
MLflow
MLflow è una piattaforma open-source progettata per semplificare e gestire il ciclo di vita del machine learning (ML). Fornisce strumenti per il tracciamento de...
6 min di lettura
MLflow
Machine Learning
+3
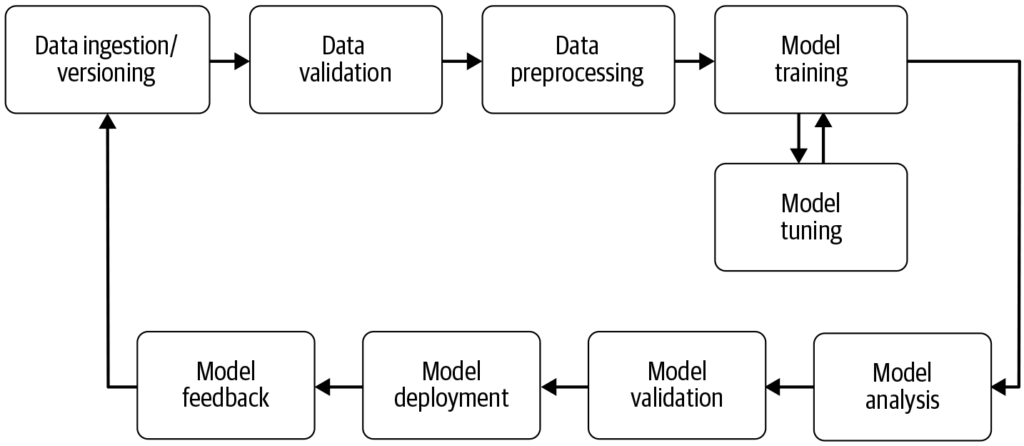
Una pipeline di machine learning automatizza i passaggi dalla raccolta dei dati alla distribuzione del modello, migliorando efficienza, riproducibilità e scalabilità nei progetti di machine learning.
Una pipeline di machine learning è un flusso di lavoro automatizzato che semplifica lo sviluppo, l’addestramento, la valutazione e la distribuzione dei modelli. Migliora efficienza, riproducibilità e scalabilità, facilitando le attività dalla raccolta dei dati fino alla distribuzione e manutenzione del modello.
Una pipeline di machine learning è un flusso di lavoro automatizzato che comprende una serie di passaggi coinvolti nello sviluppo, addestramento, valutazione e distribuzione di modelli di machine learning. È progettata per semplificare e standardizzare i processi necessari a trasformare dati grezzi in insight azionabili tramite algoritmi di machine learning. L’approccio a pipeline consente una gestione efficiente dei dati, dell’addestramento e della distribuzione dei modelli, rendendo più semplice gestire e scalare le operazioni di machine learning.
Fonte: Building Machine Learning
Raccolta Dati: La fase iniziale in cui i dati vengono raccolti da varie fonti come database, API o file. La raccolta dati è una pratica metodica volta ad acquisire informazioni significative per costruire un dataset coerente e completo per uno specifico scopo aziendale. Questi dati grezzi sono essenziali per costruire modelli di machine learning, ma spesso richiedono preprocessing per essere utili. Come evidenziato da AltexSoft, la raccolta dati comporta l’accumulo sistematico di informazioni a supporto dell’analisi e del processo decisionale. Questo processo è fondamentale poiché pone le basi per tutti i passaggi successivi nella pipeline ed è spesso continuo per garantire che i modelli siano addestrati su dati rilevanti e aggiornati.
Preprocessing dei Dati: I dati grezzi vengono puliti e trasformati in un formato adatto per l’addestramento del modello. Le operazioni comuni di preprocessing includono la gestione dei valori mancanti, la codifica delle variabili categoriche, la scalatura delle feature numeriche e la suddivisione dei dati in set di addestramento e test. Questa fase assicura che i dati siano nel formato corretto e privi di incongruenze che potrebbero influire sulle prestazioni del modello.
