Cos’è una Pipeline di Recupero per Chatbot?
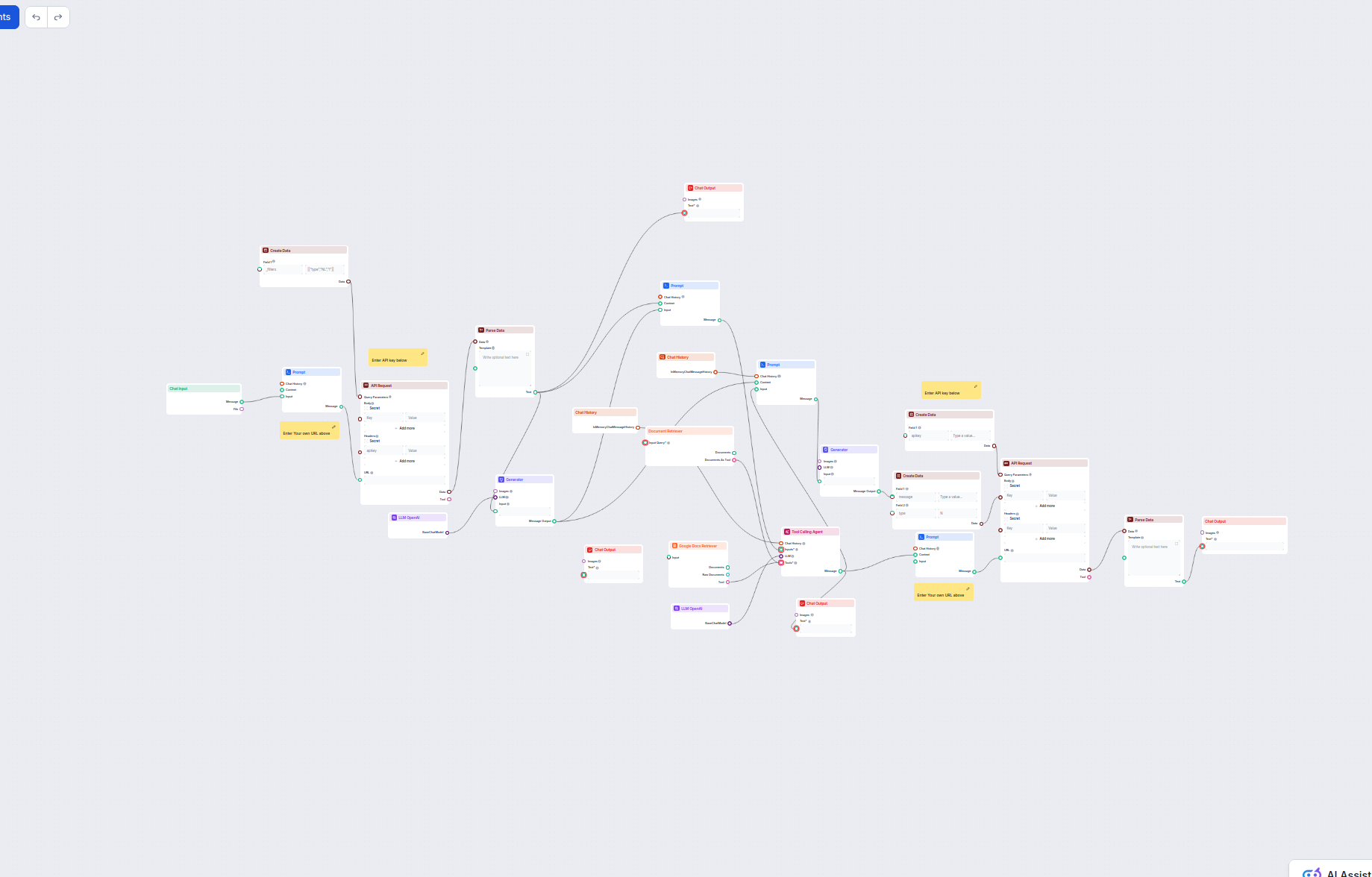
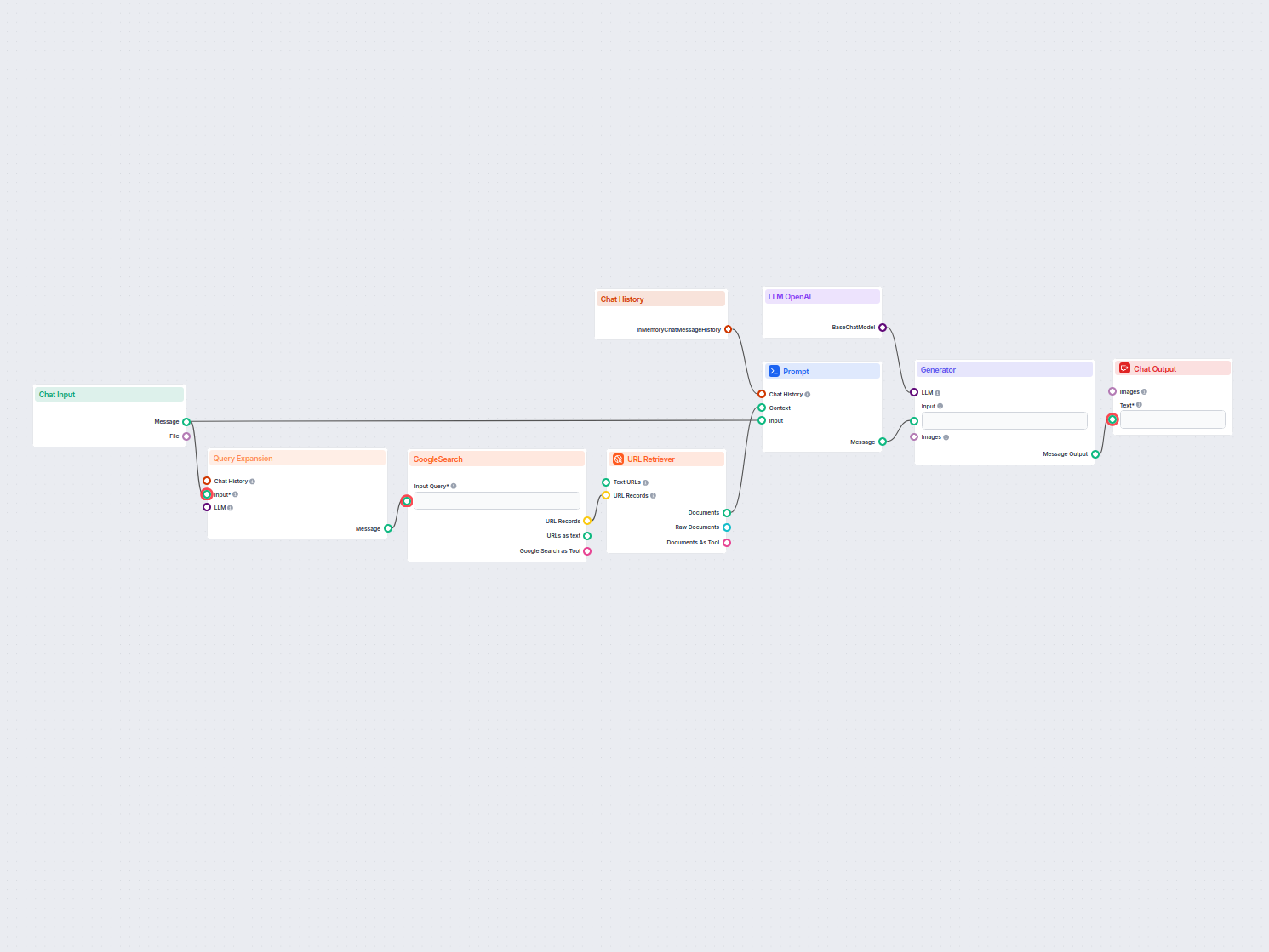
Una pipeline di recupero per chatbot si riferisce all’architettura tecnica e ai processi che permettono ai chatbot di recuperare, processare e ottenere informazioni rilevanti in risposta alle richieste degli utenti. A differenza dei semplici sistemi di domanda e risposta che si basano solo su modelli linguistici pre-addestrati, le pipeline di recupero integrano basi di conoscenza esterne o fonti dati aggiuntive. Questo consente al chatbot di fornire risposte accurate, contestualmente pertinenti e aggiornate anche quando i dati non sono presenti nel modello linguistico stesso.
