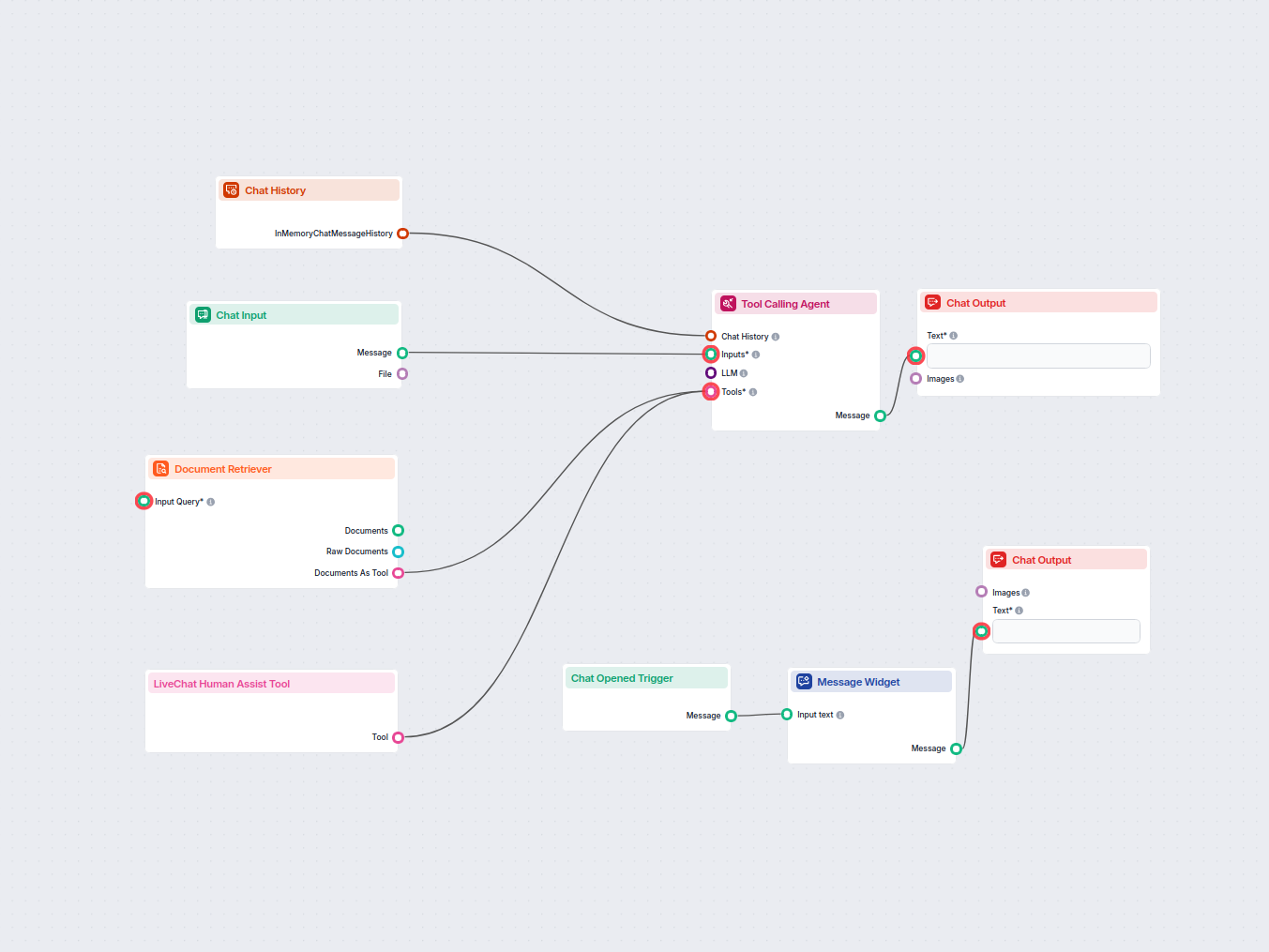
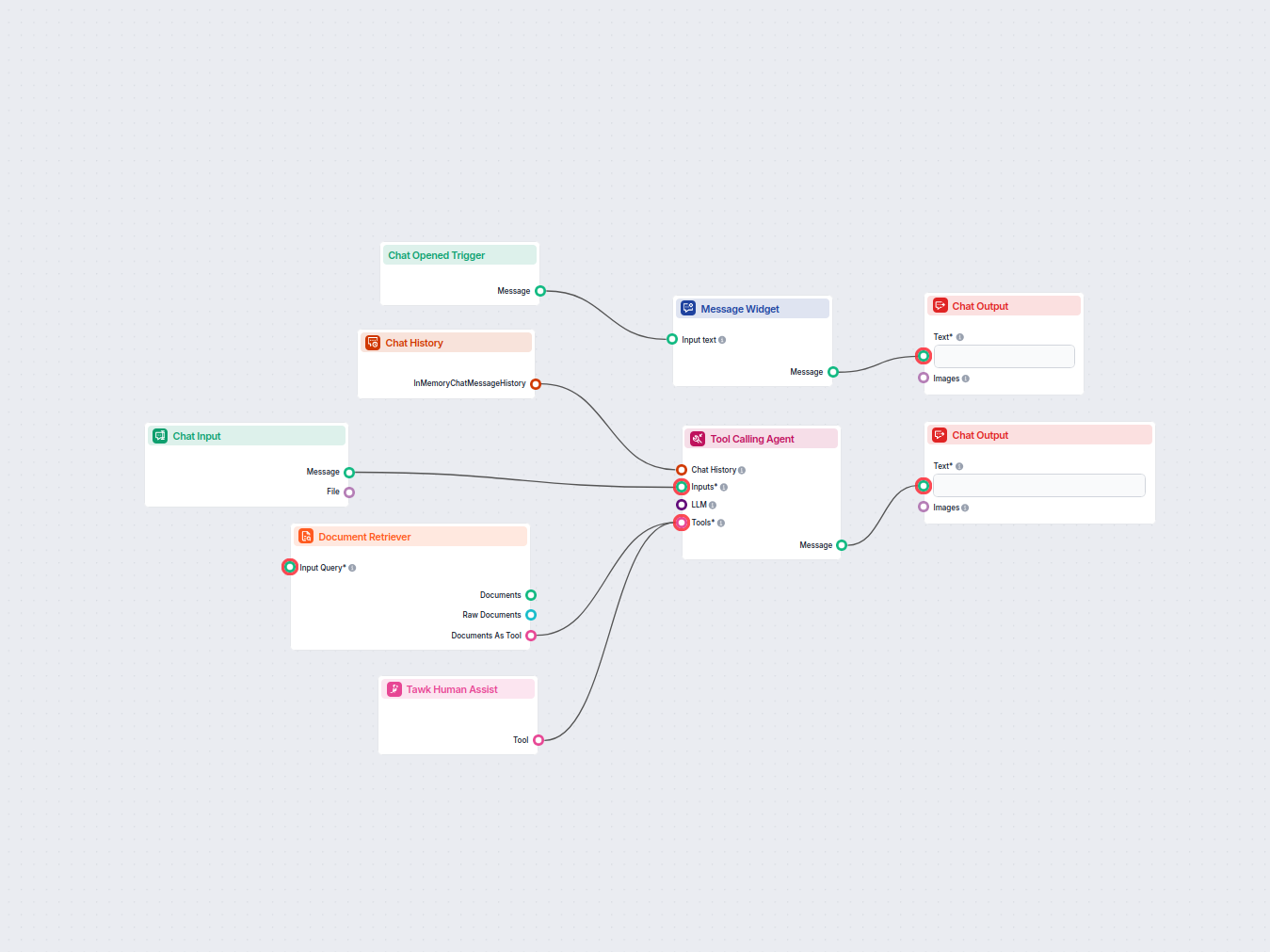
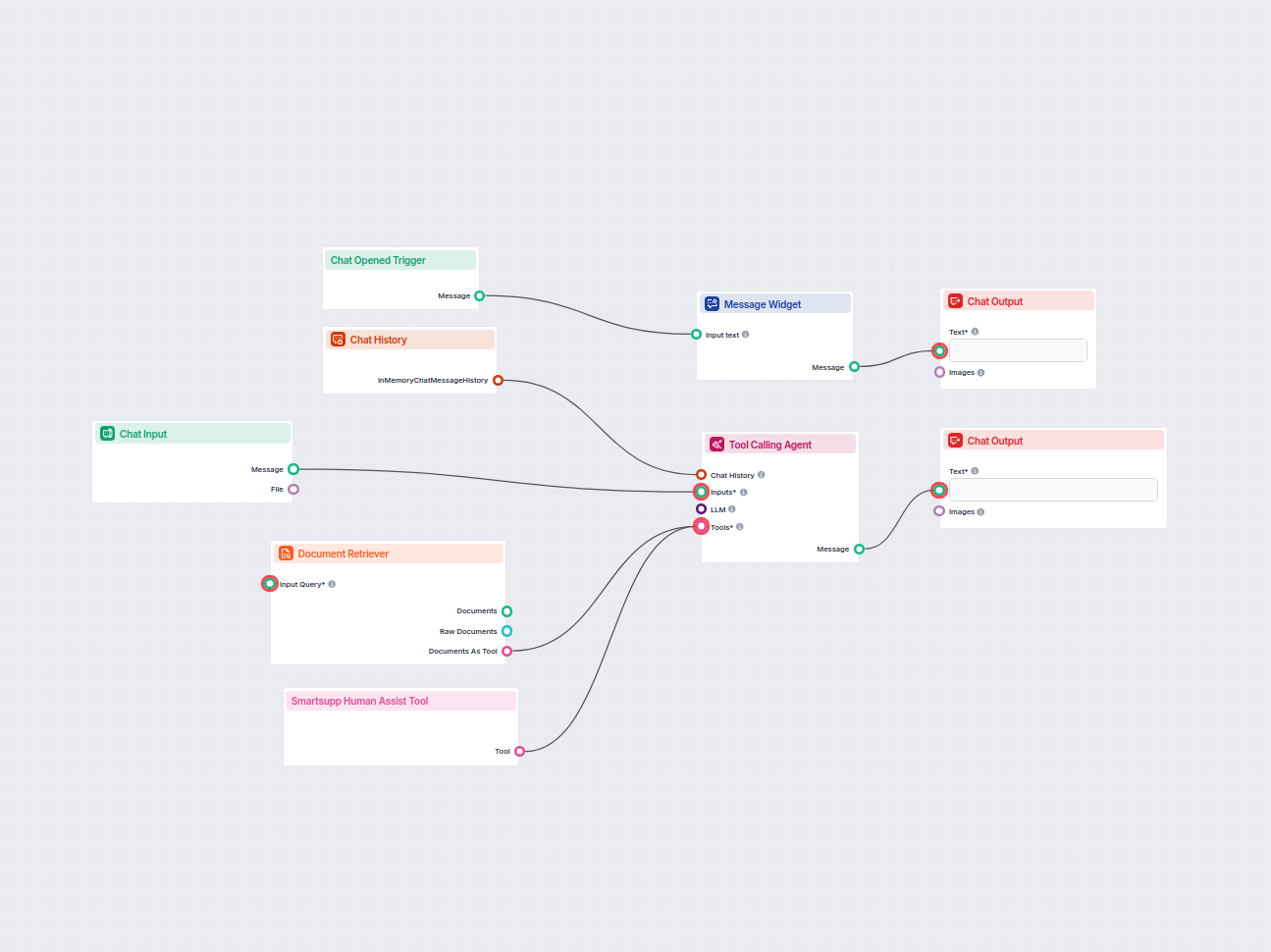
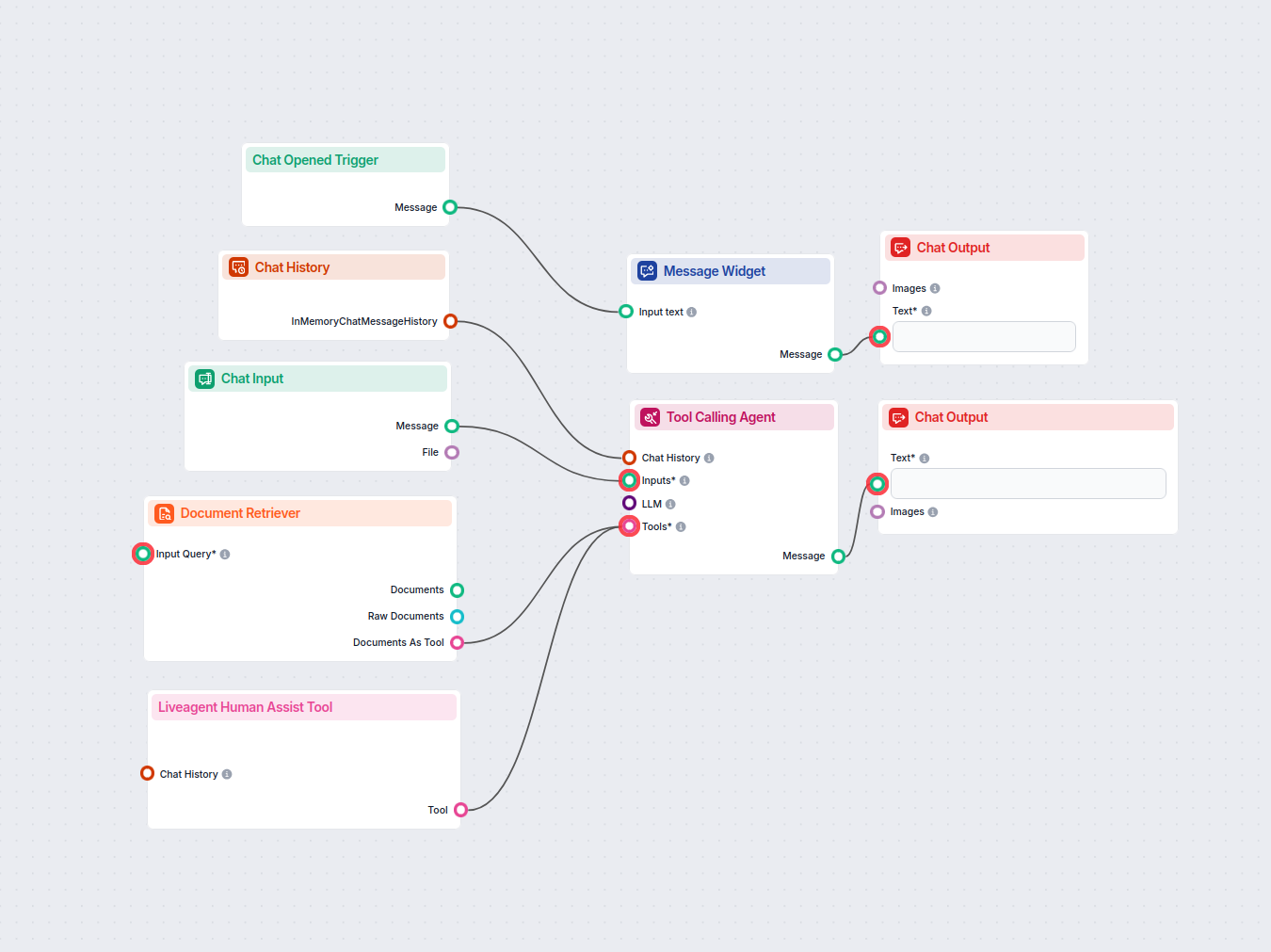
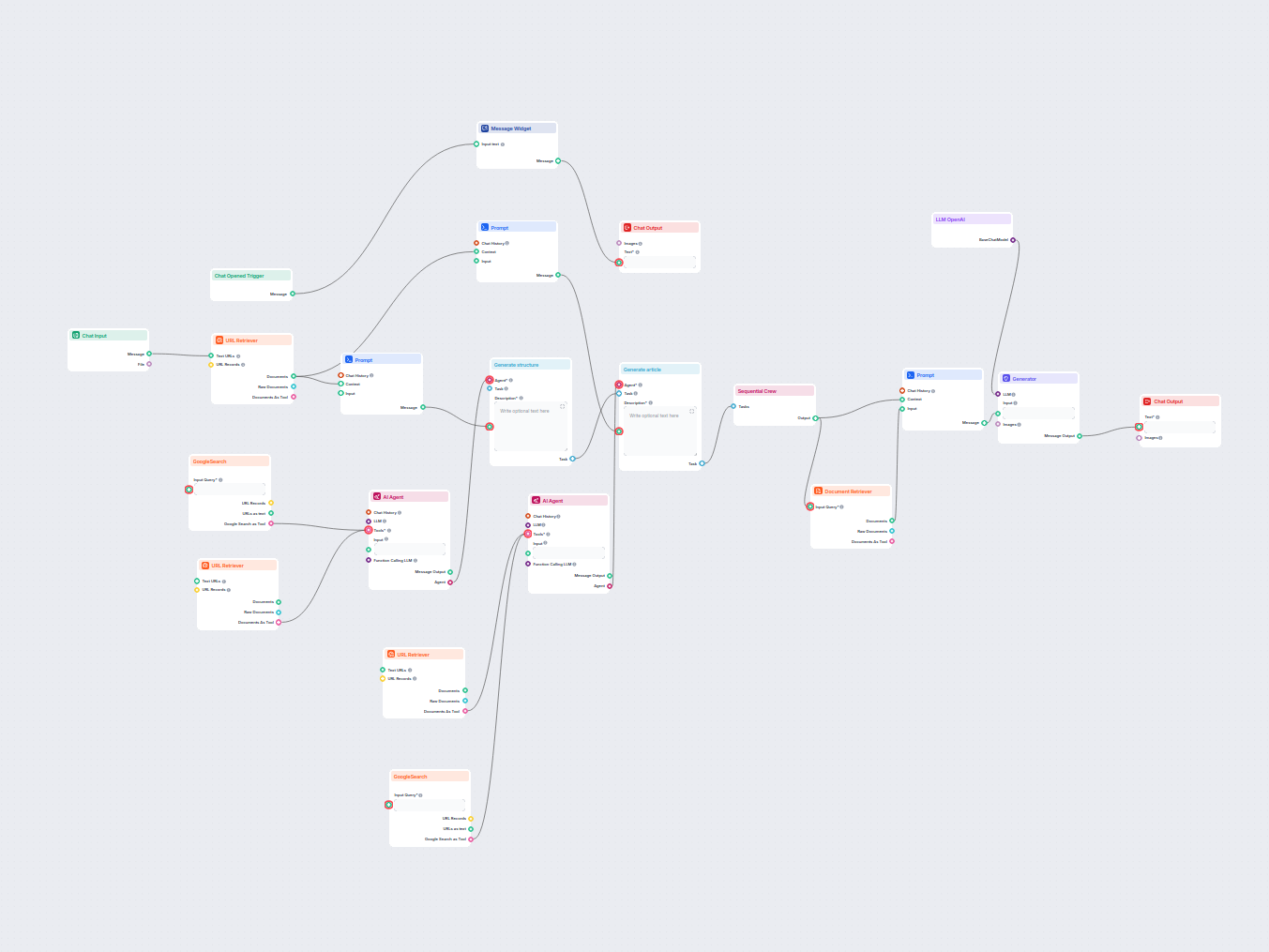
