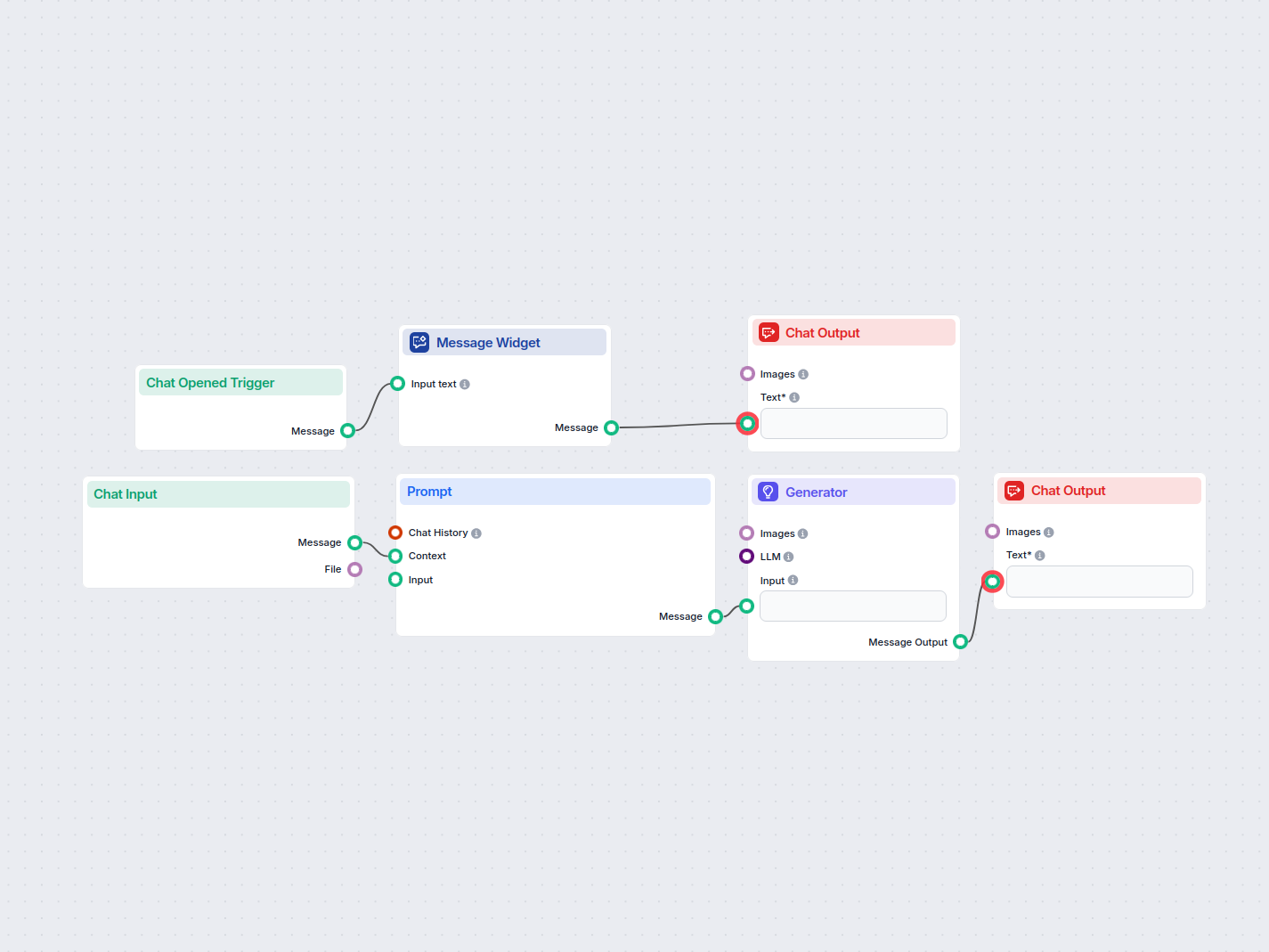
Riassuntore AI dal Testo di Input
Questo strumento è perfetto per professionisti, studenti e chiunque abbia a che fare con grandi quantità di informazioni. Aiuta a trasformare testi lunghi in br...
2 min di lettura
AI
Summarization
+4
Il riepilogo del testo in AI condensa i documenti mantenendo le informazioni chiave, utilizzando LLM come GPT-4 e BERT per gestire e comprendere efficientemente grandi insiemi di dati.
Il riepilogo del testo è un processo essenziale nel campo dell’intelligenza artificiale, volto a distillare documenti lunghi in riassunti concisi preservando le informazioni e il significato fondamentali. Con l’esplosione dei contenuti digitali, questa capacità consente a individui e organizzazioni di gestire e comprendere in modo efficiente grandi quantità di dati senza dover esaminare testi molto estesi. I Modelli Linguistici di Grandi Dimensioni (LLM), come GPT-4 e BERT, hanno notevolmente migliorato questo settore grazie a sofisticate tecniche di elaborazione del linguaggio naturale (NLP) per generare riassunti coerenti e accurati.