La pipeline di recupero è tipicamente composta da diversi componenti, tra cui ingestione dati, creazione di embedding, archiviazione vettoriale, recupero del contesto e generazione della risposta. La sua implementazione sfrutta spesso la Retrieval-Augmented Generation (RAG), che combina i punti di forza dei sistemi di recupero dati e dei grandi modelli linguistici (LLM) per la generazione delle risposte.
Come viene utilizzata una Pipeline di Recupero nei Chatbot?
Una pipeline di recupero viene utilizzata per potenziare le capacità di un chatbot permettendogli di:
- Accedere a Conoscenze Specifiche di Dominio
Può interrogare database esterni, documenti o API per recuperare informazioni precise rilevanti per la richiesta dell’utente. - Generare Risposte Contestuali
Arricchendo i dati recuperati con la generazione di linguaggio naturale, il chatbot produce risposte coerenti e personalizzate. - Garantire Informazioni Aggiornate
A differenza dei modelli linguistici statici, la pipeline consente il recupero in tempo reale di informazioni da fonti dinamiche.
Componenti Chiave di una Pipeline di Recupero
Ingestione dei Documenti
Raccolta e pre-elaborazione dei dati grezzi, che possono includere PDF, file di testo, database o API. Strumenti come LangChain o LlamaIndex vengono spesso utilizzati per una ingestione dati fluida.
Esempio: Caricamento di FAQ del servizio clienti o specifiche di prodotto nel sistema.
Pre-Processing dei Documenti
I documenti lunghi vengono suddivisi in parti più piccole e semanticamente significative. Questo è essenziale per adattare il testo ai modelli di embedding che di solito hanno limiti di token (ad esempio, 512 token).
Esempio di Codice:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Generazione di Embedding
I dati testuali vengono convertiti in rappresentazioni vettoriali ad alta dimensionalità tramite modelli di embedding. Questi embedding codificano numericamente il significato semantico dei dati.
Esempio di modello di embedding: OpenAI “text-embedding-ada-002” o Hugging Face “e5-large-v2”.
Archiviazione Vettoriale
Gli embedding vengono archiviati in database vettoriali ottimizzati per ricerche di similarità. Strumenti come Milvus, Chroma o PGVector sono comunemente utilizzati.
Esempio: Archiviazione delle descrizioni dei prodotti e dei relativi embedding per un recupero efficiente.
Elaborazione delle Query
Quando viene ricevuta una richiesta dell’utente, questa viene trasformata in un vettore di query utilizzando lo stesso modello di embedding. Ciò consente il matching semantico con gli embedding archiviati.
Esempio di Codice:
query_vector = embedding_model.encode("Quali sono le specifiche del Prodotto X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Recupero Dati
Il sistema recupera le parti di dati più rilevanti in base ai punteggi di similarità (ad esempio, similarità coseno). Sistemi di recupero multimodali possono combinare database SQL, knowledge graph e ricerche vettoriali per risultati più robusti.
Generazione delle Risposte
I dati recuperati vengono combinati con la richiesta utente e passati a un grande modello linguistico (LLM) per generare una risposta finale in linguaggio naturale. Questo passaggio viene spesso chiamato generazione aumentata.
Esempio di Template Prompt:
prompt_template = """
Context: {context}
Question: {question}
Si prega di fornire una risposta dettagliata utilizzando il contesto sopra.
"""
Post-Processing e Validazione
Pipeline di recupero avanzate includono rilevamento delle allucinazioni, controlli di rilevanza o valutazione della risposta per assicurare che l’output sia fattuale e pertinente.
Casi d’Uso delle Pipeline di Recupero nei Chatbot
Supporto Clienti
I chatbot possono recuperare manuali di prodotto, guide di troubleshooting o FAQ per fornire risposte immediate alle domande dei clienti.
Esempio: Un chatbot che aiuta un cliente a resettare un router recuperando la sezione rilevante del manuale utente.
Gestione della Conoscenza Aziendale
Chatbot interni possono accedere a dati aziendali specifici come policy HR, documentazione IT o linee guida di conformità.
Esempio: Dipendenti che interrogano un chatbot interno sulle policy di malattia.
E-Commerce
I chatbot assistono gli utenti recuperando dettagli sui prodotti, recensioni o disponibilità in magazzino.
Esempio: “Quali sono le principali caratteristiche del Prodotto Y?”
Sanità
I chatbot recuperano letteratura medica, linee guida o dati dei pazienti per assistere professionisti sanitari o pazienti.