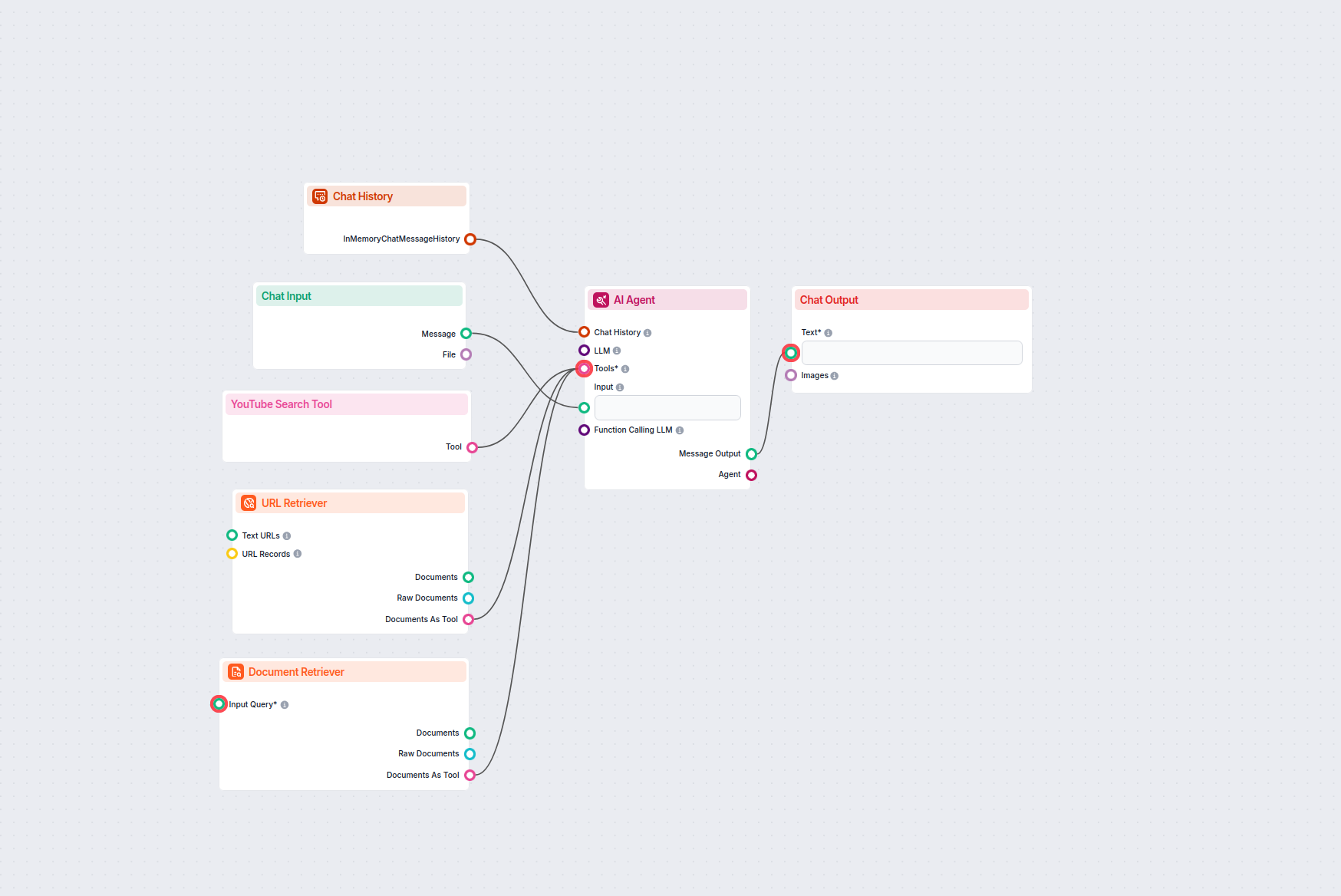
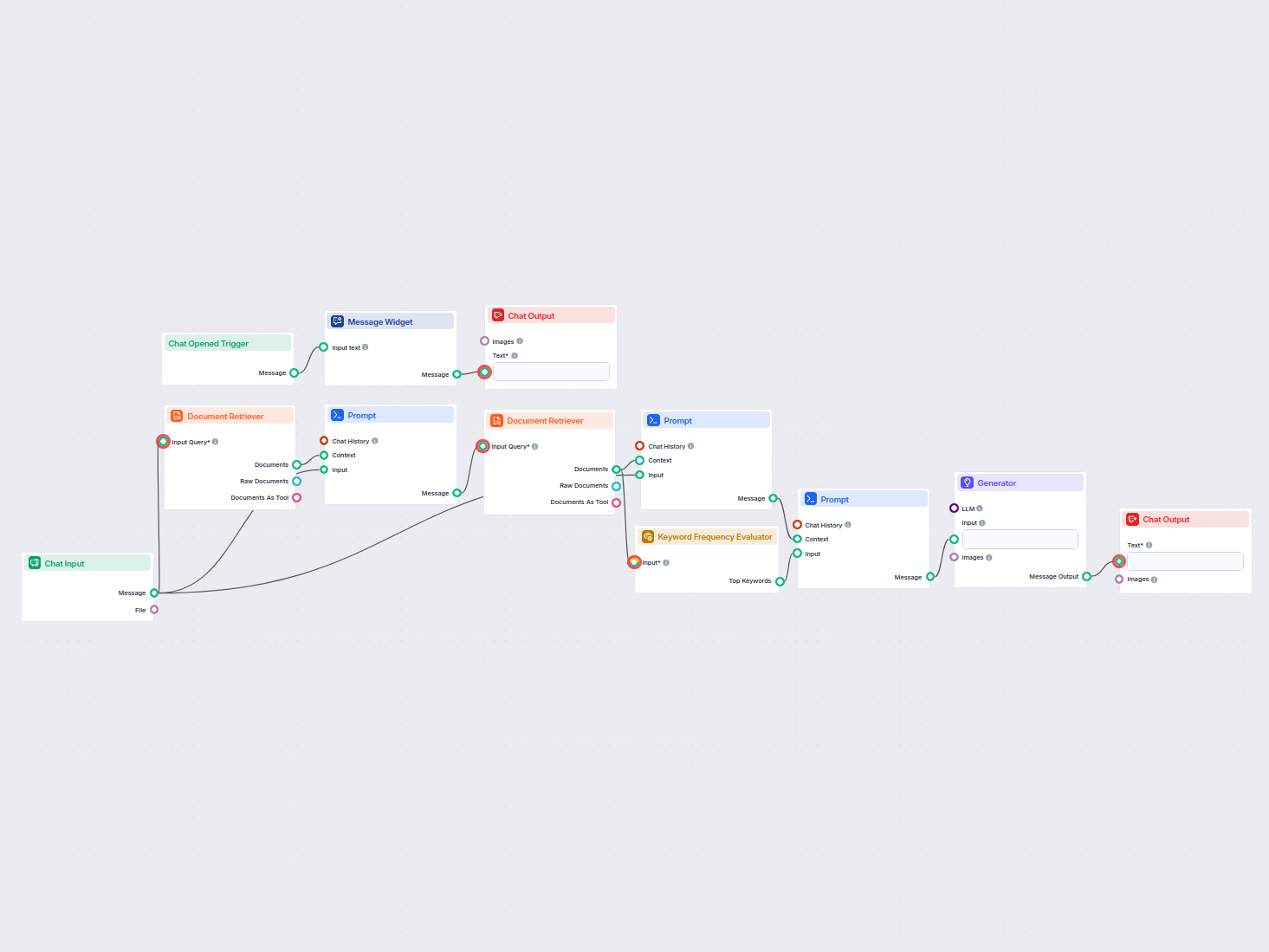
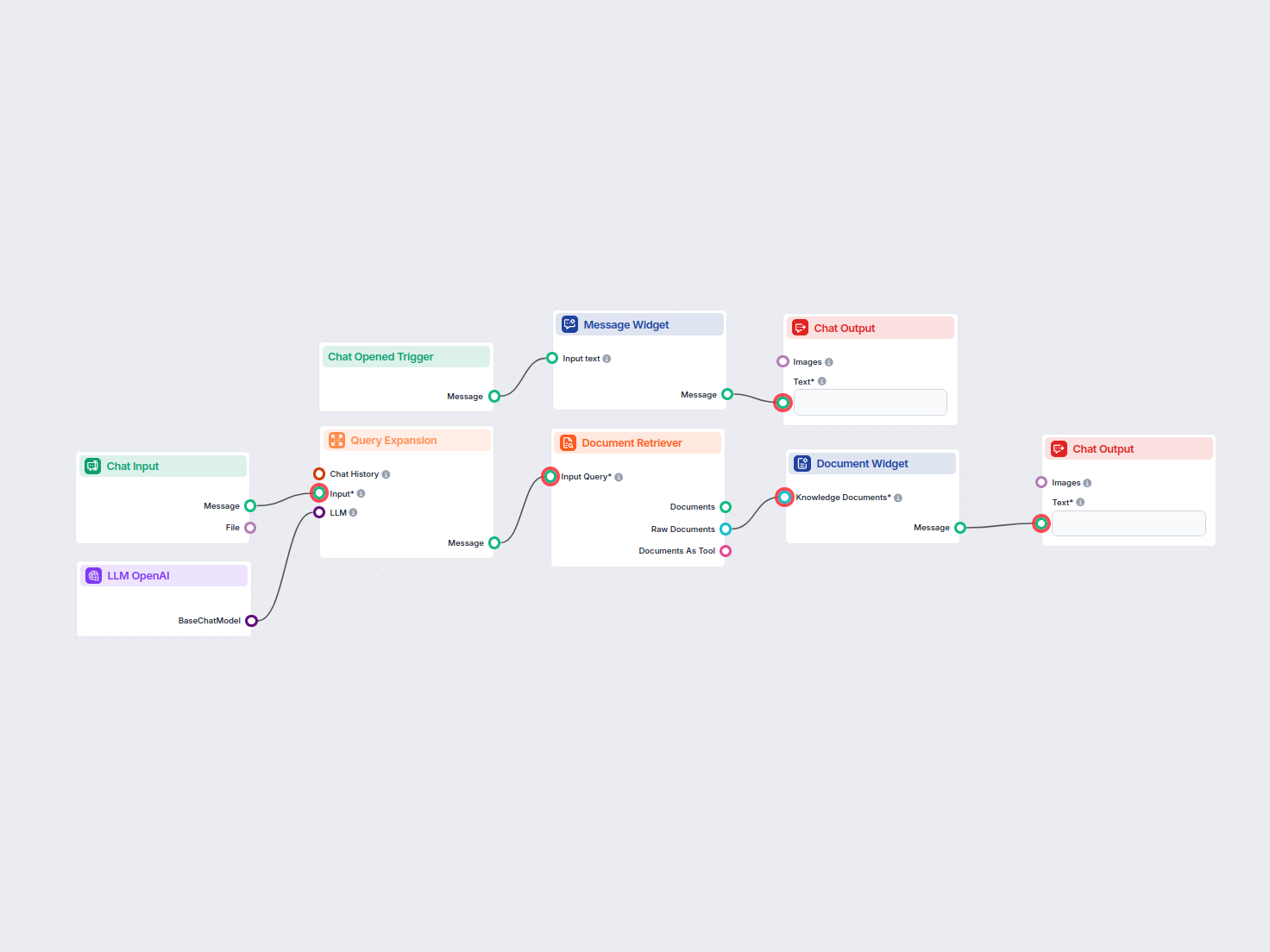
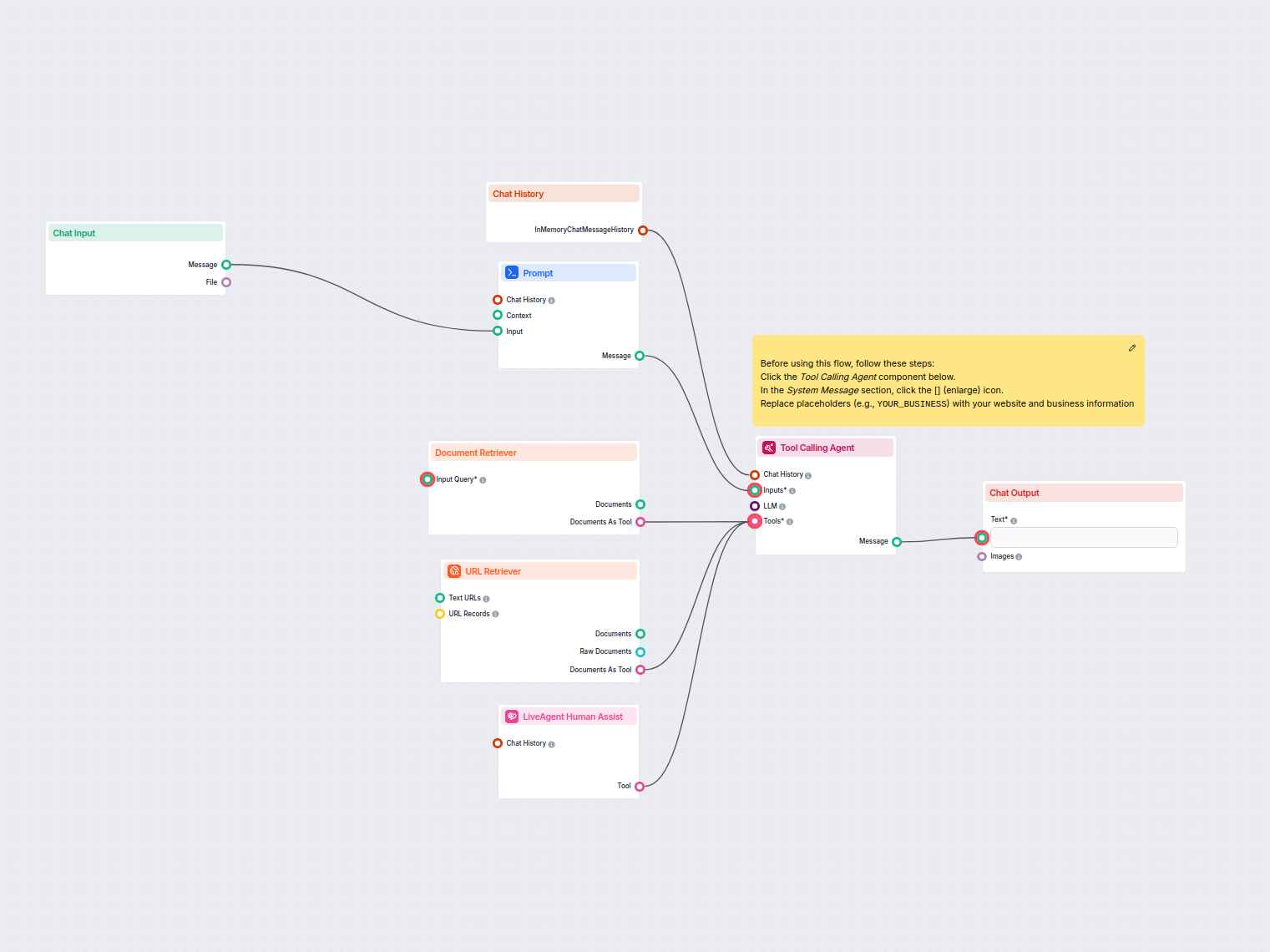
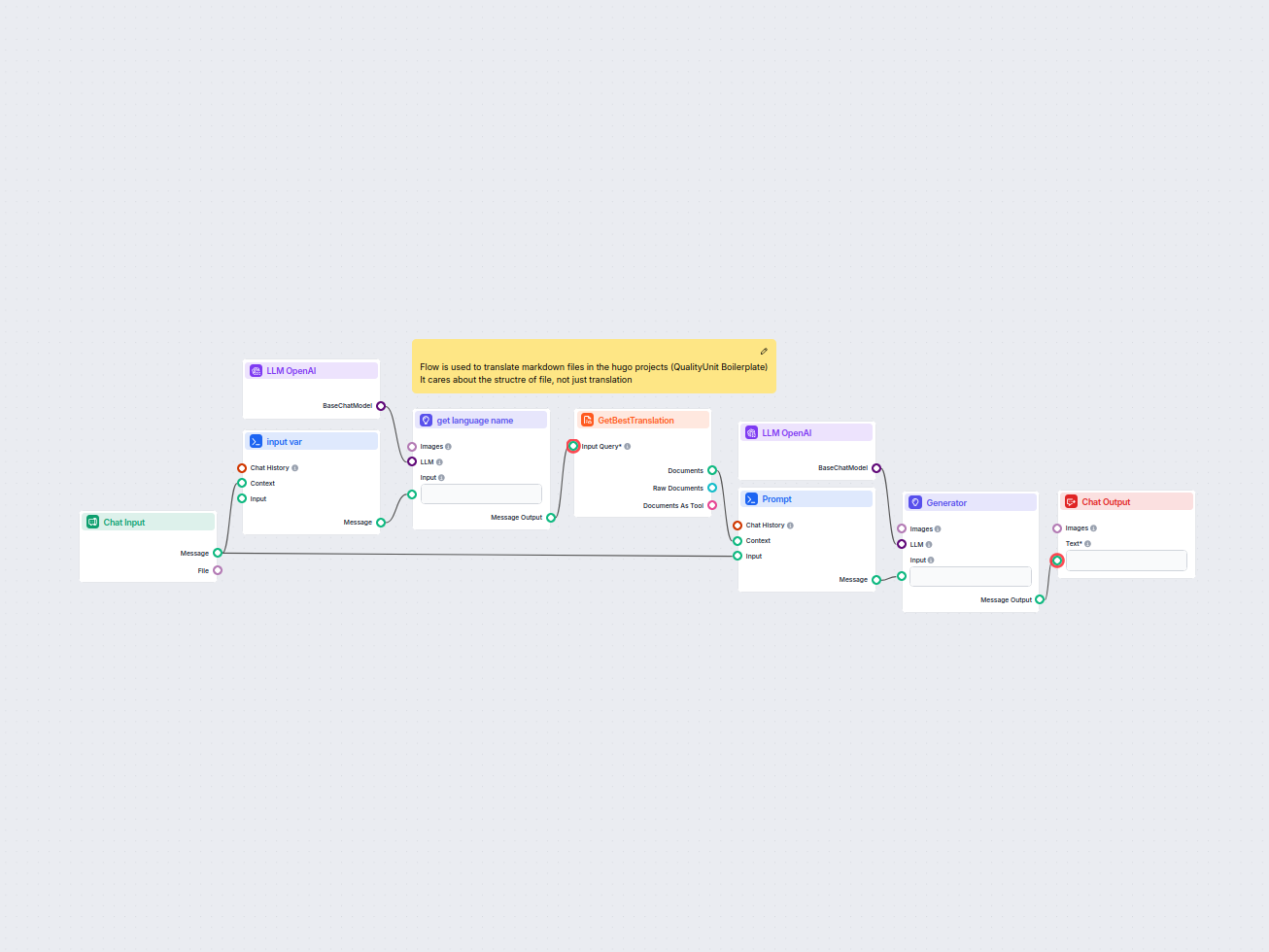