Riepilogo Astrattivo:
Genera nuove frasi che racchiudono le idee principali del testo sorgente. A differenza del riepilogo estrattivo, che seleziona frammenti di testo esistenti, il riepilogo astrattivo interpreta e riformula i contenuti, producendo riassunti che imitano la scrittura umana. Ad esempio, può condensare risultati di ricerca in dichiarazioni fresche e sintetiche.
Riepilogo Estrattivo:
Seleziona e combina frasi o espressioni significative dal testo originale in base a metriche come frequenza o importanza. Mantiene la struttura originale ma può mancare della creatività e fluidità dei riassunti prodotti dall’uomo. Questo metodo preserva con affidabilità l’accuratezza dei fatti.
Riepilogo Ibrido:
Unisce i punti di forza dei metodi estrattivo e astrattivo, catturando informazioni dettagliate e riformulando i contenuti per chiarezza e coerenza.
Riepilogo del Testo con LLM:
Gli LLM automatizzano il riepilogo, offrendo una comprensione simile a quella umana e capacità di generazione di testo per creare riassunti sia precisi che leggibili.
Tecnica Map-Reduce:
Suddivide il testo in blocchi gestibili, riassume ogni segmento e poi integra questi in un riassunto finale. Particolarmente efficace per documenti molto lunghi che superano la finestra di contesto del modello.
Tecnica Refine:
Un approccio iterativo che parte da un riassunto iniziale e lo perfeziona incorporando dati aggiuntivi dai segmenti successivi, mantenendo così la continuità del contesto.
Tecnica Stuff:
Inserisce l’intero testo insieme a un prompt per generare direttamente il riassunto. Sebbene sia diretta, è limitata dalla finestra di contesto dell’LLM e si adatta meglio a testi brevi.
Dimensioni chiave da considerare nella valutazione dei riassunti:
Complessità del Linguaggio Naturale:
Gli LLM devono comprendere idiomi, riferimenti culturali e ironia, che possono portare a interpretazioni errate.
Qualità e Accuratezza:
Garantire che i riassunti riflettano accuratamente i contenuti originali è fondamentale, soprattutto in ambiti come il diritto o la medicina.
Diversità delle Fonti:
Tipi di testo diversi (tecnici vs. narrativi) possono richiedere strategie di riepilogo personalizzate.
Scalabilità:
Gestire efficientemente grandi quantità di dati senza compromettere le prestazioni.
Privacy dei Dati:
Garantire la conformità alle normative sulla privacy durante l’elaborazione di informazioni sensibili.
Aggregazione di Notizie:
Condensa automaticamente gli articoli di notizie per una consultazione rapida.
Riepilogo di Documenti Legali:
Semplifica la revisione di documenti e fascicoli legali.
Sanità:
Riassume cartelle cliniche e ricerche mediche per supportare diagnosi e pianificazione terapeutica.
Business Intelligence:
Analizza grandi volumi di report di mercato e bilanci per decisioni strategiche.
Il riepilogo del testo con Modelli Linguistici di Grandi Dimensioni (LLM) è un campo in rapida evoluzione, guidato dalla quantità enorme di testo digitale oggi disponibile. Quest’area di ricerca esplora come gli LLM possano generare riassunti concisi e coerenti da grandi volumi di testo, sia in modo estrattivo che astrattivo.
Il riepilogo del testo nell'IA si riferisce al processo di condensazione di documenti lunghi in riassunti più brevi, preservando le informazioni e il significato essenziali. Sfrutta tecniche come il riepilogo astrattivo, estrattivo e ibrido utilizzando Modelli Linguistici di Grandi Dimensioni (LLM) come GPT-4 e BERT.
Le tecniche principali sono il riepilogo astrattivo (generare nuove frasi per trasmettere le idee principali), il riepilogo estrattivo (selezionare e combinare frasi importanti dal testo originale), e i metodi ibridi che combinano entrambi gli approcci.
Le applicazioni includono l’aggregazione di notizie, la revisione di documenti legali, il riepilogo di cartelle cliniche e l’intelligence aziendale, consentendo a individui e organizzazioni di elaborare e comprendere grandi insiemi di dati in modo efficiente.
Le sfide includono la gestione della complessità del linguaggio naturale, garantire l’accuratezza e la coerenza del riassunto, l’adattamento a diversi tipi di fonte, la scalabilità su grandi insiemi di dati e il rispetto della privacy dei dati.
Inizia a creare le tue soluzioni AI con gli avanzati strumenti di riepilogo del testo di FlowHunt. Condensa e comprendi facilmente grandi volumi di contenuti.
Questo strumento è perfetto per professionisti, studenti e chiunque abbia a che fare con grandi quantità di informazioni. Aiuta a trasformare testi lunghi in br...
Riassumi facilmente qualsiasi testo inserito in punti chiave concisi utilizzando l'AI. Questo workflow prende l'input dell'utente, genera un breve riassunto e l...
La generazione di testo con i Large Language Models (LLM) si riferisce all'uso avanzato di modelli di machine learning per produrre testo simile a quello umano ...