Feature Engineering: Creazione di nuove feature o selezione di quelle rilevanti dai dati per migliorare la capacità predittiva del modello. Questo passaggio può richiedere conoscenze specifiche del dominio e creatività. Il feature engineering è un processo creativo che trasforma i dati grezzi in feature significative in grado di rappresentare meglio il problema sottostante e aumentare le prestazioni dei modelli di machine learning.
Selezione del Modello: Vengono scelti gli algoritmi di machine learning appropriati in base al tipo di problema (ad esempio, classificazione, regressione), alle caratteristiche dei dati e ai requisiti di performance. In questa fase si può considerare anche l’ottimizzazione degli iperparametri. La scelta del modello giusto è fondamentale perché influenza la precisione e l’efficienza delle previsioni.
Addestramento del Modello: I modelli selezionati vengono addestrati utilizzando il dataset di training. Questo comporta l’apprendimento dei pattern e delle relazioni presenti nei dati. Si possono anche utilizzare modelli pre-addestrati invece di addestrarne uno da zero. L’addestramento è una fase vitale in cui il modello apprende dai dati per effettuare previsioni informate.
Valutazione del Modello: Dopo l’addestramento, le prestazioni del modello vengono valutate utilizzando un dataset di test separato o tramite cross-validation. Le metriche di valutazione dipendono dal problema specifico ma possono includere accuratezza, precisione, recall, F1-score, errore quadratico medio, tra le altre. Questa fase è cruciale per assicurarsi che il modello funzioni bene su dati mai visti prima.
Distribuzione del Modello: Una volta sviluppato e valutato un modello soddisfacente, può essere distribuito in un ambiente di produzione per effettuare previsioni su nuovi dati. La distribuzione può comportare la creazione di API e l’integrazione con altri sistemi. La distribuzione è la fase finale della pipeline in cui il modello diventa accessibile per l’utilizzo nel mondo reale.
Monitoraggio e Manutenzione: Dopo la distribuzione, è essenziale monitorare continuamente le prestazioni del modello e riaddestrarlo quando necessario per adattarsi ai cambiamenti nei dati, garantendo che rimanga preciso e affidabile in contesti reali. Questo processo continuo assicura che il modello resti rilevante e accurato nel tempo.
Natural Language Processing bridges human-computer interaction. Discover its key aspects, workings, and applications today!") (NLP): Le attività NLP spesso comportano più passaggi ripetibili come ingestione dati, pulizia del testo, tokenizzazione e analisi del sentiment. Le pipeline aiutano a modularizzare questi passaggi, permettendo modifiche e aggiornamenti semplici senza influire sugli altri componenti.
Manutenzione Predittiva: In settori come la manifattura, le pipeline possono essere utilizzate per prevedere i guasti delle apparecchiature analizzando i dati dei sensori, consentendo così una manutenzione proattiva e riducendo i tempi di inattività.
Finanza: Le pipeline possono automatizzare l’elaborazione dei dati finanziari per rilevare frodi, valutare rischi di credito o prevedere prezzi azionari, migliorando i processi decisionali.
Sanità: Nel settore sanitario, le pipeline possono elaborare immagini mediche o cartelle cliniche per supportare la diagnostica o prevedere gli esiti dei pazienti, migliorando le strategie di trattamento.
Le pipeline di machine learning sono parte integrante di AI e automazione](https://www.flowhunt.io#:~:text=automation “Build AI tools and chatbots with FlowHunt’s no-code platform. Explore templates, components, and seamless automation. Book a demo today!”) fornendo una struttura organizzata per automatizzare i compiti di machine learning. Nell’ambito di AI automation, le pipeline garantiscono che i modelli vengano addestrati e distribuiti in modo efficiente, permettendo a sistemi di AI come [chatbot di apprendere e adattarsi a nuovi dati senza intervento manuale. Questa automazione è cruciale per scalare le applicazioni di AI e garantire prestazioni costanti e affidabili in diversi domini. Sfruttando le pipeline, le organizzazioni possono potenziare le proprie capacità di AI e assicurarsi che i modelli di machine learning restino rilevanti ed efficaci in ambienti in continua evoluzione.
