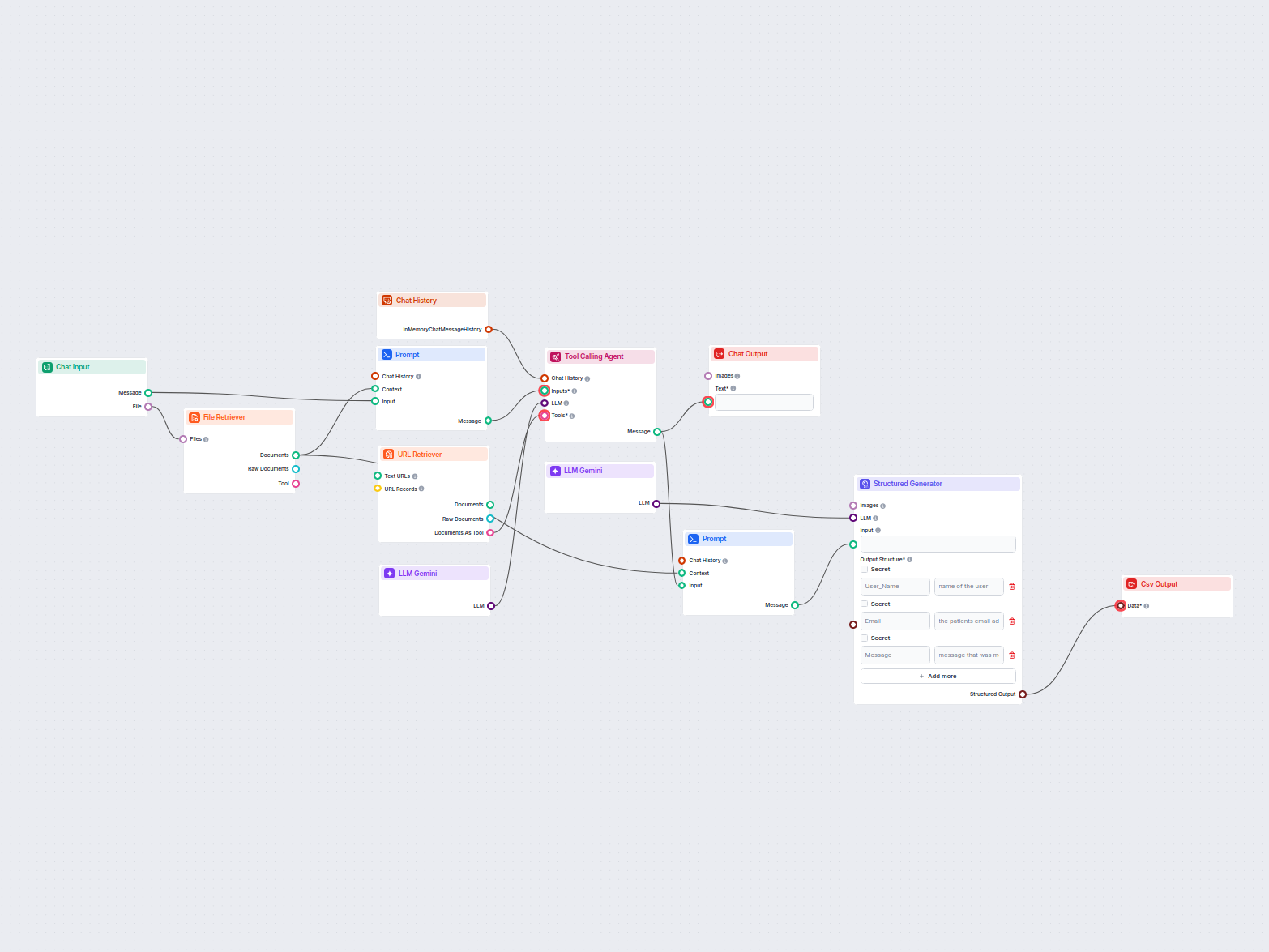
Estrazione di dati da email e file in CSV
Questo workflow estrae e organizza le informazioni chiave da email e file allegati, utilizza l'AI per elaborare e strutturare i dati, e restituisce i risultati ...
4 min di lettura
Per aiutarti a iniziare rapidamente, abbiamo preparato diversi modelli di flusso di esempio che mostrano come utilizzare efficacemente il componente Urlcontent. Questi modelli presentano diversi casi d'uso e best practice, rendendo più facile per te comprendere e implementare il componente nei tuoi progetti.
Questo workflow estrae e organizza le informazioni chiave da email e file allegati, utilizza l'AI per elaborare e strutturare i dati, e restituisce i risultati ...
Aiutiamo aziende come la tua a sviluppare chatbot intelligenti, server MCP, strumenti AI o altri tipi di automazione AI per sostituire l'uomo in compiti ripetitivi nella tua organizzazione.