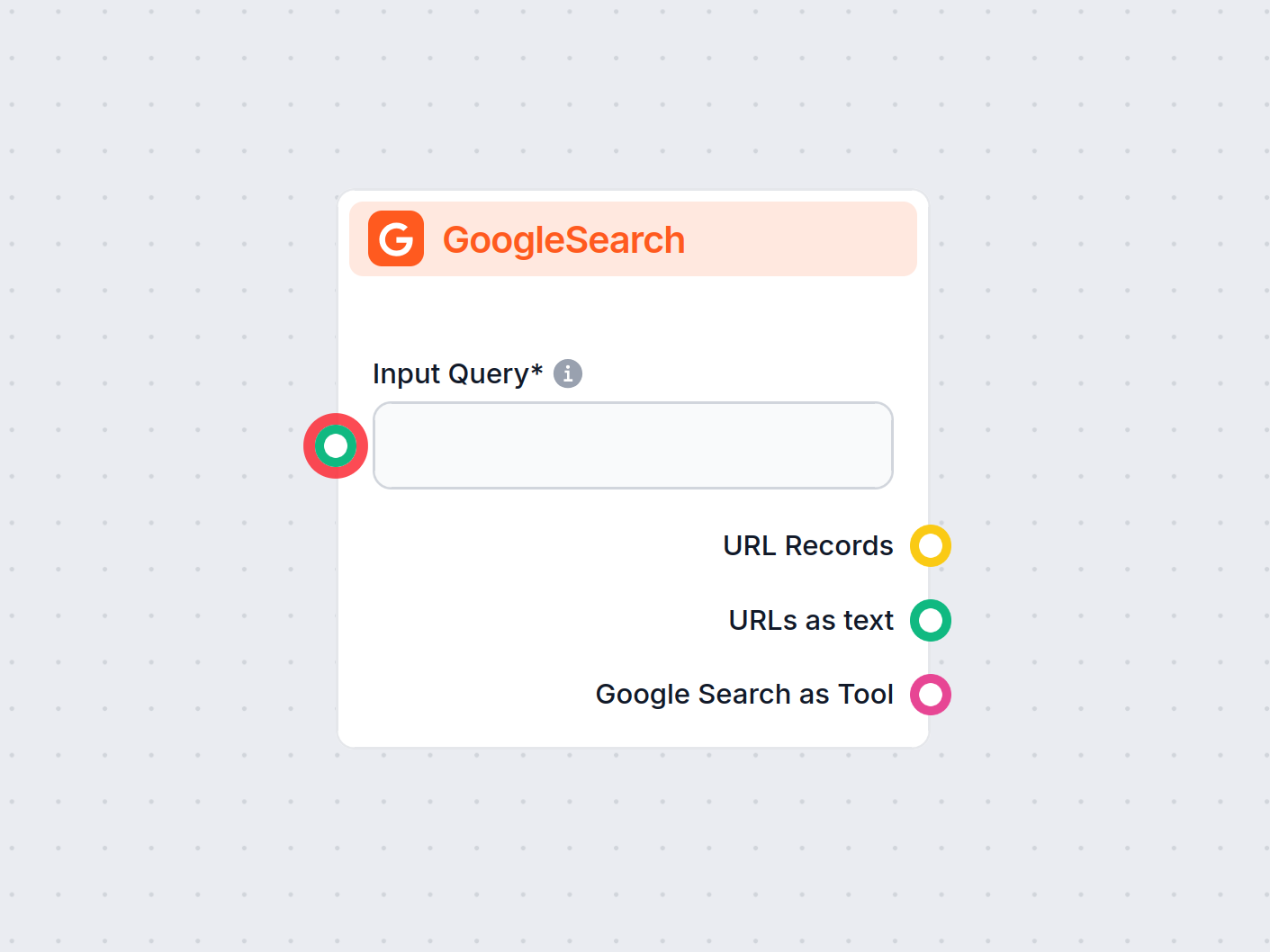
Document Retriever collega i modelli AI ai documenti e agli URL che scegli, consentendo risposte AI accurate, aggiornate e pertinenti per il tuo caso d’uso specifico.
