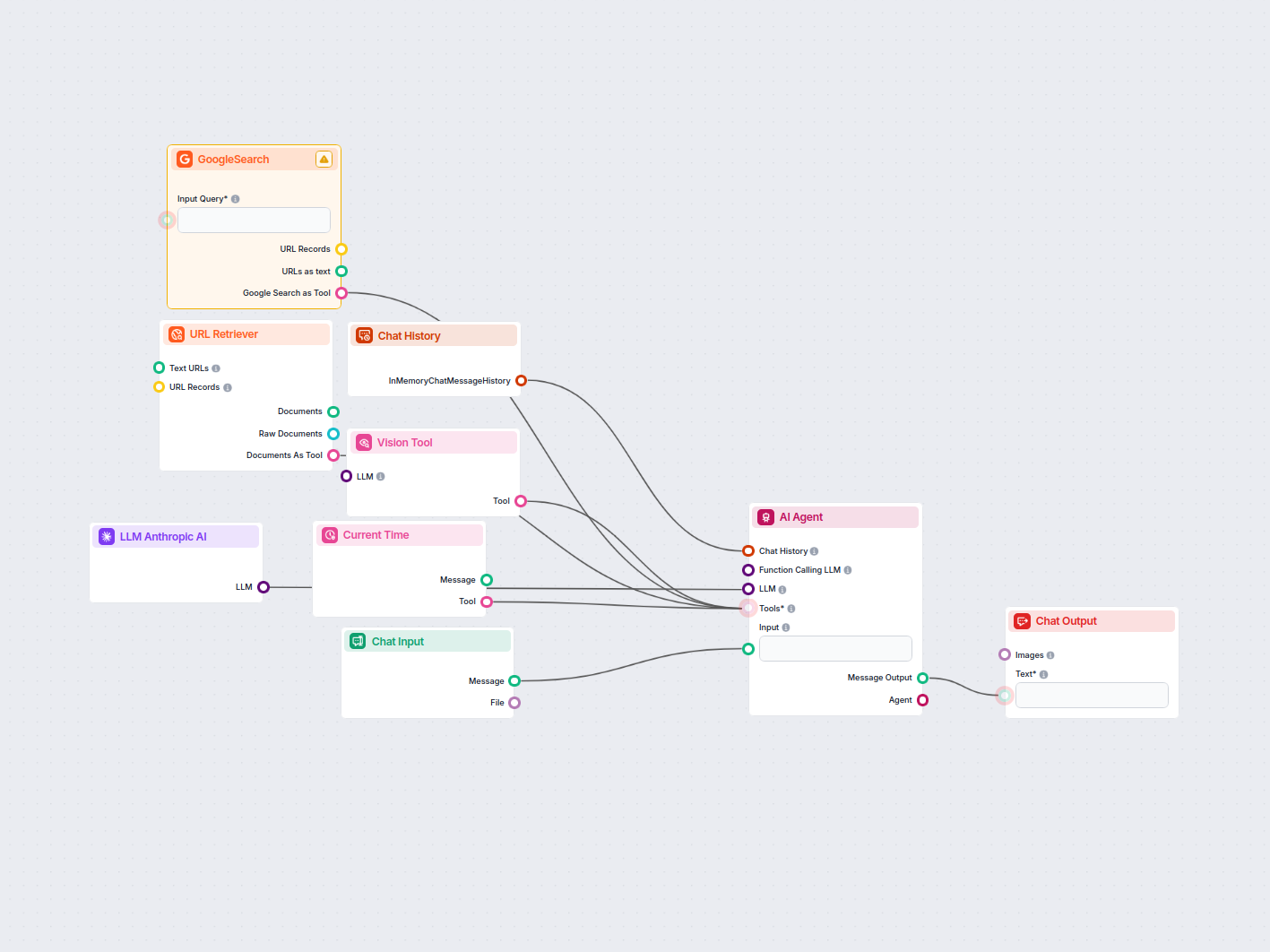
Analizzatore della Concorrenza per Annunci LinkedIn
Questo workflow automatizza la ricerca di mercato sugli annunci LinkedIn identificando i principali concorrenti per una parola chiave, analizzando i loro testi ...