Esempio: Un chatbot che recupera avvertenze sulle interazioni farmacologiche da un database farmaceutico.
Istruzione e Ricerca
Chatbot accademici utilizzano pipeline RAG per recuperare articoli scientifici, rispondere a domande o riassumere risultati di ricerca.
Esempio: “Puoi riassumere i risultati di questo studio sul cambiamento climatico del 2023?”
Legale e Compliance
I chatbot recuperano documenti legali, giurisprudenza o requisiti di conformità per assistere professionisti legali.
Esempio: “Qual è l’ultimo aggiornamento sulle normative GDPR?”
Esempi di Implementazione di Pipeline di Recupero
Esempio 1: Q&A su PDF
Un chatbot costruito per rispondere a domande dal bilancio annuale aziendale in formato PDF.
Esempio 2: Recupero Ibrido
Un chatbot che combina SQL, ricerca vettoriale e knowledge graph per rispondere alle domande di un dipendente.
Vantaggi dell’Uso di una Pipeline di Recupero
- Accuratezza
Riduce le allucinazioni fondando le risposte su dati recuperati e fattuali. - Rilevanza Contestuale
Personalizza le risposte in base a dati specifici di dominio. - Aggiornamenti in Tempo Reale
Mantiene la base di conoscenza del chatbot aggiornata con fonti dati dinamiche. - Efficienza dei Costi
Riduce la necessità di costosi fine-tuning dei LLM arricchendo con dati esterni. - Trasparenza
Fornisce fonti tracciabili e verificabili per le risposte del chatbot.
Sfide e Considerazioni
- Latenza
Il recupero in tempo reale può introdurre ritardi, specialmente con pipeline multi-step. - Costo
Maggiori chiamate API a LLM o database vettoriali possono comportare costi operativi elevati. - Privacy dei Dati
I dati sensibili devono essere gestiti in modo sicuro, soprattutto nei sistemi RAG self-hosted. - Scalabilità
Pipeline su larga scala richiedono design efficienti per evitare colli di bottiglia nel recupero o stoccaggio dei dati.
Trend Futuri
- Pipeline RAG Agentiche
Agenti autonomi che effettuano ragionamenti e recuperi multi-step. - Modelli di Embedding Ottimizzati
Embedding specifici di dominio per ricerche semantiche migliorate. - Integrazione con Dati Multimodali
Estensione del recupero a immagini, audio e video oltre al testo.
Sfruttando le pipeline di recupero, i chatbot non sono più limitati dai vincoli di dati di addestramento statici, permettendo loro di offrire interazioni dinamiche, precise e ricche di contesto.
Ricerca sulle Pipeline di Recupero per Chatbot
Le pipeline di recupero svolgono un ruolo fondamentale nei sistemi chatbot moderni, abilitando interazioni intelligenti e contestuali.
“Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” di Pengfei Zhu et al. (2018)
Presenta Lingke, un chatbot che integra il recupero delle informazioni per gestire conversazioni multi-turno. Sfrutta un’elaborazione pipeline avanzata per estrarre risposte da documenti non strutturati e impiega il matching attento contesto-risposta per interazioni sequenziali, migliorando notevolmente la capacità del chatbot di gestire richieste utente complesse.
Leggi il paper qui.
“FACTS About Building Retrieval Augmented Generation-based Chatbots” di Rama Akkiraju et al. (2024)
Esplora le sfide e le metodologie nello sviluppo di chatbot enterprise utilizzando pipeline Retrieval Augmented Generation (RAG) e grandi modelli linguistici (LLM). Gli autori propongono il framework FACTS, che enfatizza Freschezza, Architetture, Costo, Testing e Sicurezza nell’ingegneria delle pipeline RAG. I risultati empirici evidenziano i trade-off tra accuratezza e latenza nella scalabilità dei LLM, offrendo preziosi spunti per la costruzione di chatbot sicuri e performanti. Leggi il paper qui.
“From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” di Subash Neupane et al. (2024)
Presenta BARKPLUG V.2, un sistema chatbot pensato per ambienti universitari. Utilizzando pipeline RAG, il sistema fornisce risposte accurate e specifiche per dominio agli utenti sulle risorse del campus, migliorando l’accesso alle informazioni. Lo studio valuta l’efficacia del chatbot tramite framework come RAG Assessment (RAGAS) e mostra la sua utilità in ambito accademico. Leggi il paper qui.