AI
Document Retrieval
Knowledge Management
RAG
Components
Descrizione del componente
Come funziona il componente Document Retriever
The most significant setback of large language models is their tendency to present vague, outdated, or downright false information. To ensure the answers are always up to date and relevant to your use case, generative models need to be pointed to the right knowledge sources.
This approach, called the Retrieval-Augmented Generation (RAG), supplies generative models with your own knowledge sources. The retriever components, including the Document Retriever, allow you to use this method.
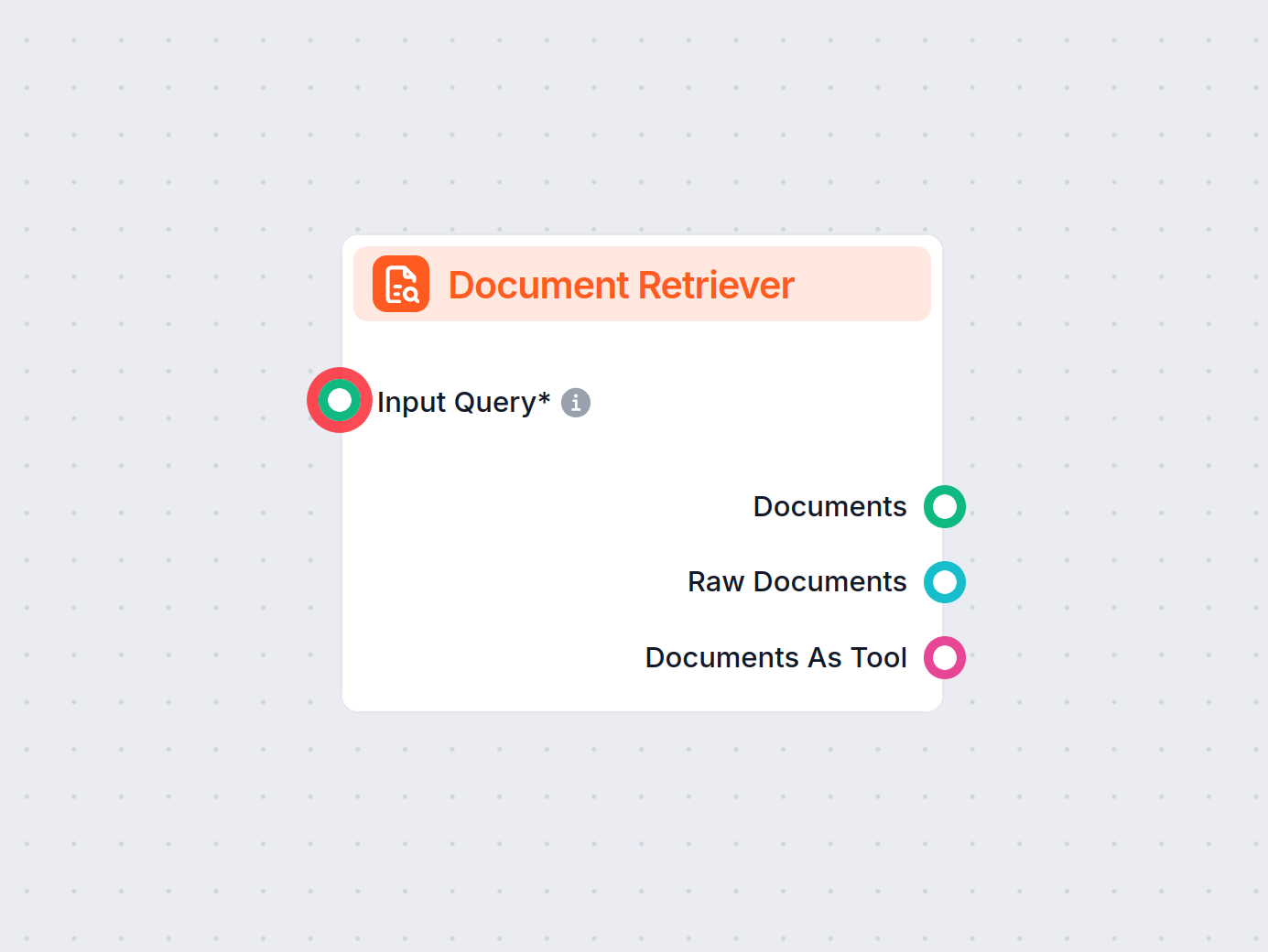
What is the Document Retriever component?
This component allows the chatbot to retrieve knowledge from your own sources, ensuring that the information is relevant, reliable, and up-to-date. This information comes directly from the sources you specified in the Documents and Schedules. The role of this component is to control the retrieval.
Input Query
Specifies the query that’s used to look up relevant information. It can either be linked from a component or inputted manually. In most cases, your input query will be the Chat Input.
Document Count
This setting limits the amount of documents the flow should retrieve from, making sure the results remain relevant and don’t take too long to generate.
Document categories
This optional setting lets you limit the retrieval to one of the categories you’ve created in the Documents screen of Knowledge Sources.
Schedules
Lets you limit the retrieval to one of the Schedules you’ve specified in the Schedules screen of Knowledge Sources.
Threshold
The sources in your knowledge database will match the query to varying degrees. AI will rank these by relevance from 0 to 1. This setting lets you control how well the output must match the query.
The exact threshold depends on your use case, but generally, 0.7-0.8 is recommended for highly relevant answers from a reasonable amount of sources.
Imagine you set the threshold to 0.6 and have the following articles:
Article A: 0.8
Article B: 0.65
Article C: 0.5
Article D: 0.9
Only the articles with a relevance score of over 0.6 will make it into the output, that is, only A, B, and D.
A high threshold, such as 0.9, will return very relevant results that closely match the query, but it might struggle to find enough documents and miss some relevant ones.
A low threshold, for example, one below 0.5, will provide information from more documents, but it runs the risk of returning irrelevant information.