5 min di lettura
Il componente Strumento Visione permette all’IA di analizzare immagini, estrarre informazioni preziose e rispondere a domande basate sui contenuti visivi all’interno dei tuoi flussi di lavoro.
Descrizione del componente
The Vision Tool is a component designed to enable AI workflows to process and analyze images provided as attachments. It empowers AI agents to “see” images, extract meaningful information, and answer questions about the visual content. This makes it especially valuable for scenarios where understanding or interpreting images is essential, such as document processing, visual QA, content moderation, or multimedia analysis.
| Input Name | Type | Description | Required | Advanced |
|---|---|---|---|---|
| LLM (model) | BaseChatModel | The language model used for generating text responses based on image analysis. | No | No |
| Tool Description | String (multi) | Description that helps the agent understand how to use this tool. | No | Yes |
| Tool Name | String | The reference name for this tool within agent workflows. | No | Yes |
| Verbose | Boolean | Option to enable detailed (verbose) output for debugging or transparency. | No | Yes |
| Output Name | Type | Description |
|---|---|---|
| Tool | Tool | The configured Vision Tool instance ready for integration |
The Vision Tool outputs a Tool instance that can be used by AI agents to process images and produce relevant responses.
Incorporating the Vision Tool into your AI processes unlocks the ability to work with visual data, not just text. It bridges the gap between language and image understanding, creating opportunities for richer, more interactive, and intelligent applications.
Summary of Benefits:
By using the Vision Tool, your AI workflows can become more capable and versatile, paving the way for next-generation applications that leverage both text and vision intelligence.
Per aiutarti a iniziare rapidamente, abbiamo preparato diversi modelli di flusso di esempio che mostrano come utilizzare efficacemente il componente Strumento Visione. Questi modelli presentano diversi casi d'uso e best practice, rendendo più facile per te comprendere e implementare il componente nei tuoi progetti.
Questo workflow automatizza la ricerca di mercato sugli annunci LinkedIn identificando i principali concorrenti per una parola chiave, analizzando i loro testi ...
Lo Strumento Visione consente al tuo flusso di elaborare immagini, estrarre informazioni significative e rispondere a domande sui contenuti delle immagini utilizzando l'IA.
Sì, lo Strumento Visione è progettato per interpretare le immagini nel contesto del tuo flusso di lavoro, permettendo agli agenti IA di combinare informazioni visive e testuali per un'automazione più intelligente.
I casi d'uso tipici includono l'elaborazione di documenti, l'ispezione visiva automatizzata, l'estrazione di dati da immagini e il potenziamento delle conversazioni dei chatbot attraverso la comprensione delle immagini.
Assolutamente sì. Lo Strumento Visione è un componente plug-and-play in FlowHunt che può essere facilmente collegato ad altri elementi del flusso di lavoro che richiedono l'analisi delle immagini.
Puoi selezionare o configurare un modello IA, ma FlowHunt offre impostazioni predefinite sensate per una configurazione rapida e sperimentazione.
Potenzia i tuoi flussi di lavoro con la comprensione delle immagini tramite IA: prova oggi lo Strumento Visione su FlowHunt.
Esplora il componente Generatore di Immagini AI Photomatic: trasforma prompt testuali in immagini AI di alta qualità con modelli avanzati, effetti personalizzab...
Genera immagini sorprendenti da prompt testuali con il componente Generatore di Immagini Flux in FlowHunt. Personalizza l’output scegliendo il modello, il forma...
Il componente File Retriever in FlowHunt ti consente di inserire file nei tuoi flussi di lavoro e convertirli in documenti per ulteriori elaborazioni. Supporta ...