Ricerca sulle Pipeline di Machine Learning
“Deep Pipeline Embeddings for AutoML” di Sebastian Pineda Arango e Josif Grabocka (2023) si concentra sulle sfide nell’ottimizzazione delle pipeline di machine learning in Automated Machine Learning (AutoML). Questo articolo introduce una nuova architettura neurale progettata per catturare profonde interazioni tra i componenti della pipeline. Gli autori propongono l’embedding delle pipeline in rappresentazioni latenti tramite un meccanismo di encoder per componente. Questi embedding sono utilizzati in un framework di Bayesian Optimization per cercare pipeline ottimali. L’articolo enfatizza l’uso del meta-learning per perfezionare i parametri della rete di embedding della pipeline, dimostrando risultati all’avanguardia nell’ottimizzazione delle pipeline su più dataset. Leggi di più.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” di Tien-Dung Nguyen et al. (2020) affronta la valutazione dispendiosa in termini di tempo delle pipeline di machine learning durante i processi AutoML. Lo studio critica i metodi tradizionali come le ottimizzazioni bayesiane e genetiche per la loro inefficienza. Per ovviare a ciò, gli autori presentano AVATAR, un modello surrogato che valuta in modo efficiente la validità delle pipeline senza eseguirle. Questo approccio accelera notevolmente la composizione e l’ottimizzazione di pipeline complesse filtrando quelle invalide nelle prime fasi del processo. Leggi di più.
“Data Pricing in Machine Learning Pipelines” di Zicun Cong et al. (2021) esplora il ruolo cruciale dei dati nelle pipeline di machine learning e la necessità di una valorizzazione dei dati per facilitare la collaborazione tra più stakeholder. L’articolo esamina gli ultimi sviluppi nel pricing dei dati nel contesto del machine learning, concentrandosi sulla sua importanza nelle varie fasi della pipeline. Fornisce spunti sulle strategie di pricing per la raccolta dei dati di training, l’addestramento collaborativo dei modelli e la fornitura di servizi di machine learning, evidenziando la formazione di un ecosistema dinamico. Leggi di più.
Una pipeline di machine learning è una sequenza automatizzata di passaggi—dalla raccolta e preprocessing dei dati fino all’addestramento, valutazione e distribuzione del modello—che semplifica e standardizza il processo di costruzione e manutenzione dei modelli di machine learning.
I componenti chiave includono raccolta dati, preprocessing dei dati, feature engineering, selezione del modello, addestramento del modello, valutazione del modello, distribuzione del modello e monitoraggio e manutenzione continui.
Le pipeline di machine learning offrono modularizzazione, efficienza, riproducibilità, scalabilità, collaborazione migliorata e una distribuzione dei modelli più semplice negli ambienti produttivi.
I casi d’uso includono elaborazione del linguaggio naturale (NLP), manutenzione predittiva nell’industria manifatturiera, valutazione del rischio finanziario e rilevamento delle frodi, e diagnostica sanitaria.
Le sfide includono garantire la qualità dei dati, gestire la complessità della pipeline, integrarla con i sistemi esistenti e controllare i costi legati alle risorse computazionali e all'infrastruttura.
Prenota una demo per scoprire come FlowHunt può aiutarti ad automatizzare e scalare i tuoi flussi di lavoro di machine learning con facilità.
MLflow è una piattaforma open-source progettata per semplificare e gestire il ciclo di vita del machine learning (ML). Fornisce strumenti per il tracciamento de...
BigML è una piattaforma di machine learning progettata per semplificare la creazione e la distribuzione di modelli predittivi. Fondata nel 2011, la sua missione...
Kubeflow è una piattaforma open-source per il machine learning (ML) su Kubernetes, che semplifica il deployment, la gestione e la scalabilità dei flussi di lavo...