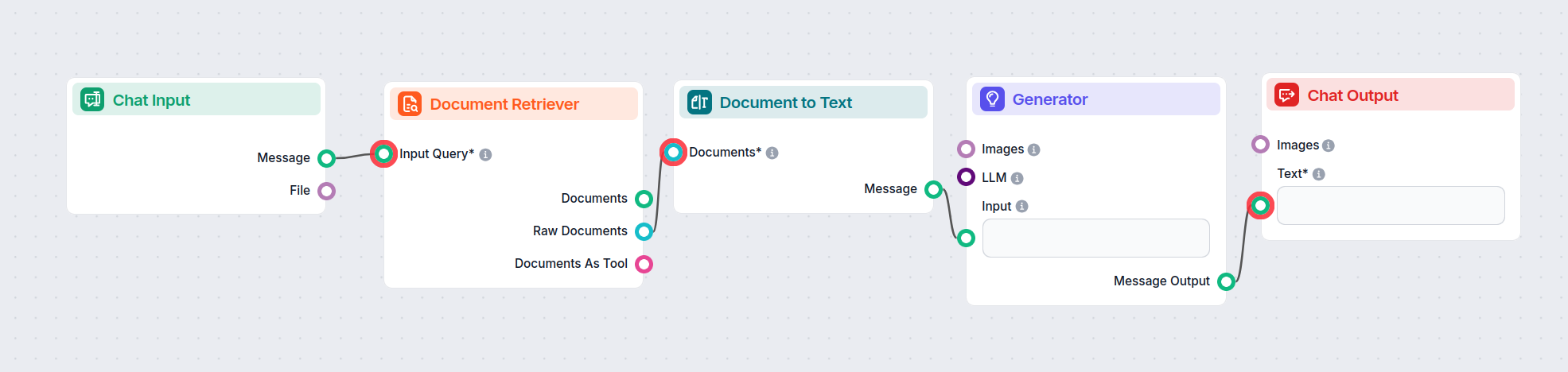
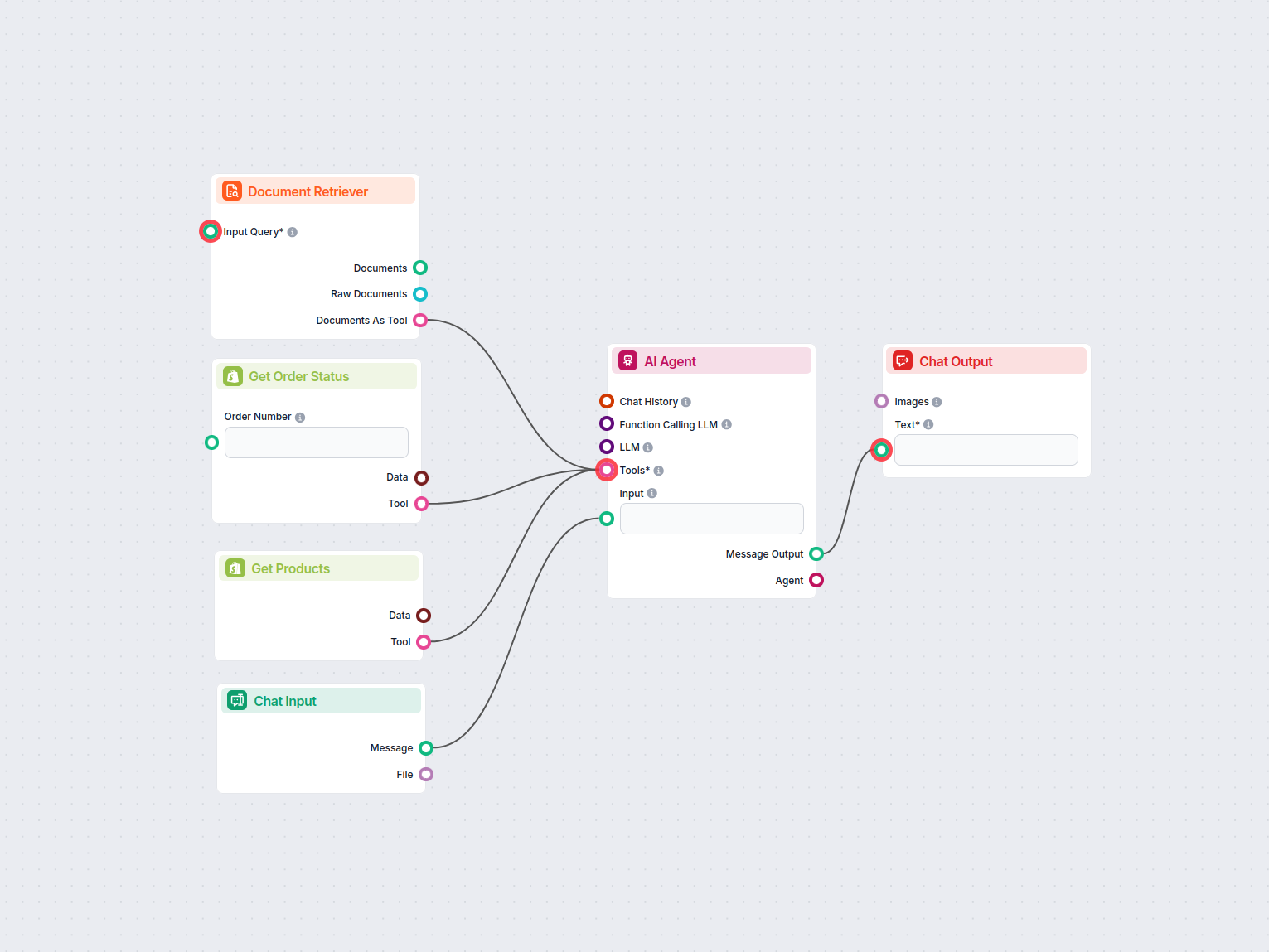
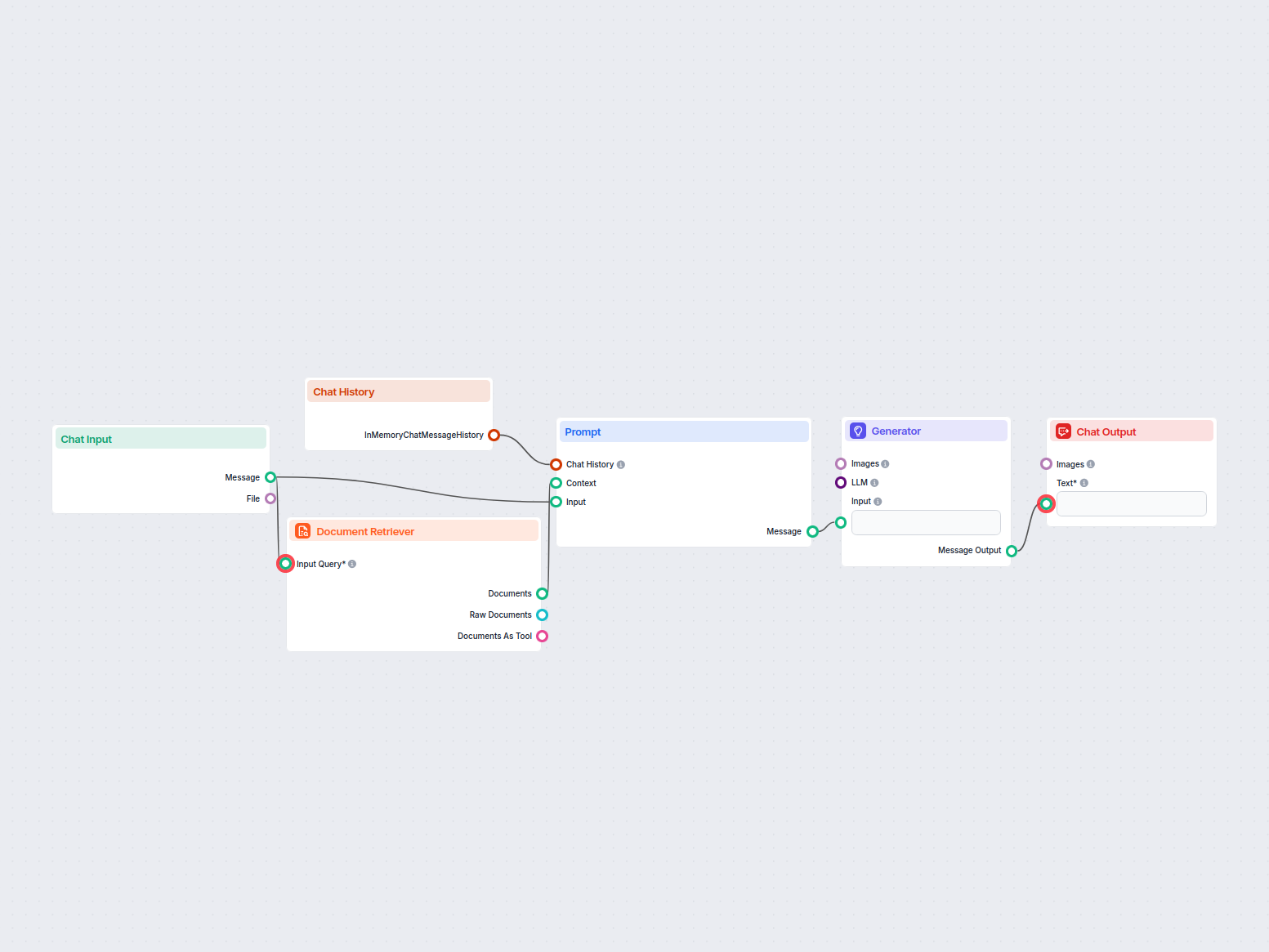
How to connect the Document Retriever component to your flow
The component contains just one input and one output handle:
Input Query: The query can be any text output. Common use cases would be connecting human Chat Input or a Generator.
Output: The output of any retriever-type component is always a Document.
The Document output contains structured data unsuitable for the final chat output. All components that take Documents as their input transform them into a user-friendly format. These are either Widget components or the Document to Text transformer.
Why Use the Document Retriever?
Grounding AI Models: Enhance the factual accuracy and relevance of AI outputs by providing real, contextual information from your organization’s knowledge base.
Contextual Augmentation: Supply LLMs or chatbots with supporting documents or reference material for more informed responses.
Flexible Filtering: Search can be fine-tuned by category, schedule, URL, document structure, or metadata, ensuring you surface only the most relevant information.
Custom Output: Choose how much content to retrieve, how to split it, and which metadata to include, making it easy to adapt for downstream AI processes or UI needs.
Agent Integration: With tool descriptions and naming, the component can be referenced as a tool in agent-based architectures.
Example Use Cases
Retrieval-Augmented Generation (RAG): Provide LLMs with supporting documents to generate accurate, knowledge-backed responses.
Chatbots and Virtual Assistants: Quickly surface FAQs or policy documents in response to employee/customer questions.
Data Enrichment: Pull in product, author, or other metadata for further AI-driven analysis or workflow automation.
Example
Let’s Try it Now! Before building the flow, we must ensure we have created relevant Documents or Schedules. If no good source is present, the chatbot will either apologize for being unable to answer.
Steps:
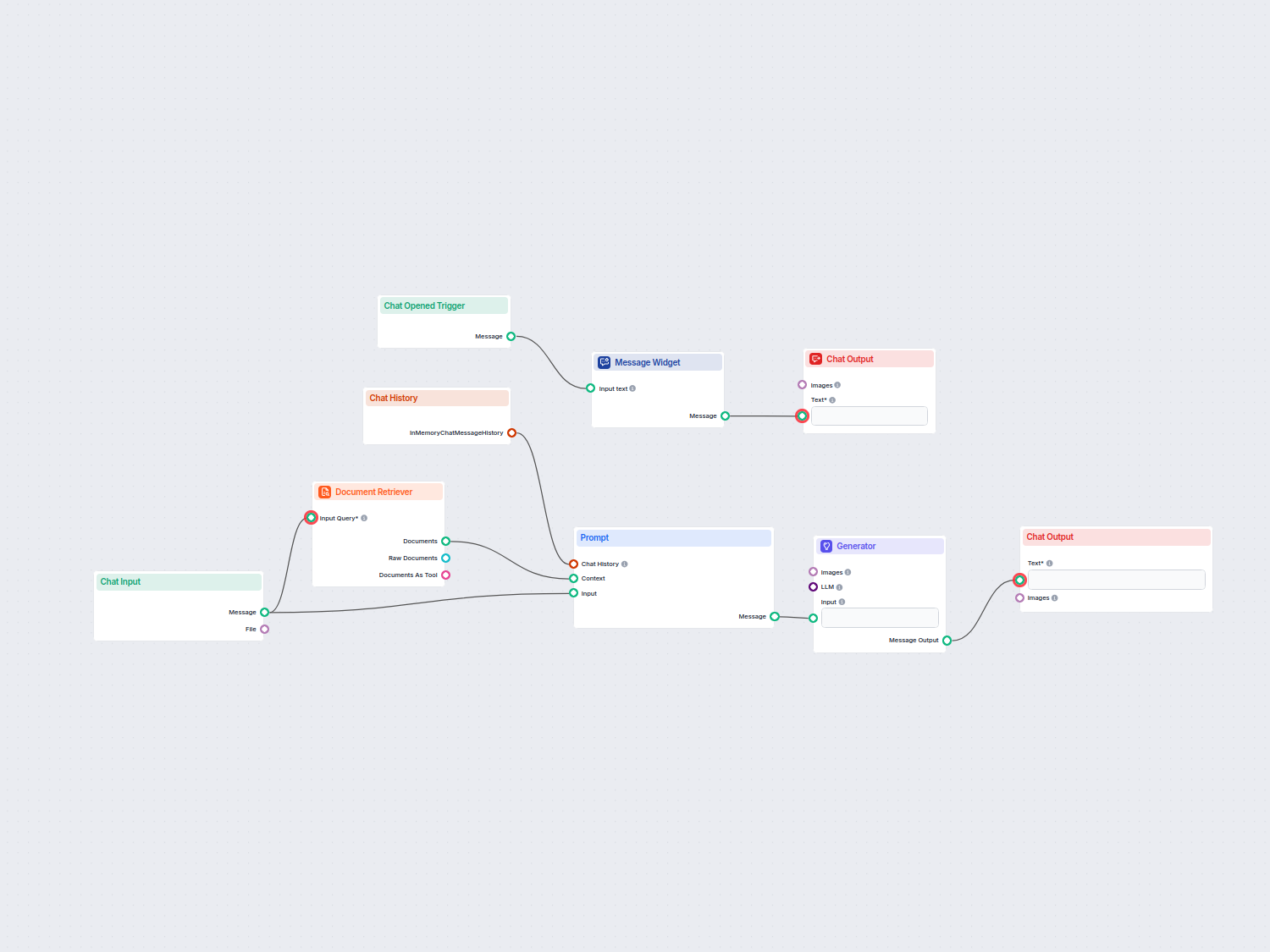
Start with Chat Input.
Add the Document Retriever and connect Chat Input as the Input Query.
The output is a Document that needs to be transformed; for this example, we will use the Document to Text.
Next, connect an AI Generator.
You’re ready to chat.
Now our Flow can search our sources based on a human query, transform the structured data into readable text, and pass it to AI to generate a user-friendly answer.
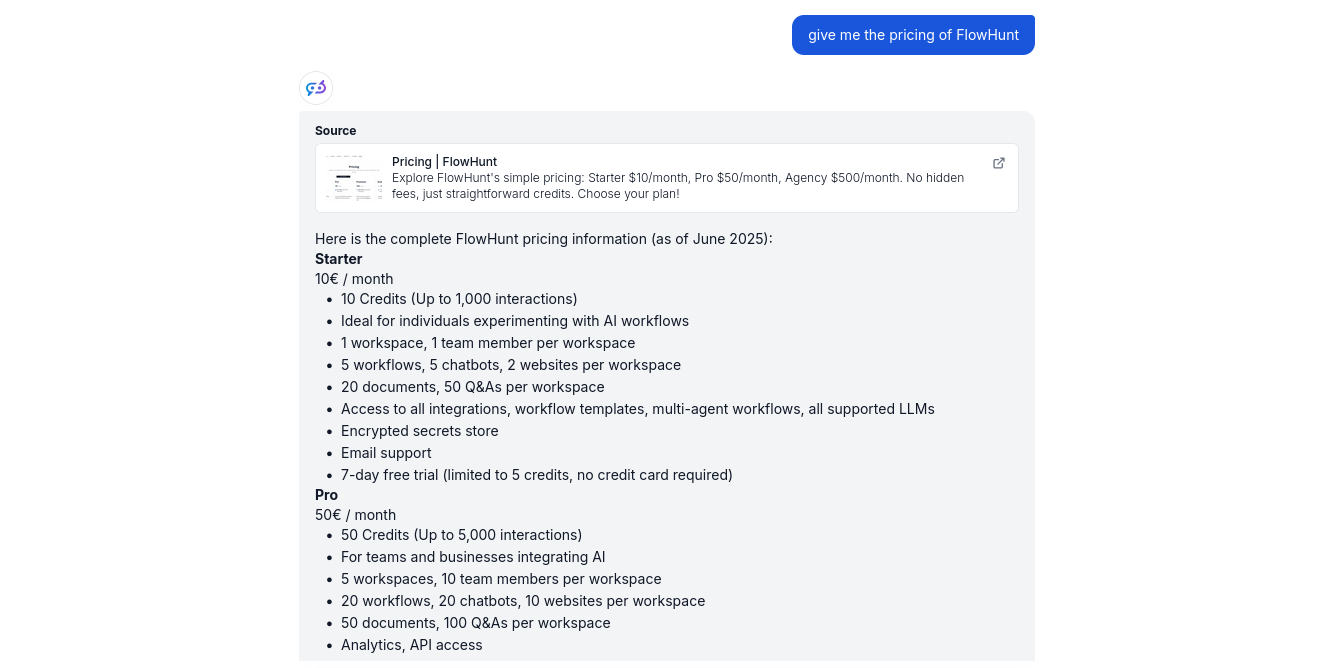
Our Knowledge Sources contain a Schedule set to crawl FlowHunt’s pricing page for up-to-date information. Let’s ask the bot about it:
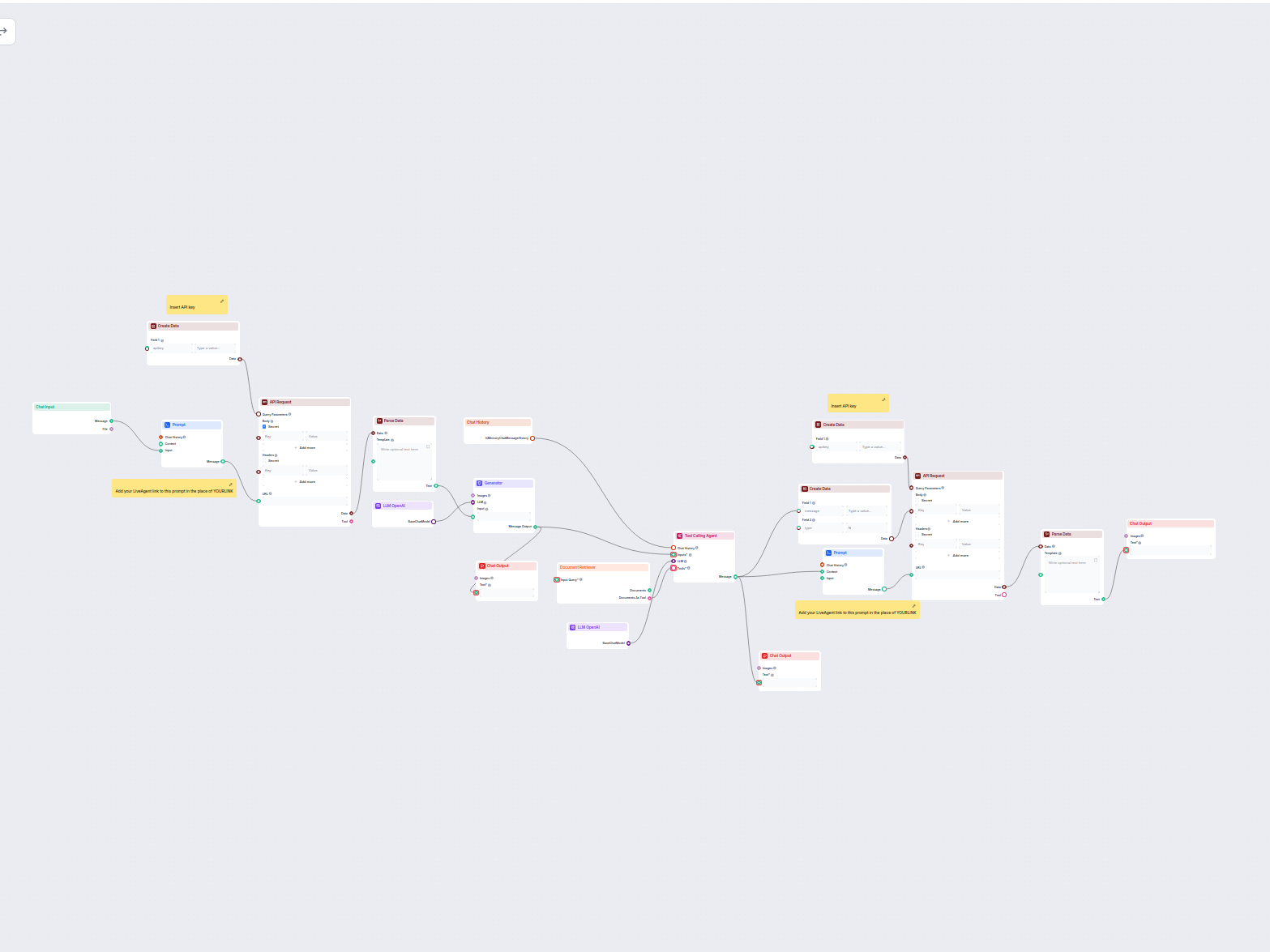
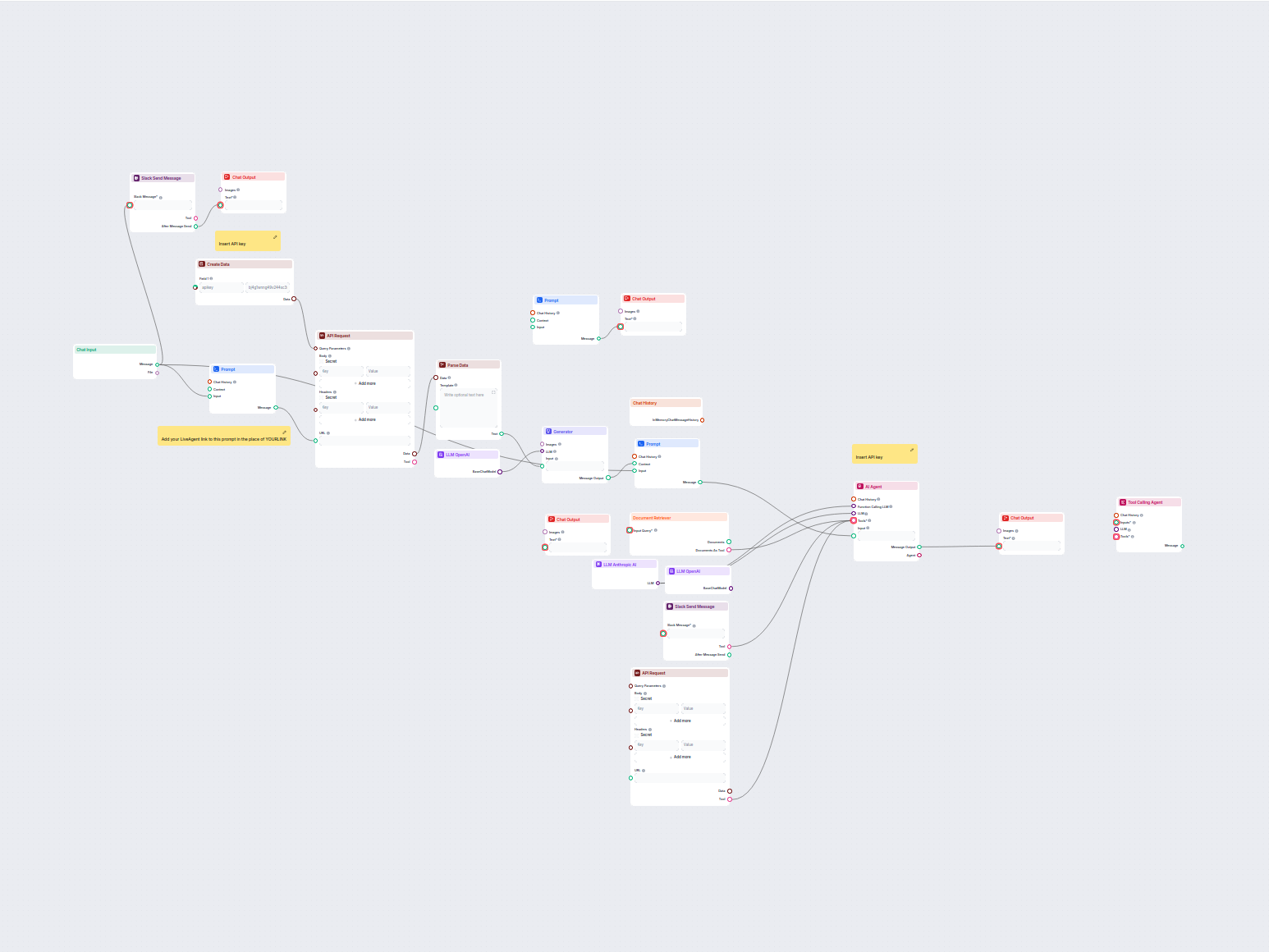
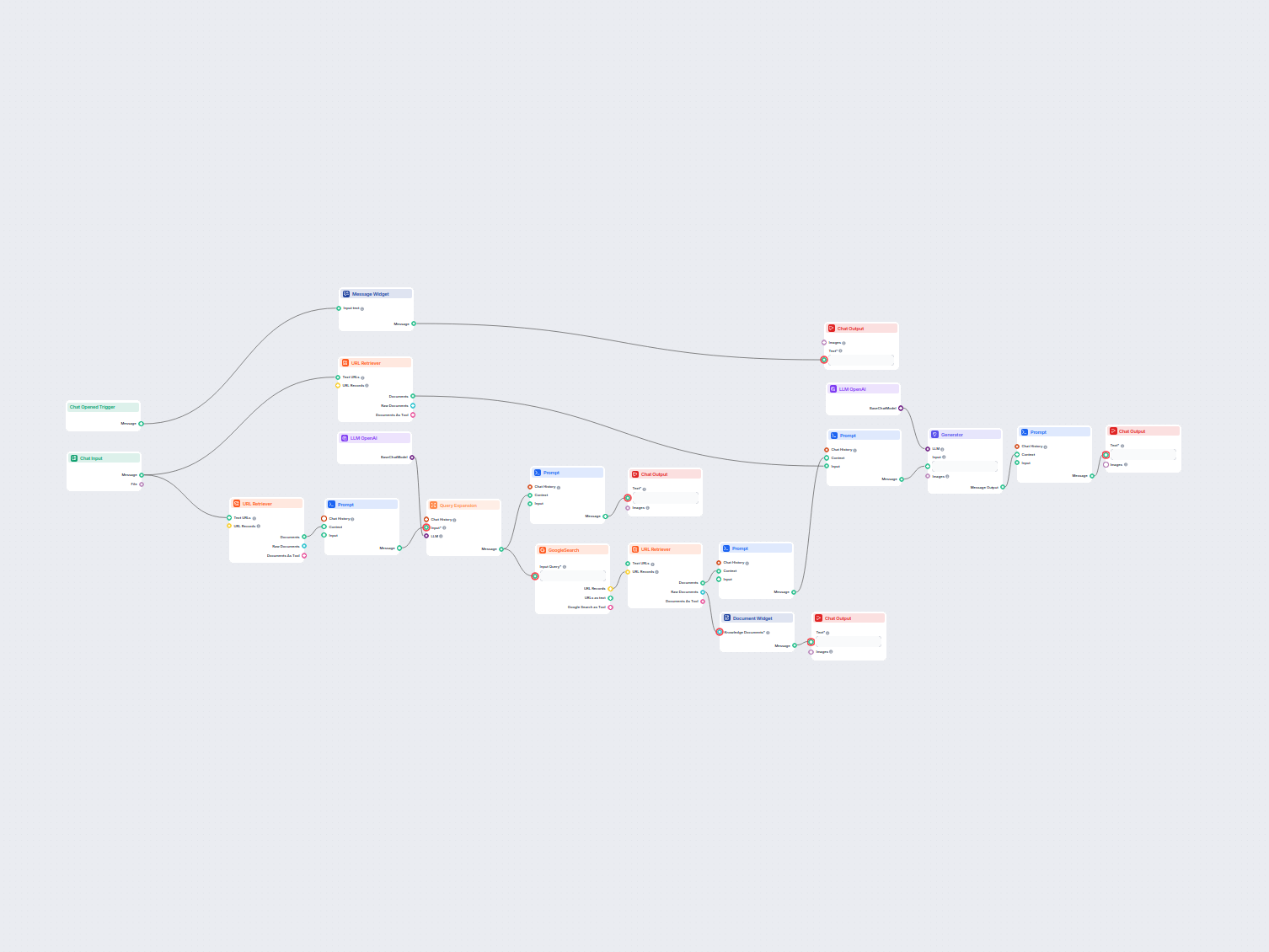
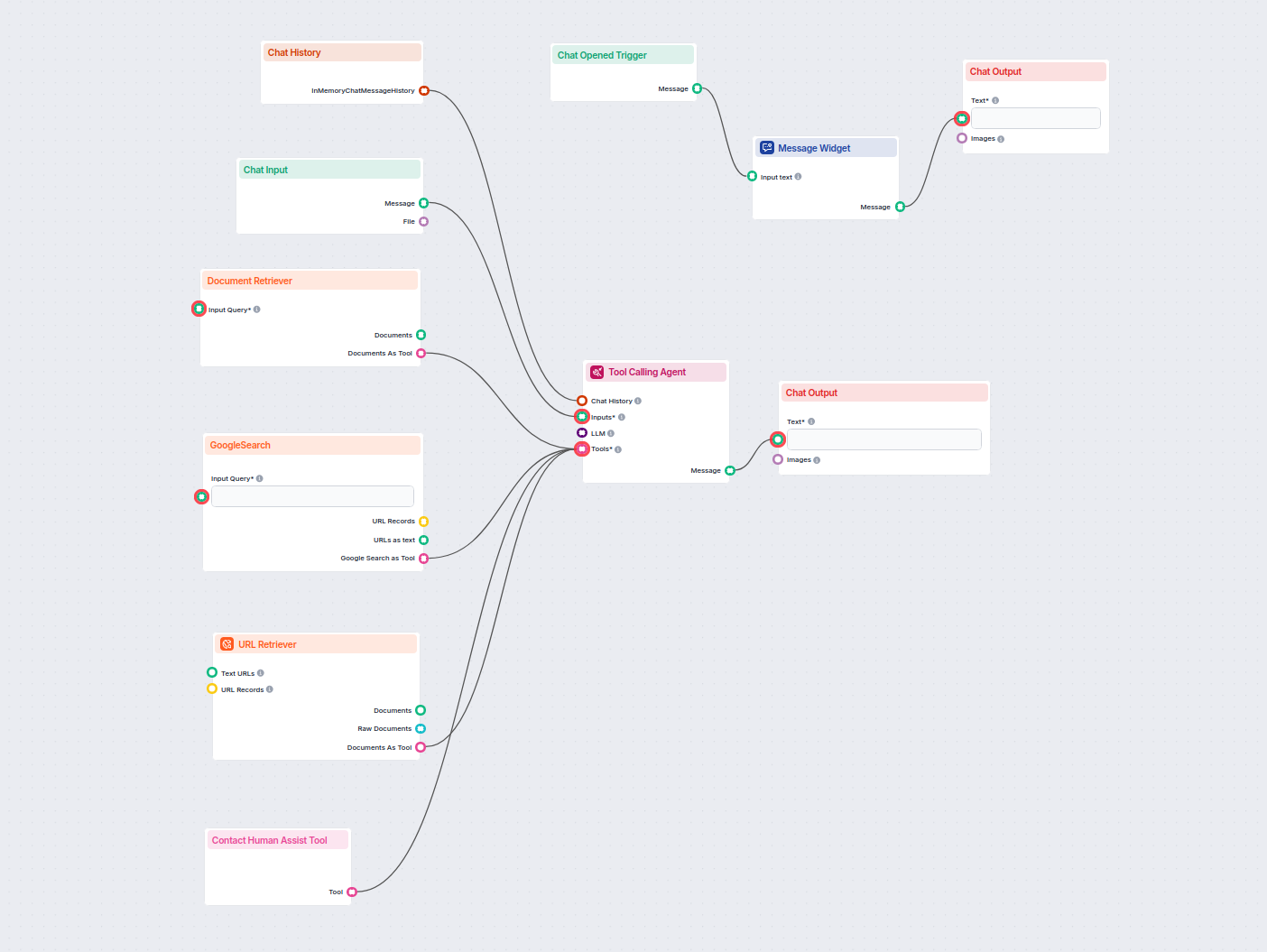
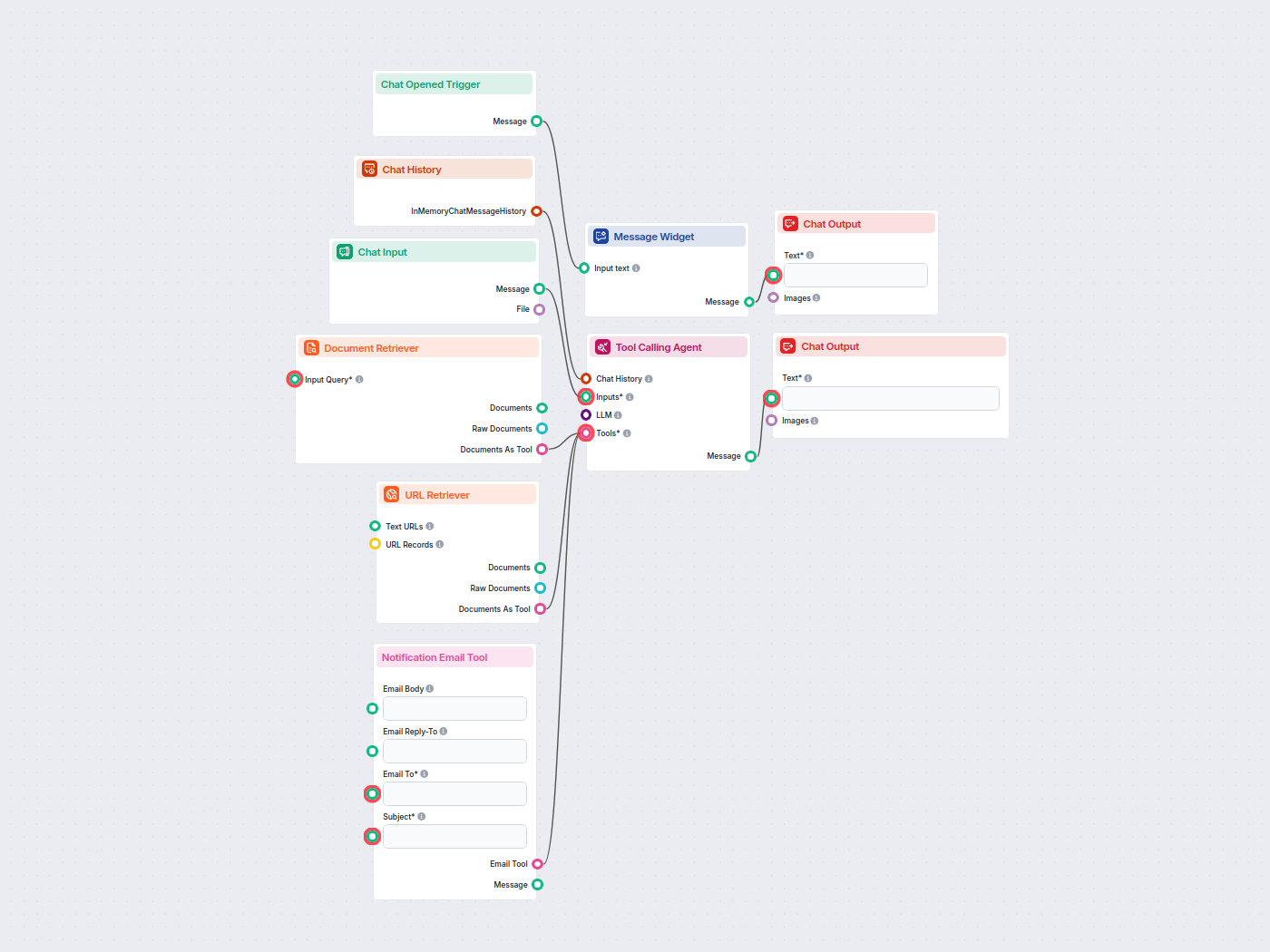
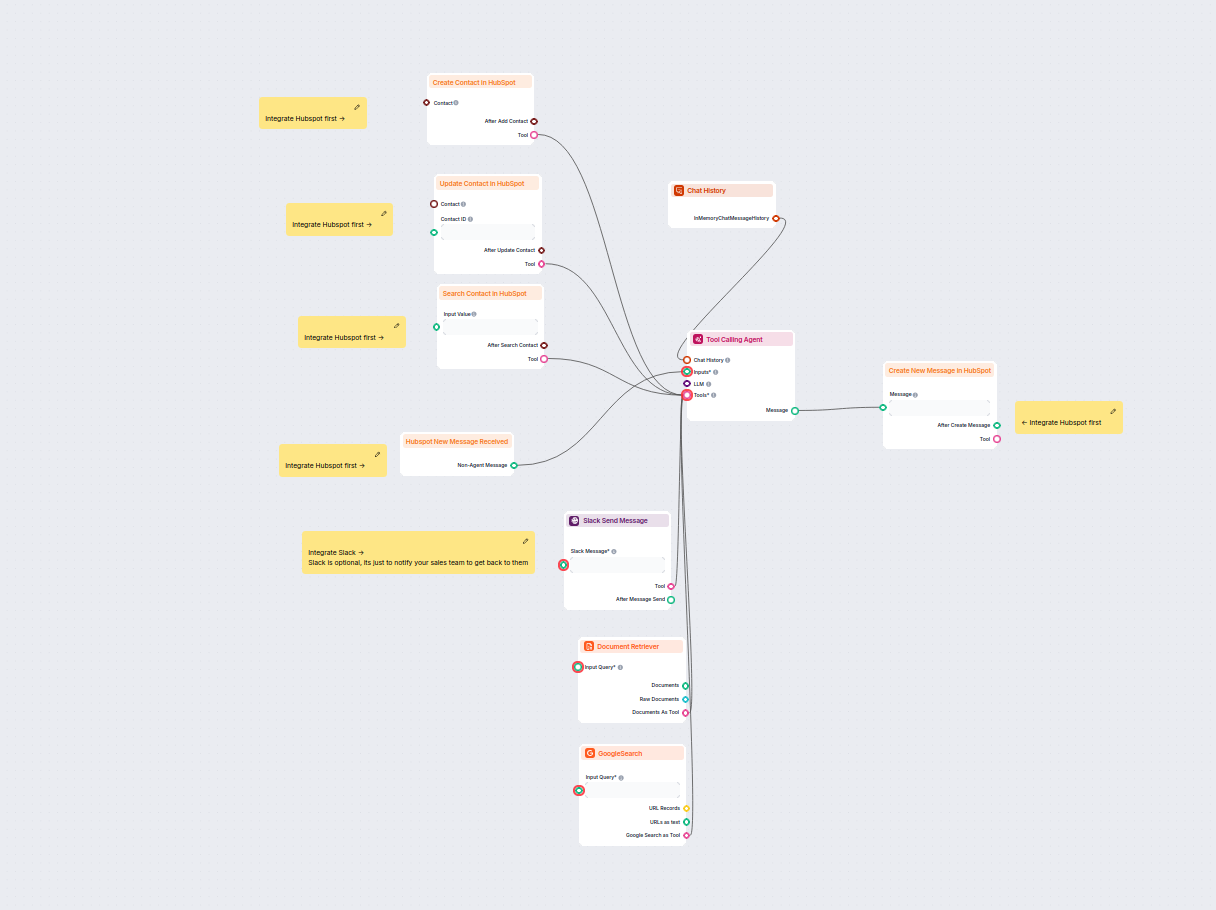
Esempi di modelli di flusso che utilizzano il componente Document Retriever
Per aiutarti a iniziare rapidamente, abbiamo preparato diversi modelli di flusso di esempio che mostrano come utilizzare efficacemente il componente Document Retriever. Questi modelli presentano diversi casi d'uso e best practice, rendendo più facile per te comprendere e implementare il componente nei tuoi progetti.
Agente di Supporto Clienti AI con Base di Conoscenza e Arricchimento tramite API
Questo workflow basato su AI automatizza il supporto clienti combinando la ricerca nella base di conoscenza interna, il recupero di informazioni da Google Docs,...
Agente di Supporto Clienti AI con Integrazione API LiveAgent
Questo workflow basato su AI automatizza il supporto clienti collegando le richieste degli utenti alle fonti di conoscenza aziendali, API esterne (come LiveAgen...
Questo workflow automatizza il supporto clienti per la tua azienda integrando le conversazioni LiveAgent, estraendo i dati rilevanti delle conversazioni, genera...
Un flusso di lavoro per un agente di assistenza clienti basato su AI che può rispondere a domande sui prodotti Shopify, recuperare lo stato degli ordini e acced...
Questo workflow potenziato dall'AI analizza la struttura dei contenuti della tua pagina web, la confronta con le pagine dei principali concorrenti e fornisce ra...
Automatizza la gestione della casella di posta di Gmail con un agente AI che legge le email in arrivo, sfrutta la tua knowledge base per creare risposte profess...
Assistente chatbot AI alimentato da OpenAI GPT-4o che cerca e utilizza automaticamente documenti interni dell'azienda per rispondere alle domande degli utenti. ...
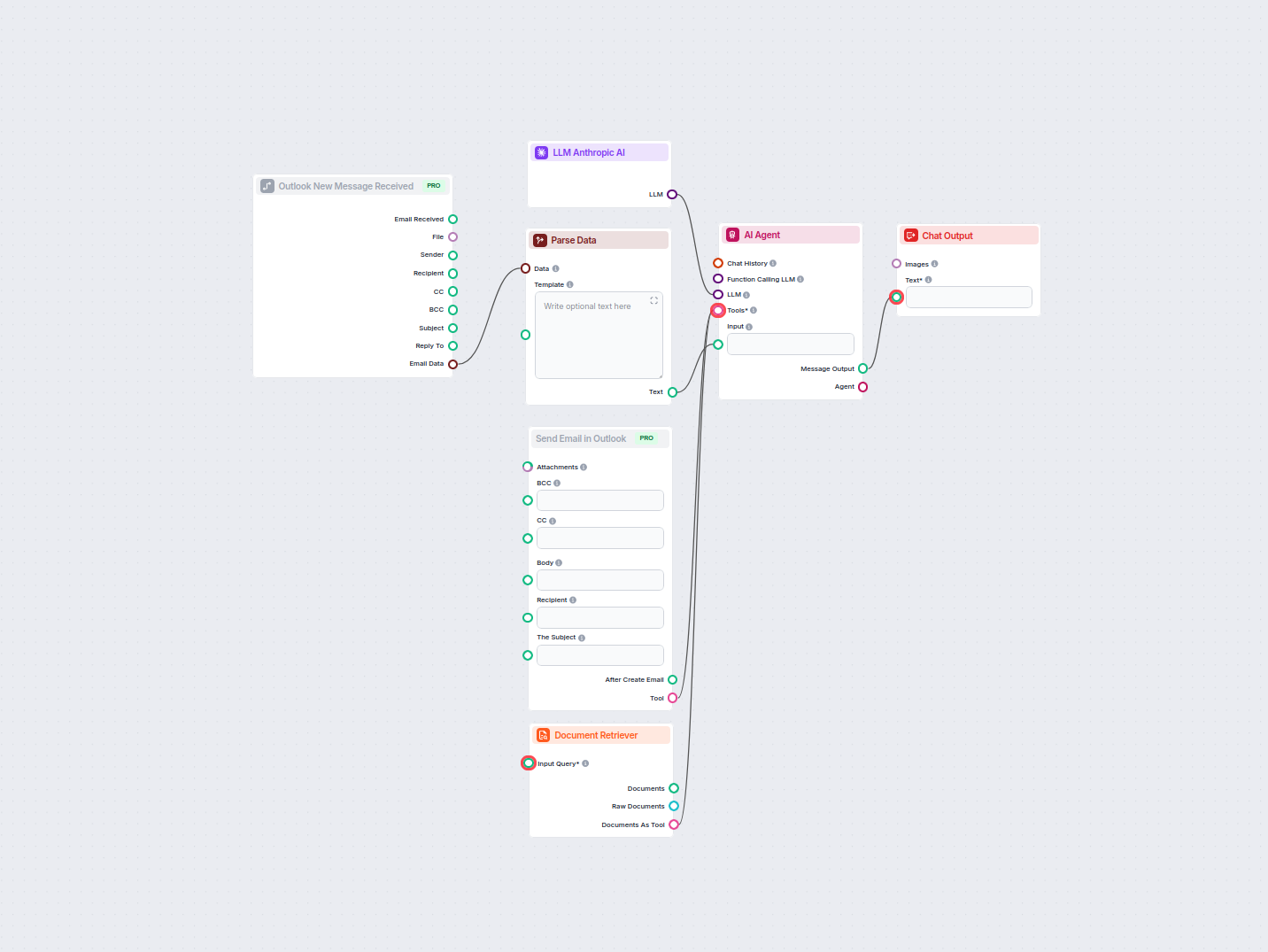
Automazione delle Risposte Email in Outlook Basata su AI
Automatizza le risposte professionali alle email in Outlook utilizzando un agente AI che sfrutta fonti di conoscenza aziendali. Le email in arrivo vengono ricev...
Distribuisci un chatbot intelligente per il supporto clienti su LiveAgent che risponde automaticamente alle domande dei visitatori, recupera documenti dalla kno...
Chatbot AI con FreshChat e Supporto Base di Conoscenza
Implementa un chatbot AI intelligente che si integra perfettamente con FreshChat. Il chatbot risponde alle richieste degli utenti utilizzando la tua base di con...
Implementa un chatbot AI sul tuo sito web che sfrutta la tua knowledge base interna per rispondere alle domande dei clienti e inoltra senza interruzioni le rich...
Un chatbot di supporto live alimentato da AI che risponde alle domande dei clienti utilizzando una knowledge base interna e trasferisce in modo intelligente le ...
Chatbot AI Smartsupp con passaggio a operatore umano
Questo workflow crea un chatbot AI integrato con Smartsupp, che sfrutta una knowledge base interna per rispondere alle richieste di supporto clienti. Se il chat...
Un chatbot di assistenza clienti basato su AI che utilizza le tue fonti di conoscenza interne per fornire risposte istantanee, accurate e utili alle richieste d...
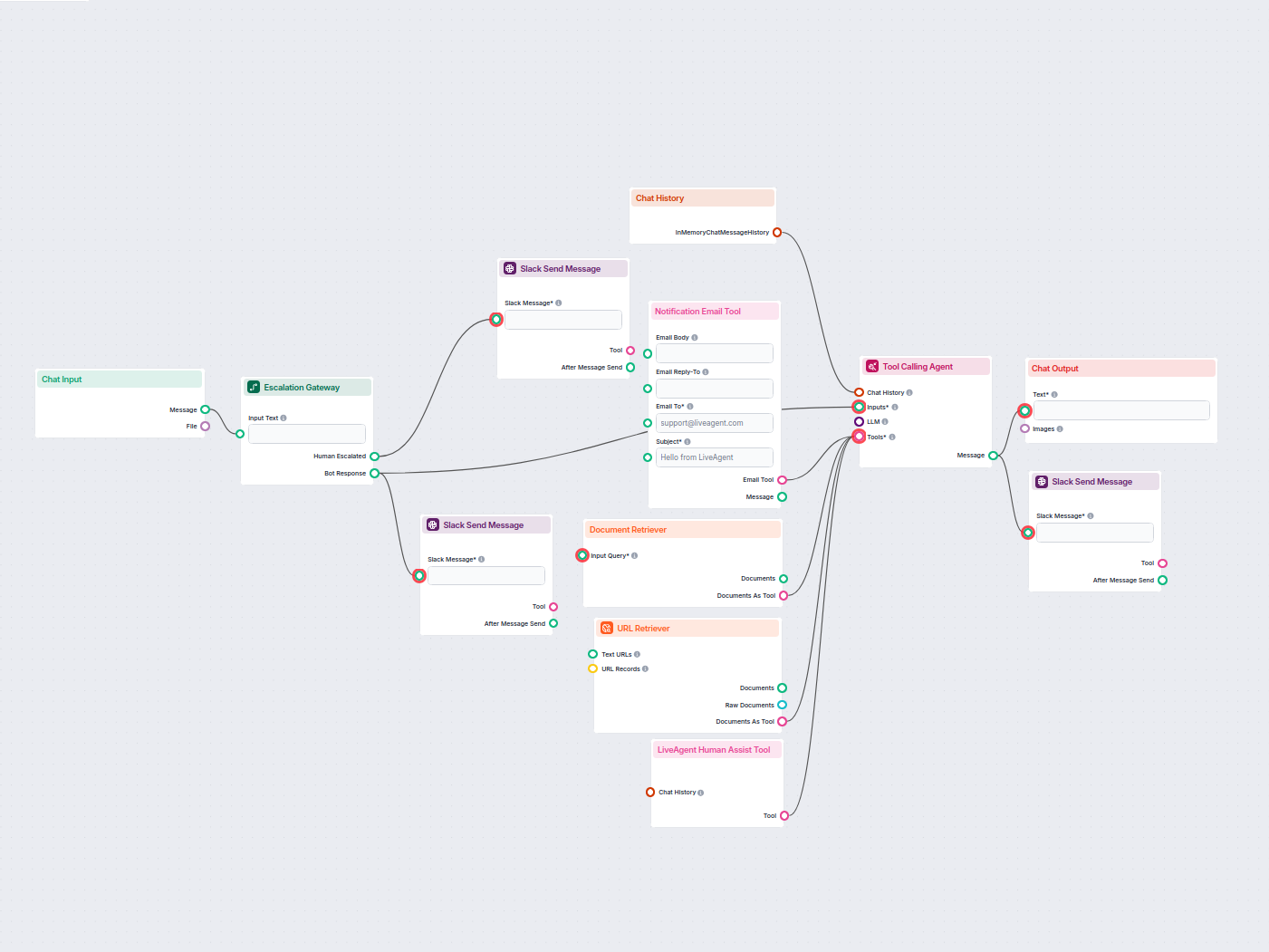
Chatbot di Assistenza Clienti AI con Passaggio all'Umano
Un chatbot di assistenza clienti alimentato dall'IA che assiste automaticamente gli utenti, recupera informazioni da documenti interni e dal web, e trasferisce ...
Questo chatbot per la generazione lead basato su AI offre supporto clienti personalizzato utilizzando la tua base di conoscenza interna, identifica potenziali l...
Questo workflow potenziato dall'AI automatizza la qualificazione dei lead e la gestione dei contatti in HubSpot. Il chatbot raccoglie informazioni dagli utenti,...
Automatizza il tuo supporto clienti con un chatbot AI che risponde alle domande utilizzando la tua knowledge base interna e collega senza interruzioni gli utent...
Converti la documentazione tecnica in un articolo SEO
Trasforma la documentazione tecnica da un URL in un articolo accattivante e ottimizzato SEO per il tuo sito web. Questo flusso analizza i contenuti dei principa...
Genera conclusioni concise da siti web, documenti caricati o video YouTube utilizzando l'IA. Perfetto per riassumere rapidamente i punti chiave e creare finali ...
Genera automaticamente un breve paragrafo coinvolgente per il tuo sito web che include link agli articoli correlati più rilevanti. Questo flusso di lavoro basat...
Cerca e recupera facilmente informazioni da documenti della knowledgebase privata utilizzando la ricerca semantica alimentata dall'IA. Il flow espande le query ...
Automatizza il supporto clienti in LiveAgent con un chatbot AI che risponde alle domande utilizzando la tua knowledge base interna, recupera documenti rilevanti...
Questo workflow semplifica la traduzione dei file markdown HUGO nelle lingue di destinazione mantenendo la struttura e la formattazione del file. Sfruttando mod...
4 min di lettura
Domande frequenti
Cos'è il componente Document Retriever?
Questo componente consente al Flow di recuperare conoscenza dalle tue fonti, come documenti e URL, assicurando che le informazioni restituite siano pertinenti, affidabili e aggiornate.
Perché non posso collegare un Document Retriever all'Output della Chat?
I componenti Retriever creano dati strutturati che non sono adatti all'output. Devono prima essere trasformati in testo o formato visivo prima di essere inviati al componente Chat Output.
Da dove recupera le informazioni il Knowledge Retriever?
Il componente cerca la corrispondenza più vicina alla query tra le informazioni provenienti da URL, documenti e pianificazioni specificati dall'utente.
Quanti documenti restituisce?
Puoi impostare un limite al numero di risultati restituiti, assicurando che solo i contenuti più pertinenti siano inclusi nel tuo flow.
Posso filtrare quali documenti vengono cercati?
Sì, puoi filtrare per categorie di documenti, pianificazioni o URL, focalizzando la ricerca su segmenti specifici della tua base di conoscenza.
Posso collegare sia il Document Retriever che GoogleSearch? In tal caso, quale viene prioritizzato?
Puoi usarli entrambi contemporaneamente. Ogni retriever conduce al proprio output, con priorità stabilita dall'ordine degli output nel canvas. Ha priorità il primo output dall'alto.
Prova il Document Retriever di FlowHunt
Costruisci soluzioni AI più intelligenti collegando le tue fonti di conoscenza e assicurando che il tuo chatbot fornisca sempre risposte pertinenti e aggiornate.
Il componente GoogleSearch di FlowHunt migliora l'accuratezza dei chatbot utilizzando la Retrieval-Augmented Generation (RAG) per accedere a conoscenze aggiorna...
Le Fonti di Conoscenza rendono l'insegnamento dell'AI secondo le tue esigenze un gioco da ragazzi. Scopri tutti i modi per collegare la conoscenza con FlowHunt....
La Risposta alle Domande con la Retrieval-Augmented Generation (RAG) combina il recupero delle informazioni e la generazione di linguaggio naturale per potenzia...
6 min di lettura
AI
Question Answering
+4
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.